
大数据可视化从未如此简单 - Apache Zepplien全面介绍
大数据可视化从未如此简单 - Apache Zepplien全面介绍
群主 大数据技术与架构

前言
我们在进入 Apache Zepplien 的学习前,需要了解两个概念:REPL和Jupyter Notebook。
REPL
REPL全称是Read Evaluate Print Loop,交互式解释器环境,通过交互式界面接收用户输入,交互式解释器读取输入内容并对它求值,返回结果,并重复此过程。JShell 是 Java 9 新增的一个交互式的编程环境工具。它允许你无需使用类或者方法包装来执行 Java 语句。它与 Python 的解释器类似,可以直接 输入表达式并查看其执行结果。有兴趣的读者可以自行查询JShell的介绍和用法。
Jupyter Notebook
Jupyter Notebook(早期叫IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。Jupyter Notebook 的是一个Web应用程序,便于创建和共享程序文档,支持实时代码、数学方程、可视化和Markdown语法,常用在数据清理转换、数值模拟、统计建模、机器学习等业务场景。
Zepplien 简介
Apache Zeppelin是一款大数据分析和可视化工具,可以让数据分析师在一个基于Web页面的笔记本中,使用不同的语言,对不同数据源中的数据进行交互式分析,并对分析结果进行可视化的工具。
简单来说,Zeppelin的核心功能就是:通过不同的解释器支持多种语言的repl,并对返回结果进行可视化展示。Zeppelin的设计理念就是通过不同的解释器支持多种语言的REPL,并对返回结果进行可视化展示。
Zeppelin官方网站 http://zeppelin.apache.org/ Github地址 https://github.com/apache/zeppelin 中文文档:https://zeppelin.apachecn.org/#/docs/2
主要功能和特点
可视化交互式数据分析 用户通过可视化界面,交互式地输入指令、代码提交给Zeppelin编译执行。
Notebook管理 用户通过Web页面轻松地实现Notebook应用的增加、修改、运行和删除,支持应用的快速导入导出。
数据可视化 指令、代码提交后Zeppelin返回结果给用户,如果是结构化的数据,Zeppelin提供可视化机制,通过各类图表展示数据,十分方便。
解释器配置 用户可以配置系统内置的Spark、JDBC、Elasticsearch等解释器,支持按组管理解释器、为一个Notebook应用绑定多个解释器。
运行任务管理 用户将Notebook应用提交给Zeppelin运行,也可以停止正在运行的任务。
用户认证 Zeppelin提供完善的用户认证机制。
Notebook应用一键分享 调试完毕的Notebook应用可以提供统一访问的HTTP地址给外部应用访问。

