
面板数据中标准误的估计方法, 你确定用对了吗? 我们来比较一番!
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
关于标准误,可以参看:1.回归标准误比R2更好,在拟合优度度量方面,2.啥时候使用聚类标准误, 以及数据聚类的修正方法? 3.在什么级别上标准误聚类, 个体, 县, 省或行业, 时间?
正文
关于下方文字内容,作者:吴欣霓,英国牛津大学经济系,通信邮箱:xinniwu@outlook.com.
Mitchell A. Petersen, Estimating Standard Errors in Finance Panel Data Sets: Comparing Approaches, The Review of Financial Studies, Volume 22, Issue 1, January 2009, Pages 435–480, https://doi.org/10.1093/rfs/hhn053
In corporate finance and asset pricing empirical work, researchers are often confronted with panel data. In these data sets, the residuals may be correlated across firms or across time, and OLS standard errors can be biased. Historically, researchers in the two literatures have used different solutions to this problem. This paper examines the different methods used in the literature and explains when the different methods yield the same (and correct) standard errors and when they diverge. The intent is to provide intuition as to why the different approaches sometimes give different answers and give researchers guidance for their use.
在公司财务和资产定价的实证工作中,研究人员经常会面临面板数据(panel data)。众所周知, 当残差(residuals)在企业或年份之间相关时,OLS和怀特标准误差是存在偏差的。Petersen的这篇文章意在比较不同的标准差估算方法,说明不同方法的相对精度显著取决于数据的结构, 为正确估计标准误差提供了指导, 且帮助研究人员诊断其模型中的潜在问题。
本文主要讨论两种形式的依赖性:
1.时间序列依赖性/企业效应(firm effect), 指一个特定企业的残差跨时间相关。2.横截面依赖性/时间效应(time effect), 指特定一个年份的残差跨不同企业相关。其中企业效应还分为固定企业效应(fixed firm effect)和不固定企业效应(temporary firm effect)。不固定企业效应的强度会随着时间增长而变弱。
根据这两种形式的依赖性,本文模拟了四种数据结构:1. 存在固定企业效应的面板数据;2. 存在时间效应的面板数据; 3.同时存在固定企业效应和时间效应的面板数据;4. 存在不固定企业效应的面板数据。在不同数据结构下,作者比较了聚类标准误差、Fama-MacBeth (FM)、Newey-West (NW) 以及 OLS、怀特五种估算标准差的方法, 并简单介绍了GLS 随机效应模型在增加估计系数效率、减少估算标准误差问题上的应用。