Zepplien 项目结构
Zeppelin一个Web项目,主要使用Java开发,Maven构建。它的语言构成如下: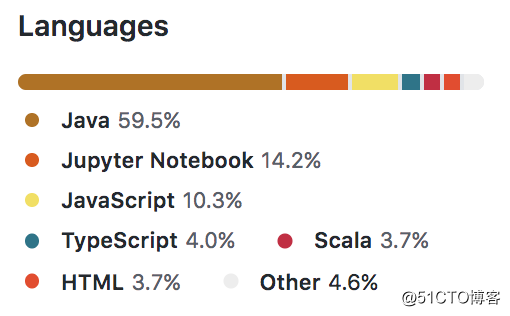
Zeppelin的maven项目由多个module组成,分为框架核心module和其他解释器module。其中核心的module有8个,分别为:
zeppelin-server 项目入口,通过Jetty内嵌服务器提供WebSocekt服务和RESTful服务,并且提供了基本的权限验证服务。使用java编写。
zeppelin-zengine 实现Notebook的持久化和检索服务,使用java编写
zeppelin-interpreter 抽象了interpreter接口,规定了解释器的功能。并且提供了与zeppelin-zengine使用Thrift进行通信的协议。使用java编写。
zeppelin-web 使用AngluarJS框架开发的前端。
zeppelin-display 实现前台Angular元素绑定后台数据。
zeppelin-spark-dependencies 此module中没有代码,具体作用是使用户可以使用zeppelin内嵌的Spark。不过由于Zeppelin支持了太多的解释器,package size过大,已经有人提议在未来的版本中移除此模块,详情见Zeppelin的JIRA:https://issues.apache.org/jira/browse/ZEPPELIN-1332
zeppelin-distribution 此模块主要是为了Zeppelin打包使用
helium-dev 这是在Zeppelin-0.7以后新加入的模块,使interpreter、storage等模块可以在运行时(Zeppelin不需要重启)加入到Zeppelin中。不过目前helium相关的很多功能还处于Experimental阶段,因此不太建议在生产环境中使用。
解释器相关的module众多,根据module的名字可以很容易看出解释器的用途,在此不再赘述。
Apache Zeppelin入门
Apache Zeppelin安装部署
安装包下载地址 https://archive.apache.org/dist/zeppelin/zeppelin-0.8.2/zeppelin-0.8.2-bin-all.tgz
上传安装包并解压
使用远程传输工具将安装包zeppelin-0.8.2-bin-all.tgz上传到服务器上并解压
tar -zxvf zeppelin-0.8.2-bin-all.tgz
我们可以在Zeppelin不用做任何配置修改的情况下即可正常启动。进入bin目录下,执行启动命令
./zeppelin-daemon.sh start 如果显示如下结果,则表示启动正常 Zeppelin start [ OK ] Zeppelin默认的Web访问端口为8080,启动成功后,使用浏览器访问http://ip:8080,即可看到Zeppelin的web界面。
具体的安装过程可以参考官网或者其他博客,相对简单。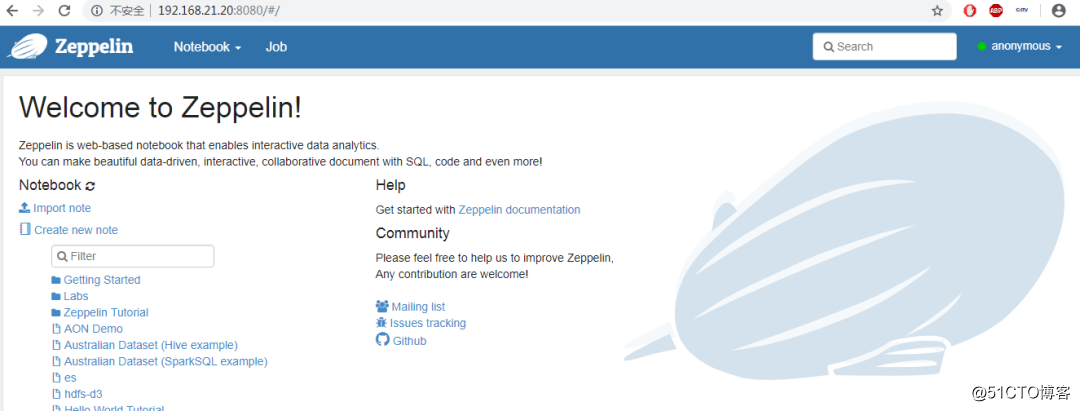
Getting Started with Apache Zeppelin
新建一个Notebook应用 进入Zeppelin主界面,点击Create new note按钮,创建一个新的Notebook应用,命名为/hellozep,并为应用指定解释器为python。当然了,python解释器必须要使用python后台程序支持,如果系统没有安装python,会报错。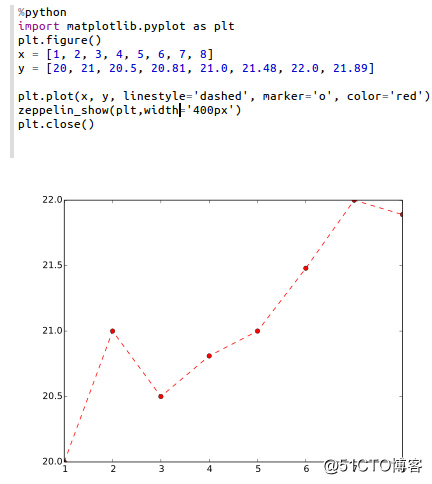
Zepplien 连接 JDBC
Zeppelin通过JDBC支持对PostgreSQL、Mysql、Mariadb、Apache Drill、Amazon Redshift、Apache Tajo等数据库的操作,Zeppelin默认支持的数据库为PostgreSQL。需要特别注意的是,大数据组件Hive、Phoenix也以JDBC方式支持。
我们新建一个JDBC的解释器,首先,+ Create在解释器设置页面的右上角单击按钮。
Interpreter name用任何你想要用作别名的填充字段(如mysql,mysql2,hive,redshift等)。请注意,此别名将用于%interpreter_name在段落中调用解释器。然后选择jdbc为Interpreter group。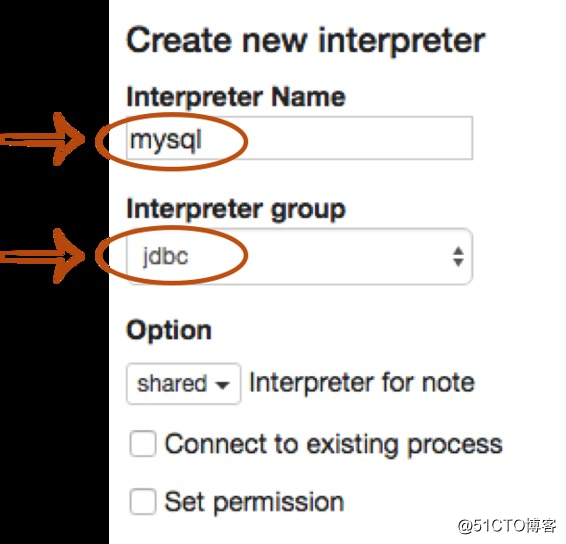
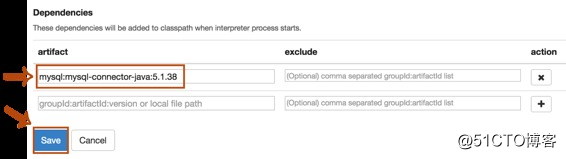
我们按照mysql数据库的配置修改以下属性,接下来为mysql解释器添加对应的mysql驱动,完成后保存配置。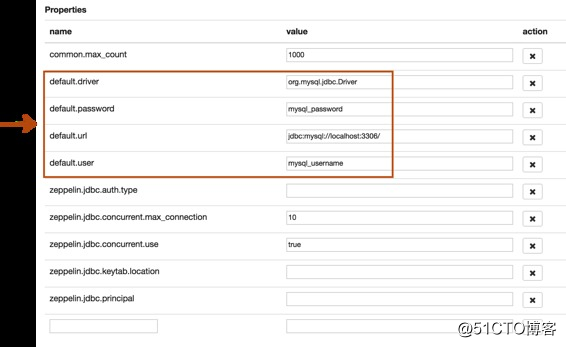
新建一个Notebook应用,命名为mysql,并为其指定默认解释器mysql,进入notebook页面,在第一个Paragraph中依次进行创建库、切换库、创建表和插入记录操作,编辑代码运行。
%jdbc_interpreter_nameshow databases
如果段落FINISHED没有任何错误,我们就可以愉快的使用Mysql的各种语句了,jdbc解释器支持所有CRUD操作语句的解释。
Zepplien 连接 Spark
运行Zeppelin自带的Basic Features (Spark)案例。本案例以银行分析数据bank.csv为例。在此之间我们要配置一下 Spark的环境:在conf/zeppelin-env.sh,设置SPARK_HOME环境变量和安装路径。