在本文的最后,作者把以上几种估计标准误的技术应用到了两个不确定数据结构的真实面板数据集上,演示了如何比较不同的估计标准误差的方法,证实了某些已发表论文所使用的方法可能早造成了偏差较大的标准误差估计,并概括了从不同的标准误差估计中初步判断数据结构的办法。
1. 存在固定企业效应(fixed firm effect)时的标准误差估计
1.1 聚类标准误差估计
模拟的面板数据集里包含对不同公司(i)跨不同年份(t)的观察结果。
标准回归为:
当残差独立且均匀分布且其余OLS假设都被满足时, OLS标准误差公式是正确的。
OLS估计的估计为: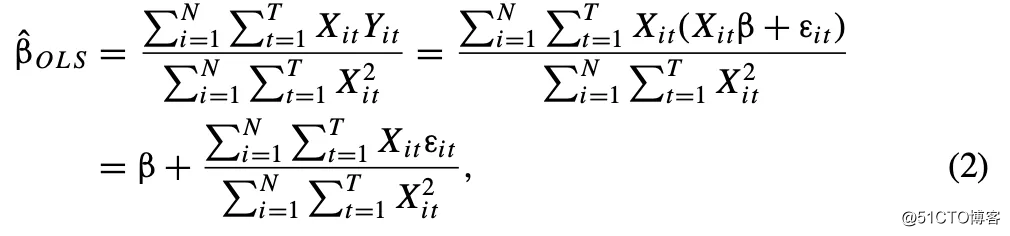

1.2 通过模拟数据测试比较OLS和聚类标准误的估计
本文共模拟了五千个包含企业效应面板数据集,每个数据集包含五百家公司,每家公司十年。真实斜率系数为1,自变量的标准误差为1,惨差项的标准误差为2。
表1包含了基于企业效应的面版数据集的OLS系数和OLS及聚类标准误差的估计值:
由公司固定成分引起的X的波动率[Var(μ)/ Var(X)],在表格的各列中从0%(无企业效应)变化到75%。由公司固定成分引起的的波动率[Var(γ)/ Var(ε)],在表的各行中从0%(无企业效应影响)变化到75%。每个像元包含通过OLS估算的平均斜率系数(第一项)和该估算值的标准偏差(第二项)。这是估计系数的真实标准误差。第三项是OLS估计的平均标准误差。在方括号中报告了在1%的水平上显着的OLS t 统计量百分比(| t |> 2.58)。第五项是按公司聚类的平均标准误(即考虑同家公司在不同年份的观察值之间可能的相关性)。第六项方括号中报告了在1%的水平上显着的聚类t统计量的百分比。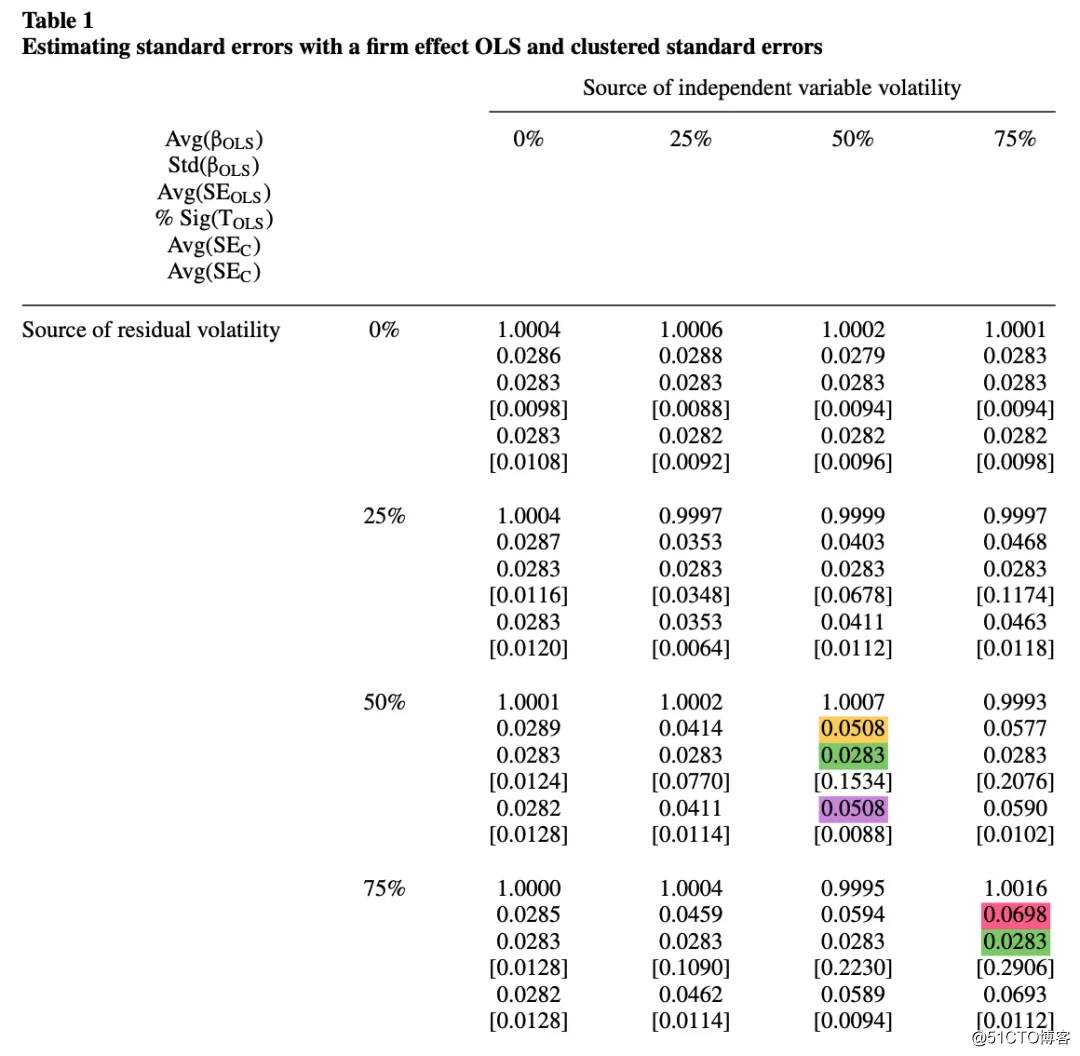
根据表1可以看出,如果残差没有企业效应(即残差在各个观测值之间是独立的),则OLS估计的标准误是正确的(表1,第1行)。如果自变量没有企业效应(即自变量在各个观察值之间是独立的),则即使残差之间高度相关(表1第1列),OLS估计的标准误也将是无偏的。如果企业效应同时存在于残差和自变量中,则OLS估计的标准误较真实的标准误偏低。举例说明,当图片时, OLS估计的标准误为0.0283 (标绿),低估了近一半的正确的标准误(标黄,0.0508)。
而当使用聚类标准误估算系数的标准误差时, 估计值(每个单元格中的第五个条目)非常接近真实的标准错误。举例说明,当图片时, 聚类标准误估计值为0.0508(标紫),和正确的标准误一致(标黄,0.0508)。这些估计随着真实标准误差的增加而增加,这是由企业效应引起的可变性所占比例增加所致。因此,在有企业效应的情况下, 聚类标准误差正确地解释了面板数据集中常见数据的依赖性,并产生了无偏估计。
1.3 Fama-MacBeth (FM) 标准误差估计
在FM标准误估计方法中,研究人员进行了T次截面回归分析。FM系数估计值为T次系数估计的平均值: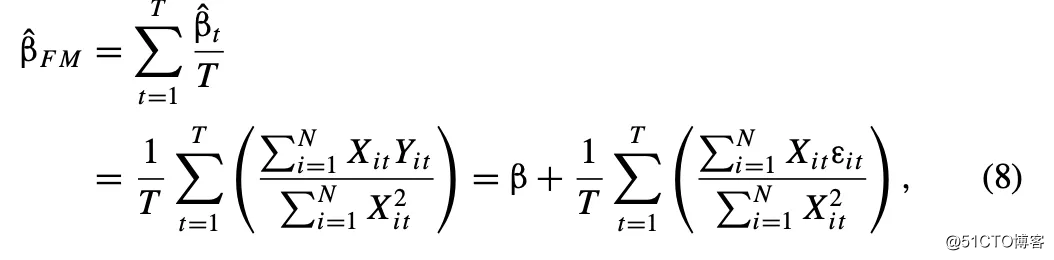
FM估计的估计系数方差为: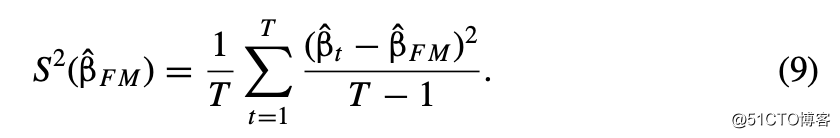
图片1.4 通过模拟数据测试Fama-MacBeth标准误的估计
表2使用了和表1相同的数据集,包含了基于企业效应的面版数据集的系数和标准误的FM估计值: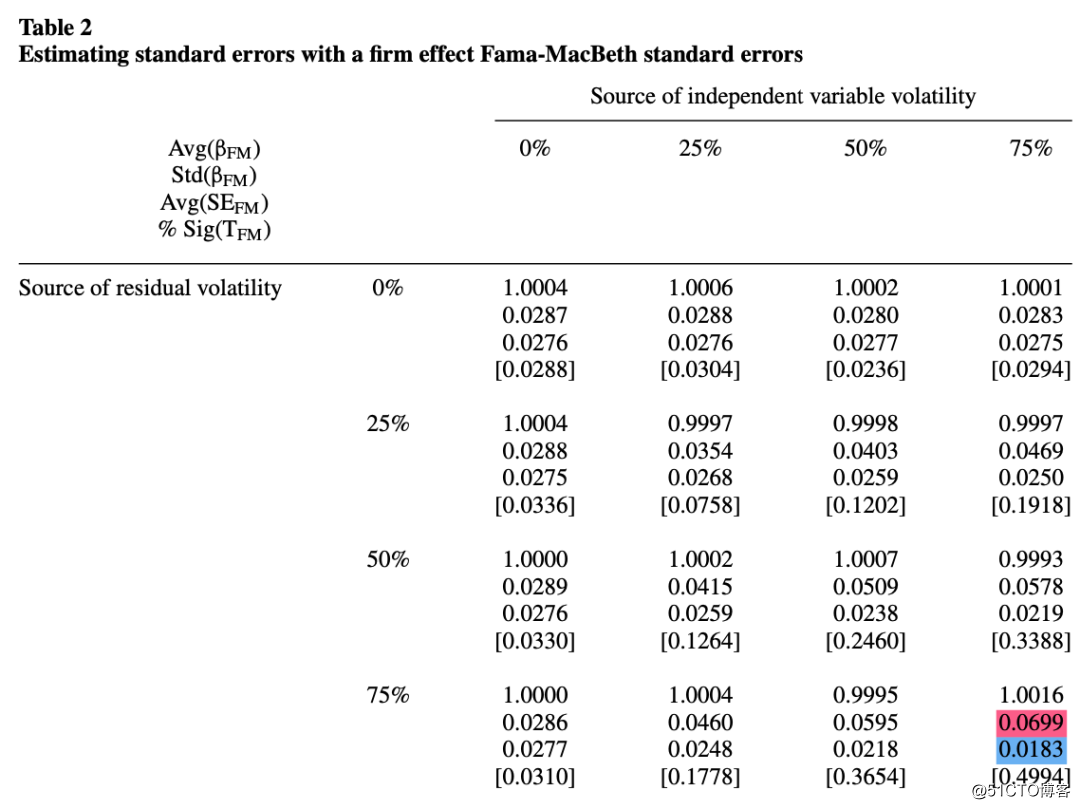
每个像元的第一项是基于FM估计的平均斜率系数。第二项是FM估算的系数的标准误, 即FM系数的真实标准误差。第三项是FM估算的平均标准误差(请参见公式(9))。方括号中报告的是在1%的水平上很显着的FM t 统计量的百分比(| t |> 2.58)。
对比表1,FM的系数和标准误估计值和OLS是一致的,并且与OLS一样有效(两者之间的相关性始终高于0.99)。两个系数估计的标准偏差也相同(比较表1和2中每个单元格的第二个条目)。这些结果表明,OLS和FM标准误差均低估了真实标准误。但是,与OLS标准错误相比,FM标准错误的偏差更大。例如,当图片时,OLS标准误差的偏差为60%(0.595 = 1 − 0.0283 / 0.0698,请参阅表1),而FM标准误差的偏差为74% (0.738 = 1 − 0.0183 / 0.0699,请参阅表2)。
1.5已发表论文中的标准误差估计
尽管FM标准误差存在企业效应的情况下是有偏差的,但它们还是经常在回归可能存在企业效应的情况下,被用于度量已发表论文的统计显着性。FM标准误是被开发用来解释同一年不同公司的观测值之间的相关性,而不是考虑同一年不同公司的观测值之间的相关性的。FM标准误差确实可以用于说明交叉相关性(cross-correlation)(例如,图片之间的相关性), 但是不能用于解释串行相关性(例如,图片之间的相关性)。这是Fama-MacBeth(和OLS)标准错误可能有偏差的数据类型。在本文提及的一些论文里(Fama and French, 2001;Pastor and Veronesi, 2003; Kemsley and Nissim, 2002; Baker and Wurgler, 2002; Fama and French 2002; and Johnson, 2003), 论文作者都对一种持久性企业特征对其他持久性企业特征进行了回归(即变量的序列相关性很大,并且随着观察之间的滞后性的增加而逐渐消失)。
1.6 Newey-West (NW) 标准误差
NW标准误是用来解释单个时间序列中残差间未知的串联相关性的。为了能估算单个时间序列中的自相关作用, NW方法假设当观测值之间的距离达到无穷大时,残差之间的相关性接近零。另外,由于NW过程最初是为单个时间序列设计的,因此必须使用加权函数才能使该矩阵的估计为正半定。NW将延迟(lag) j(例如图片)的协方差乘以权重 [1-j /(M +1)],其中M是指的是最大延迟。该权重对于相邻的观测值最大,随着观测值之间距离的增加而减小,并逐渐增加到接近1。在面板数据中,最大延迟M=T-1。Newey-West标准误差方差方程的中心矩阵为: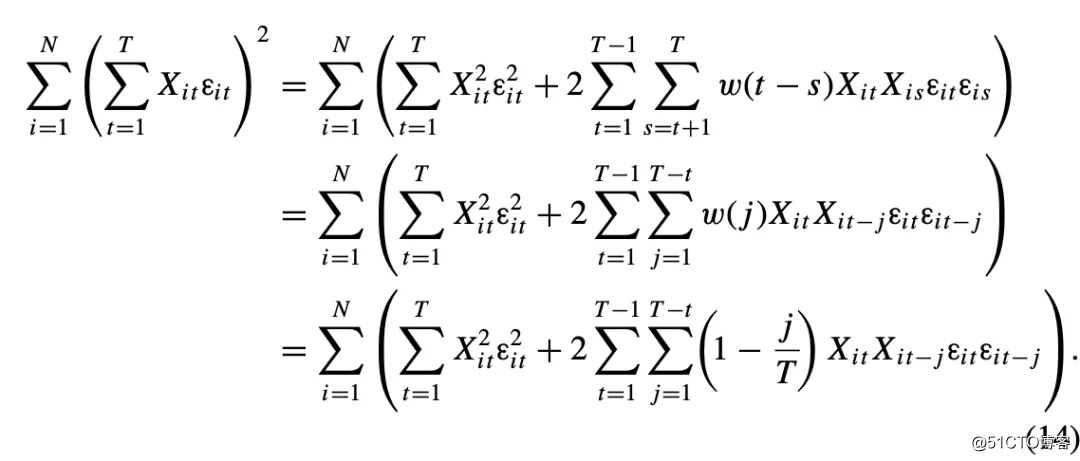
运用和之前相同的存在固定企业效应的面板数据集,当延迟为0, NW标准误估计值和OLS标准误估计值相同(同为0.0283)。当延迟从0增加到9(M=T-1=10-1=9), NW标准误估计值从0.0283增长到0.0328, 但还是低于真实标准误。由于面板数据集中存在多个时间序列,标准误方差方程的中心矩阵不需要通过加权函数来实现正半定。因此,当数据中存在固定企业效应时,即使最大延迟M=T-1, 用NW估计的标准误依旧偏低8%。(NW估计值的偏差比OLS和FM估计值的偏差小。)
2. 存在时间效应(Time Effect)时的标准误差估计
2.1 聚类标准误差估计
为了演示不同标准误估计方法在存在时间效应的情况下的表现,本文生成了仅包含时间效应的数据集(将同一年内不同公司的观察结果进行了关联)。这也正是为Fama-MacBeth方法设计的数据结构(请参阅Fama和MacBeth,1973)。
模拟的面板数据结构如下:
本文共模拟了五千个包含时间效应面板数据集,每个数据集包含五百家公司,每家公司十年。真实斜率系数为1,自变量的标准误差为1,惨差项的标准误差为2。