export SPARK_HOME=/usr/lib/spark# set hadoop conf direxport HADOOP_CONF_DIR=/usr/lib/hadoop# set options to pass spark-submit commandexport SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0"# extra classpath. e.g. set classpath for hive-site.xmlexport ZEPPELIN_INTP_CLASSPATH_OVERRIDES=/etc/hive/conf
加载数据集
val bankText = sc.textFile("bank.csv")case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")SQL统计
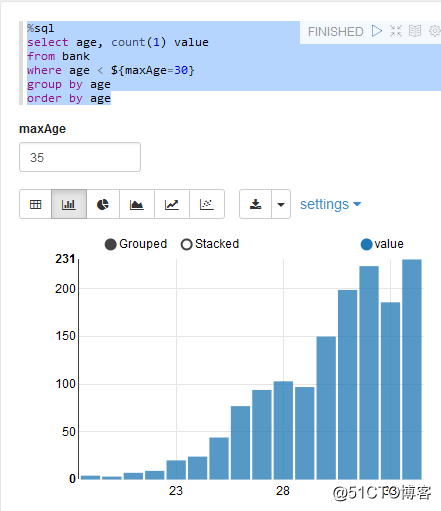
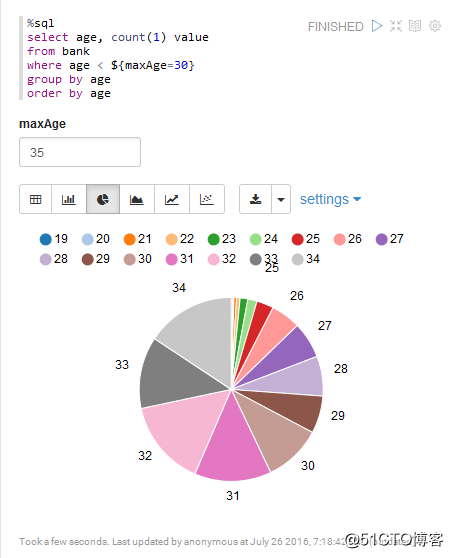
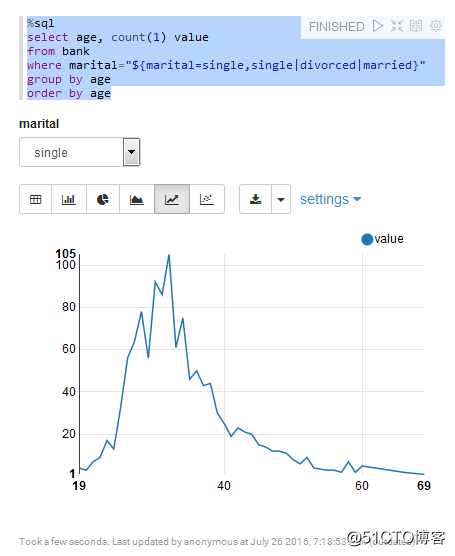
Zepplien 连接 Flink
同理我们需要先做一些环境配置,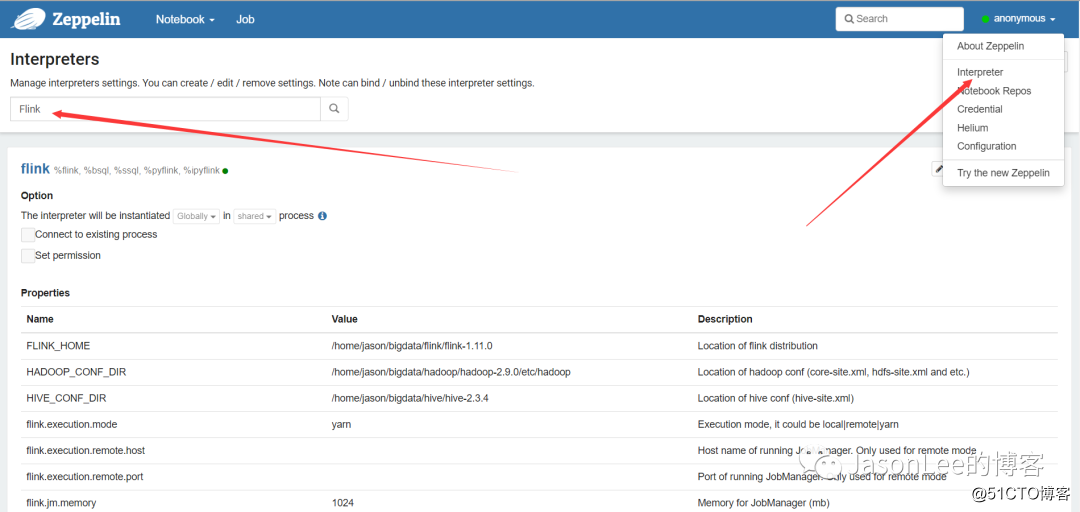
点击右上角的Interpreters进入配置页面,有很多Flink相关的配置,我们直接单击Edit进行配置。
我们跑一个基本的demo任务:
%flinkcase class WordCount(word: String, frequency: Int)
val bible:DataSet[String] = benv.readTextFile("10.txt.utf-8")
val partialCounts: DataSet[WordCount] = bible.flatMap{
line => """\b\w+\b""".r.findAllIn(line).map(word => WordCount(word, 1))// line.split(" ").map(word => WordCount(word, 1))}
val wordCounts = partialCounts.groupBy("word").reduce{
(left, right) => WordCount(left.word, left.frequency + right.frequency)
}
val result10 = wordCounts.first(10).collect()点击右上角的FLINK JOB标记,可以打开作业的Web UI。Zepplin对Flink的支持还包括Batch、Streaming、SQL等,大家可以去尝试。
©著作权归作者所有:来自51CTO博客作者mob604756e85b28的原创作品,如需转载,请注明出处,否则将追究法律责任