表3包含了基于时间效应的面版数据集的OLS系数和标准误以及聚类标准误差的估计值: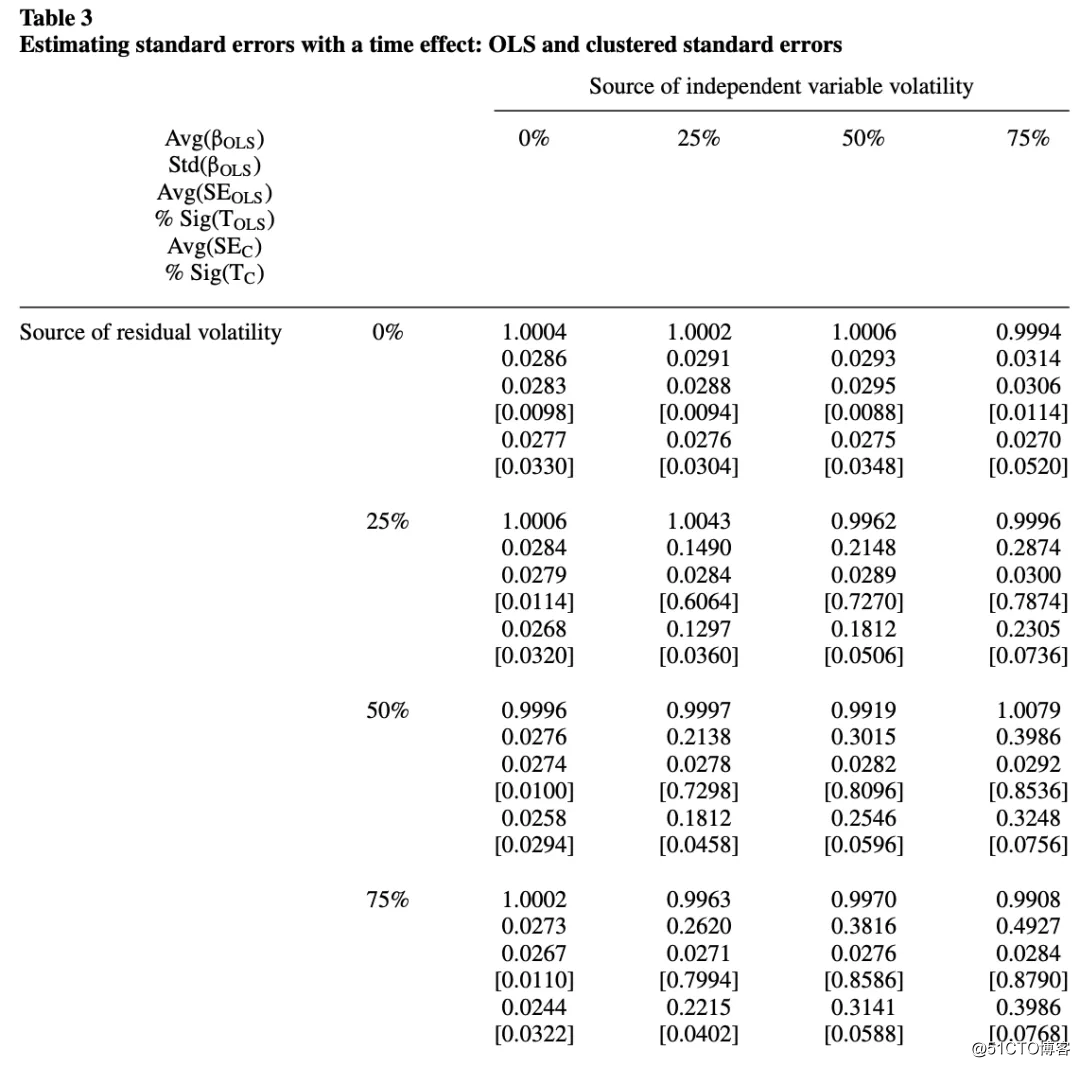
由表三可得出以下几个结论:
当自变量或/和残差不存时间效应时,OLS标准误估计是正确的。
随着时间效应强度增加,OLS标注误低估正确标准误的程度增加。
对比OLS,聚类标准误估计值虽然准确很多,但较正确标准误还是偏低。偏差是由于此模拟数据集中只有10个时间簇(T=10), 远小于之前企业效应数据中但500个公司簇。为了探索簇数对聚类标准误估计准确度的影响,本文模拟了五千个观测值的数据集,其年数(或类集)的范围为5到100。在所有模拟中,自变量和残差的25%的变异性都来自时间效应(图片)。聚类标准误差估计中的偏差随聚类数目的减少而降低,从T=5的27%降至T=40的3%,降至T=100的1%。
2.2 Fama-MacBeth (FM) 标准误差估计
表4包含了基于时间效应的面版数据集的系数和标准误的FM估计值: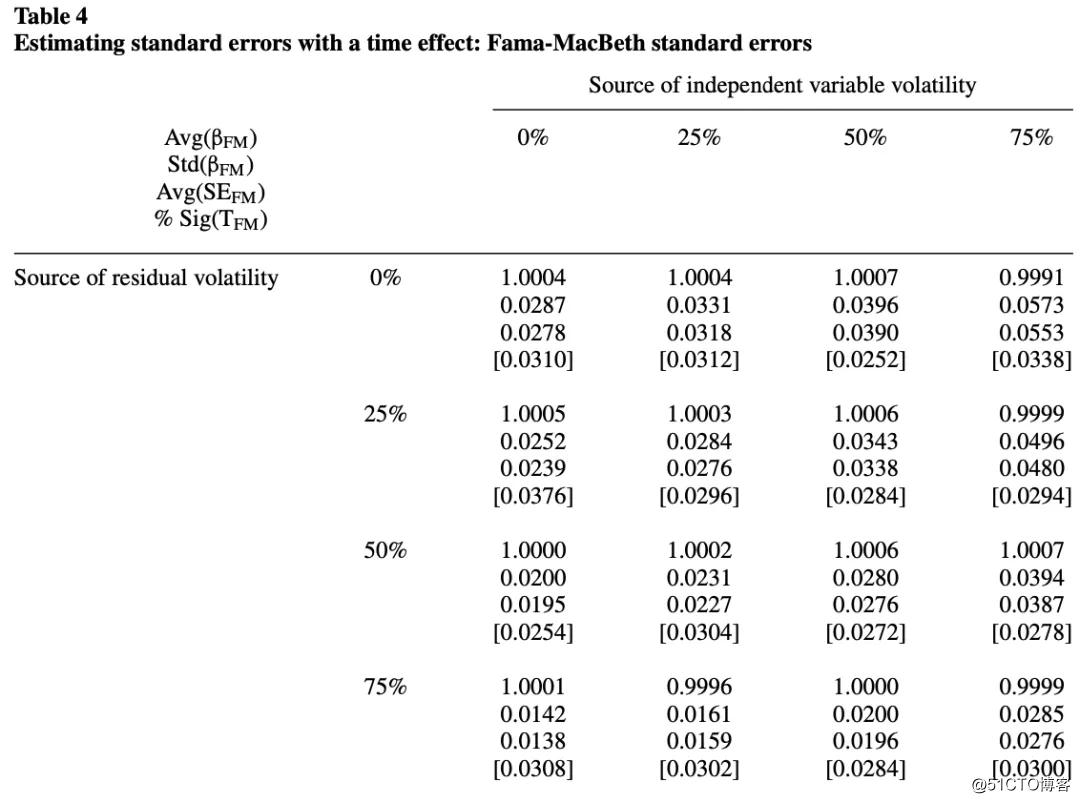
由表四可得出以下结论:当只有时间效应时,不同年份的估计斜率系数之间的相关性为零。因此, FM估计的标准误不存在偏差(请参照公式(12))。
存在企业效应(Firm Effect)和时间效应(Time Effect)时的标准误差估计
根据之前的分析,当数据中仅存在企业效应时,以公司聚类的标准误是无偏的。当数据中仅存在时间效应时,FM估计的标准误和以年份聚类的标准误(在年份数足够大的前提下)是无偏的。当两种效应同时存在时,经验金融研究人员可以通过两种方法解决相关性问题。
方法一:通过参数方式估计其中一个维度(例如,通过包含虚拟变量)。由于许多面板数据集的公司数量超过年份数,因此一种通用的方法是在每个时间段都包含虚拟变量(以吸收时间效应),然后按公司进行聚类(Lamont和Polk,2001;Anderson和Reeb,2004;Gross和Souleles,2004;Sapienza,2004;以及Faulkender和Petersen,2006)。如果时间效应是固定的(例如,公式(15)),则时间虚拟变量将完全消除同一时间段内观测值之间的相关性。在这种情况下,数据中只剩下固定企业效应,因而可以使用以公司聚类的标准误。而当数据中还存在不固定企业效应时,以公司聚类的标准误也可能存在偏差。
方法二:由于研究人员并不总是知道依赖关系的确切形式,另一种解决方案是同时在两个维度上聚类(例如,公司和时间)。Cameron,Gelbach和Miller(2006)和Thompson(2006)提出了方差-协方差矩阵的以下估计: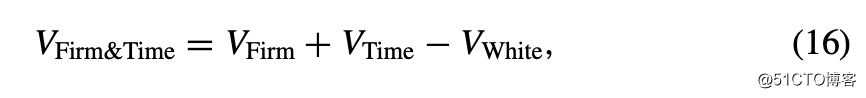
由于公司集群和时间集群方差协方差矩阵都包含方差协方差矩阵的对角线,为了避免重复计算,怀特方差协方差被减去了。为了说明按公司,年份或这两者进行聚类的标准误差的性能,本文模拟了具有固定公司和时间效应的9个数据集,其中公司数量和时间段的范围从10到1000,因此观察的总数始终为10000(250家公司和40个时间段,请参见图7)。假定 Var(γ) = Var(δ) = Var(η) and Var(μ) = Var(ζ) = Var(ν),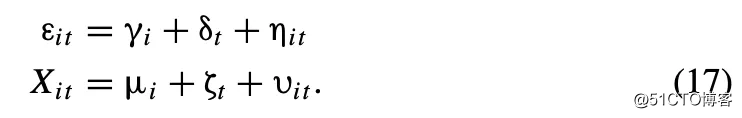
图7:在企业效应,时间效应独自和同时存在的情况下按公司、时间或同时按两者进行聚类的t统计量的拒绝率 (| t |> 2.58)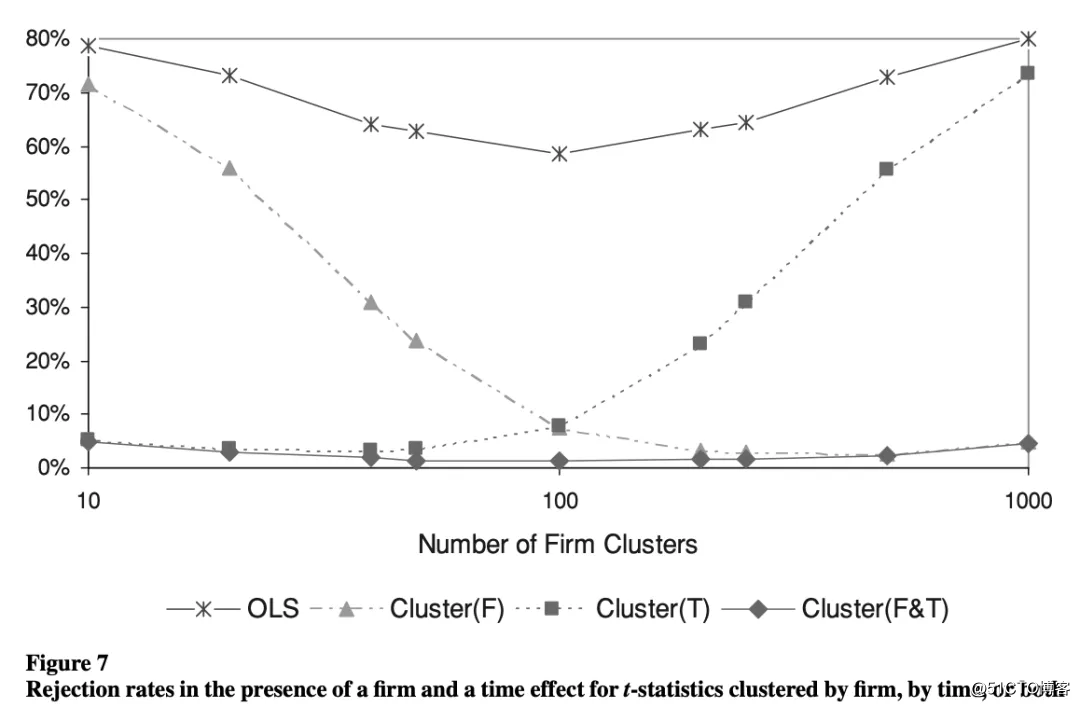
相较于单独按公司、时间聚类,二维聚类能产生偏差较少的标准误差。但是,按公司和时间进行聚类并不总是能产生无偏估计。当有一百家公司一百年时,t统计量的1%大于2.58。随着聚类数目(公司或年份)的减少,由公司和时间聚类的标准误差有偏差,尽管偏差的幅度并不大。有关其他结果,请参见Cameron,Gelbach和Miller,2006;Thompson,2006)。当在一维中的聚类数量较少时,通过数量更多的聚类产生的聚类结果几乎与同时在公司和时间上聚类的结果相同。例如,在使用一千家公司和十年数据的模拟中,无论标准误是单按公司还是同时按公司和时间进行聚类,大于2.58的t统计量的百分比均为5%(图7)。
4.在存在不固定(临时)企业效应的情况下估计标准误差
4.1 数据结构
本文模拟了既包含固定企业效应又包含临时企业效应的数据结构, 并假定其为一阶自回归过程
(AR(1))过程。这使得临时企业效应以一阶自回归衰减和零之间的比率消失。残差的非企业性影响部分为( 图片来自公式(4)):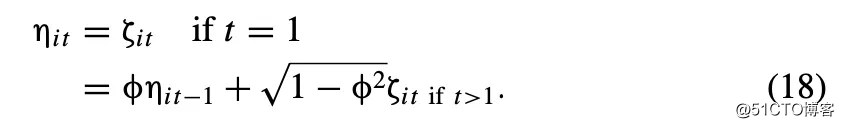
φ是图片之间的一阶自相关。通过选择固定企业效应图片和一阶自相关(φ)的相对大小,可以更改残差中自相关的模式。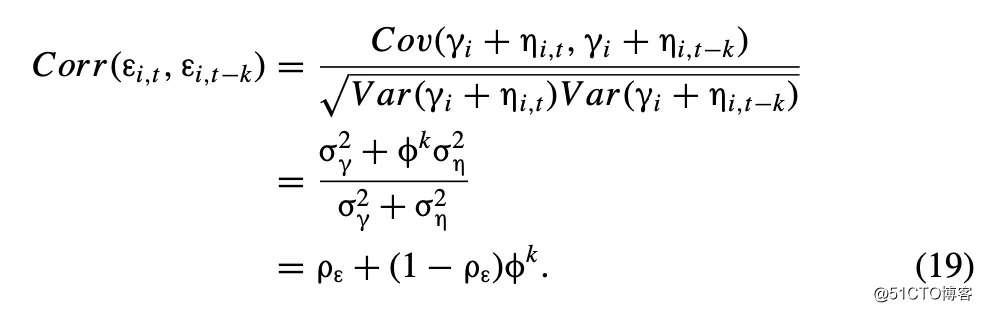
4.2 随机效应模型的广义最小二乘估计(GLS)
当面板回归的残差相关时,不仅OLS标准误差估计值有偏差,而且系数估计值也无效(估计值不会利用数据中的所有信息)。研究人员可以通过使用GLS方法估算随机效应模型来提高效率。在本文的调查中, 不到3%的论文使用了这种方法(例如,参见Maksimovic和Phillips,2002;Gentry,Kemsley和Mayer,2003;Almazan等,2004)。当残差相关时,GLS估计比OLS估计更有效。但是,只有当企业效应是永久性的时,GLS产生的标准误差才是正确的。当残差相关但相关性消失时,GLS系数估计仍比OLS估计更有效,但标准误差不再无偏见。与OLS标准误差一样,尽管偏差的幅度较小,但GLS标准误差也太小。因此,即使使用GLS,也有必要估算由公司聚类的标准误差。
4.3 校正后的Fama-MacBeth 标准误差(Adjusted FM)
如第1节所示,企业效应导致FM标准误估计值偏小。建议校正FM标准误是为了估算年度系数估计值之间的相关性(即Corr [βt,βt-1] =θ),然后将估计的方差乘以(1 +θ)/(1-θ)来解释 β 之间的序列相关性(Chakravarty, Gulen, Mayhew, 2004;and Fama and French, 2002)。由于平均一阶自相关为负,因此校正后的Fama-MacBeth标准误差比未校正标准误差有更大的偏差。当残差中存在自回归分量时,或当企业效应固定时,校正后的FM标准误会比没校正的FM标准误更准确。当残差中同时存在固定和非固定企业效应时,校正后的FM标准误依旧存在偏差,但是偏差显著小于没校正的标准误。当数据中存在足够多的周期(年份),且非固定企业效应很快随时间消失时,校正后的FM标准误性能最好。
5.实证应用
本节将几种用于估计标准误差的技术应用于两个实际数据集。首先使用OLS估算回归,然后使用怀特标准误差以及按公司,时间和两者聚类的标准误差进行报告(表6和7,第I–IV列)。通过使用怀特标准错误作为基准,列之间的差异仅归因于群集内相关性,而不是异方差。如果按公司聚类的标准误差与怀特标准误差显着不同,则数据中会产生显着的企业效应。然后使用Fama-MacBeth(表6和7,第V列)估算斜率系数和标准误差,且每个OLS回归都包含时间虚拟变量。
5.1 资产定价的实证应用
(Daniel and Titman, 2006, “Market Reactions to Tangible and Intangible Information”)
为了证明股本发行对未来股本回报的影响,Daniel 和Titman 将滞后账面市价比的年值,账面和市场价值的历史变化以及公司股票发行量度的月度回报进行了回归。该回归的问题在于变量是基于每个月的数据,而自变量则都是基于每年的数据。因而自变量很有可能跨时间相关。
表6包含了用不同方法估计的系数极其标准误。在表6和表7中,I–IV列中的估计值是OLS系数,并且回归包含时间(月)虚拟值。标准误差在括号中报告。I:怀特标准误差; II: 按公司聚类的标准误;III:按月份聚类的标准误;IV: 按按企业和月份聚类的标准误。第五列包含由Fama-MacBeth估算的系数和标准误差。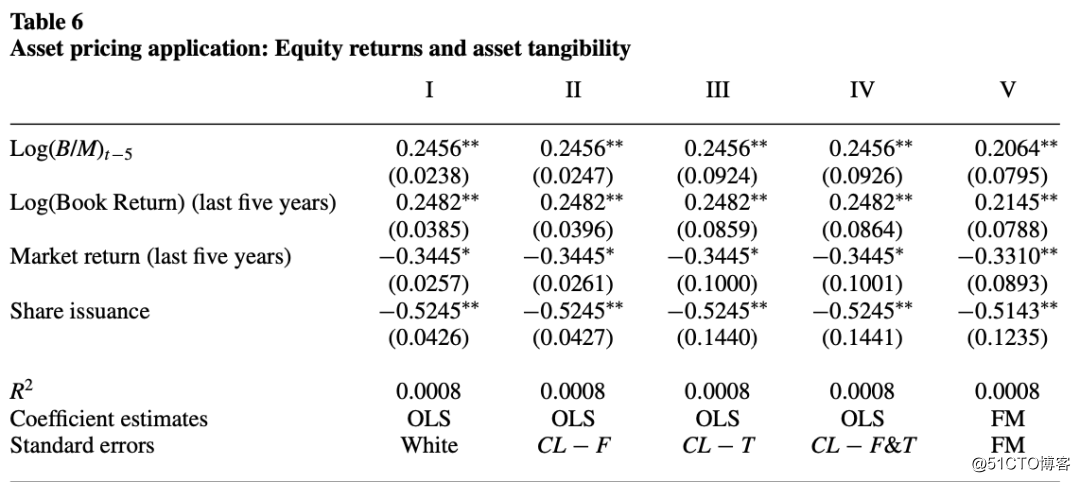
通过检查标准误差在按公司或时间进行聚类时的变化方式(即比较I-II列和I-III列, 可以确定残留在残差中的依存关系的性质,这可以为研究人员提供如何改进其误差的指南。按公司和月份进行聚类的标准误差与仅按月份进行聚类的标准误差基本相同(比较表6中的IV和III列)。当每月的公司很少或没有公司影响时,这两个标准误差将接近。假设该数据集每月有很多公司(至少1000家),则结果表明该数据没有明显的公司效应。怀特标准误差与公司所涵盖的标准误差基本相同,而按月聚类的标准误差是怀特标准误差的2至4倍。这意味着即使在包括时间虚拟变量之后,数据中也存在明显的时间效应。根据前文的分析,当仅存在时间效应时,FM标准误估计不存在偏差。根据表6的第V栏中报告, FM系数估计与OLS系数相似,并且标准误差比怀特标准误差(2.0-3.4倍)大得多,这在存在时间效应的情况下是可以预期的。Fama-MacBeth标准误差接近于按时间聚类的标准误差,因为这两种方法都旨在解决时间维度的依赖性。
5.2 公司财务的实证应用
之所以用资本结构回归来进行公司财务的实证应用,是因为因为这是包含重大企业效应的数据。
在构建数据集时,使用了文献中常见的自变量(公司规模,公司年龄,资产有形性和公司盈利能力)。该样本包含在1965-2003年间支付股息的纽约证券交易所公司。自变量相对于因变量滞后一年。结果报告在表7中。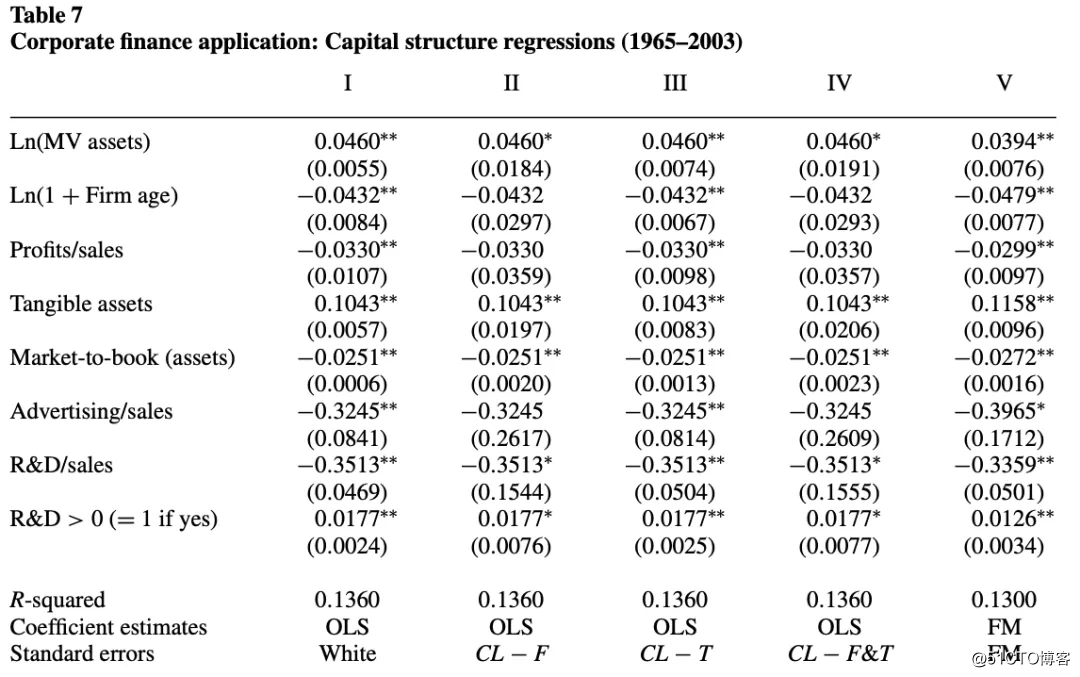
通过比较前四列中的标准误差,可以发现由按公司和月份进行聚类的标准误差与仅按公司进行聚类的标准误差基本相同,而公司聚类的标准误比怀特标准误大得多(大3.1–3.5倍)。例如,关于利润率变量的t统计量基于怀特标准误差为-3.1,基于公司聚类的标准误差为-0.9。这说明了在此数据集中,时间效应(包括了时间虚拟变量后)的重要性很小。怀特和FM的t统计量显着大于公司聚类的t统计量。这证实了上文的结论:在存在固定企业效应的情况下,如在这种资本结构回归中,怀特和FM标准误差明显偏倚。
结论
如果数据存在企业效应,则OLS,White,Newey-West(针对面板数据集进行了修改),Fama-MacBeth或由一阶自相关校正的Fama-MacBeth进行估计时,标准误差均存在偏差。尽管如此,当估计的回归结果具有确定性时,这些方法仍经常在文献中使用。无论企业效应是永久性的(固定的)还是暂时的(非固定的),由企业聚类的标准误差都是无偏的,并会产生正确大小的置信区间。固定效应和随机效应模型也会产生无偏的标准误差,但前提是企业效应是固定的。
在有时间效应的情况下,Fama-MacBeth和按时间聚类的方法会产生无偏的标准错误和正确大小的置信区间, 但前提是存在足够数量的聚类。当群集太少时,即使在正确的维度上聚类,聚类的标准误差也会有偏差。
当数据中同时存在企业效应和时间效应时,研究人员可以通过参数方式解决一个问题(例如,通过包括时间虚拟变量),然后估算聚集在另一个维度上的标准误差。或者,研究人员可以在多个维度上进行聚类。当每个维度上都有足够数量的聚类时,无论多维数据集上的标准误差是永久影响还是永久影响,都不会偏向于多个维度的标准误差,并且会产生正确大小的置信区间。
判断真实数据集中是否存在企业效应和时间效应的方法如下:当按公司聚类的标准误差比怀特标准误差大得多(大3到4倍)时,表明数据中存在企业效应(表7)。当按时间聚类的标准误差比白色标准误差大得多(大2到4倍)时,表明数据中存在时间效应(表6)。当按公司和时间进行聚类的标准误差远大于仅按一个维度进行聚类的标准误差时,这可以表明数据中同时存在公司和时间效应。
References
Almazan, A., K. Brown, M. Carlson, and D. A. Chapman. 2004. Why Constrain Your Mutual Fund Manager? Journal of Financial Economics 73:289–321.
Anderson, R., and D. Reeb. 2004. Founding-Family Ownership and Firm Performance: Evidence from the S&P 500. Journal of Finance 58:1301–28.
Andrews, D. W. K. 1991. Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation. Econometrica 59:817–58.
Arellano, M. 1987. Computing Robust Standard Errors for Within-Groups Estimators. Oxford Bulletin of Eco- nomics and Statistic 49:431–3.
Baker, M., J. Stein, and J. Wurgler. 2003. When Does the Market Matter? Stock Prices and the Investment of Equity-Dependent Firms. Quarterly Journal of Economics 118:969–1005.
Baker, M., and J. Wurgler. 2002. Market Timing and Capital Structure. Journal of Finance 57:1–32.
Bakshi, G., N. Kapadia, and D. Madan. 2003. Stock Return Characteristics, Skew Laws, and the Differential Pricing of Individual Equity Options. Review of Financial Studies 16:101–43.
Bertrand, M., E. Duflo, and Sendhil Mullainathan. 2004. How Much Should We Trust Differences-in-Differences Estimates? Quarterly Journal of Economics 119:249–75.
Bloomfield, R., M. O’Hara, and G. Saar. 2006. The Limits of Noise Trading: An Experimental Analysis. Working Paper, Cornel University.
Brockman, P., and D. Chung. 2001. Managerial Timing and Corporate Liquidity: Evidence from Actual Share Repurchases. Journal of Financial Economics 61:417–48.
Cameron, A. C., J. B. Gelbach, and D. L. Miller. 2006. Robust Inference with Multi-Way Clustering. Working paper, University of California-Davis.
Chakravarty, S., H. Gulen, and S. Mayhew. 2004. Informed Trading in Stock and Option Markets. Journal of Finance 59:1235–57.
Chen, J., H. Hong, and J. Stein. 2001. Forecasting Crashes: Trading Volume, Past Returns, and Conditional Skewness in Stock Prices. Journal of Financial Economics 61:345–81.
Cheng, S., V. Nagar, and M. Rajan. 2005. Identifying Control Motives in Managerial Ownership: Evidence from Antitakeover Legislation. Review of Financial Studies 18:637–72.
Choe, H., B. Kho, and R. M. Stulz. 2005. Do Domestic Investors Have an Edge? The Trading Experience of Foreign Investors in Korea. Review of Financial Studies 18:795–829.
Christopherson, J., W. Ferson, and D. Glassman. 1998. Conditioning Manager Alphas on Economic Information: Another Look at the Persistence of Performance. Review of Financial Studies 11:111–42.
Cochrane, J. 2001. Asset Pricing. Princeton, NJ: Princeton University Press.Coval, J., and Tyler Shumway. 2005. Do Behavioral Biases Affect Prices. Journal of Finance 60:1–34.
Daniel, K., and S. Titman. 2006. Market Reactions to Tangible and Intangible Information. Journal of Finance 61:1605–43.
Denis, D., D. Denis, and K. Yost. 2002. Global Diversification, Industrial Diversification, and Firm Value. Journal of Finance 57:1951–79.
Doidge, C. 2004. U.S. Cross-Listings and the Private Benefits of Control: Evidence from Dual-Class Firms. Journal of Financial Economics 72:519–53.
Donald, S., and K. Lang. 2007. Inference with Difference in Differences and Other Panel Data. Review of Economics and Statistics 89:221–33.
Efron, B., and R. J. Tibshirani. 1986. Bootstrap Measures For Standard Errors, Confidence Intervals, and Other Measures of Statistical Accuracy. Statistical Science 1:54–77.
Fama, E., and J. MacBeth. 1973. Risk, Return and Equilibrium: Empirical Tests. Journal of Political Economy, 81:607–36.
Fama, E., and K. French. 2002. Testing Tradeoff and Pecking Order Predictions about Dividends and Debt. Review of Financial Studies 15:1–33.
Fama, E., and K. French. 2001. Disappearing Dividends: Changing Firm Characteristics or Lower Propensity to Pay? Journal of Financial Economics 60:3–43.
Faulkender, M., and M. Petersen. 2006. Does the Source of Capital Affect Capital Structure? Review of Financial Studies 19:45–79.
Gentry, W., D. Kemsley, and Christopher Mayer. 2003. Dividend Taxes and Share Prices: Evidence from Real Estate Investment Trusts. Journal of Finance 58:261–82.
Graham, J., M. Lemmon, and J. Schallheim. 1998. Debt, Leases, Taxes and the Endogeneity of Corporate Tax Status. Journal of Finance 53:131–62.
Greene, W. 2002. Econometric Analysis. Englewood Cliffs, NJ: Prentice-Hall.
Gross, D., and N. Souleles. 2004. An Empirical Analysis of Personal Bankruptcy and Delinquency. Review of Financial Studies 15:319–47.
Hansen, C. 2007. Asymptotic Properties of a Robust Variance Matrix Estimator for Panel Data When T Is Large. Journal of Econometrics 141:597–620.
Hausman, J. 1978. Specification Tests in Econometrics. Econometrica 46:1251–71.Ibragimov, R., and U. Muller. 2007. T-statistic Based Correlation and Heterogeneity Robust Inference. Working
paper, Harvard University.Jagannathan, R., and Z. Wang. 1998. An Asymptotic Theory for Estimating Beta-Pricing Models Using Cross-
Sectional Regression. Journal of Finance 53:1285–309.Johnson, S. 2003. Debt Maturity and the Effects of Growth Opportunities and Liquidity Risk on Leverage. Review
of Financial Studies 16:209–36.Kayhan, A., and S. Titman. 2007. Firms’ Histories and Their Capital Structures. Journal of Financial Economics.
83:1–32.Kemsley, D., and D. Nissim. 2002. Valuation of the Debt Tax Shield. Journal of Finance. 57:2045–73.
Kezdi, G. 2004. Robust Standard Error Estimation in Fixed-Effects Panel Models. Hungarian Statistical Review 9:95–116.
Lakonishok, J., and I. Lee. 2001. Are Insider Trades Informative? Review of Financial Studies 14:79–111. Lamont, O., and C. Polk. 2001. Does Diversification Destroy Value? Evidence from the Industry Shocks. Journal
of Financial Economics 63:51–77.Liang, K., and Scott Zeger. 1986 Longitudinal Analysis Using Generalized Linear Models. Biometrika. 73:13–22.
MacKay, P. 2003. Real Flexibility and Financial Structure: An Empirical Analysis. Review of Financial Studies. 16:1131–65.
Maksimovic, V., and Gordon Phillips. 2002. Do Conglomerate Firms Allocate Resources Inefficiently Across Industries? Theory and Evidence. Journal of Finance 57:721–67.
Moulton, B. 1986. Random Group Effects and the Precision of Regression Estimates. Journal of Econometrics 32:385–97.
Moulton, B. 1990. An Illustration of a Pitfall in Estimating the Effects of Aggregate Variables on Micro Units. Review of Economics and Statistics 72:334–8.
Nagel, S. 2005. Short Sales, Institutional Investors and the Cross-Section of Stock Returns. Journal of Financial Economics. 78:277–309.
Newey, W., and K. West. 1987. A Simple, Positive Semi-Definite, Heteroscedastic and Autocorrelation Consistent Covariance Matrix. Econometrica 55:703–8.
Pastor, L., and P. Veronesi. 2003. Stock Valuation and Learning about Profitability. Journal of Finance 58:1749– 89.
Pesaran, M. H., and R. Smith. 1995. Estimating Long-Run Relationships from Dynamic Heterogeneous Panels. Journal of Econometrics 68:79–113.
Rogers, W. 1993. Regression Standard Errors in Clustered Samples. Stata Technical Bulletin 13:19–23. Sapienza, P. 2004. The Effects of Government Ownership on Bank Lending. Journal of Financial Economics.
Schultz, P., and T. Loughran. 2005. Liquidity: Urban versus Rural Firms. Journal of Financial Economics 78:341–74.
Skoulakis, G. 2006. Panel Data Inference in Finance: Least-Squares vs. Fama-MacBeth. Working paper, Univer- sity of Maryland.
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
2.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
©著作权归作者所有:来自51CTO博客作者mb5fd86dae5fbf6的原创作品,如需转载,请注明出处,否则将追究法律责任