
HDFS 07 - HDFS 性能调优之 合并小文件
HDFS 07 - HDFS 性能调优之 合并小文件
1 - 为什么要合并小文件
HDFS 擅长存储大文件:
我们知道,HDFS 中,每个文件都有各自的元数据信息,如果 HDFS 中有大量的小文件,就会导致元数据爆炸,集群管理的元数据的内存压力会非常大。
所以在项目中,把小文件合并成大文件,是一种很有用也很常见的优化方法。
2 - 合并本地的小文件,上传到 HDFS
将本地的多个小文件,上传到 HDFS,可以通过 HDFS 客户端的 appendToFile 命令对小文件进行合并。
在本地准备2个小文件:
# user1.txt 内容如下:1,tom,male,16 2,jerry,male,10# user2.txt 内容如下:101,jack,male,19 102,rose,female,18
合并方式:
hdfs dfs -appendToFile user1.txt user2.txt /test/upload/merged_user.txt
合并后的文件内容:

3 - 合并 HDFS 的小文件,下载到本地
可以通过 HDFS 客户端的 getmerge 命令,将很多小文件合并成一个大文件,然后下载到本地。
# 先上传小文件到 HDFS:hdfs dfs -put user1.txt user2.txt /test/upload# 下载,同时合并:hdfs dfs -getmerge /test/upload/user*.txt ./merged_user.txt
下载、合并后的文件内容:
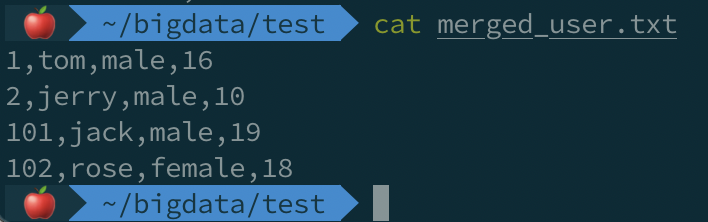
4 - 通过 Java API 实现文件合并和上传
代码如下(具体测试项目,可到 我的 GitHub 查看):
@Testpublic void testMergeFile() throws Exception { // 获取分布式文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop:9000"), new Configuration(), "healchow");
FSDataOutputStream outputStream = fileSystem.create(new Path("/test/upload/merged_by_java.txt")); // 获取本地文件系统
LocalFileSystem local = FileSystem.getLocal(new Configuration()); // 通过本地文件系统获取文件列表,这里必须指定路径
FileStatus[] fileStatuses = local.listStatus(new Path("file:/Users/healchow/bigdata/test")); for (FileStatus fileStatus : fileStatuses) { // 创建输入流,操作完即关闭
if (fileStatus.getPath().getName().contains("user")) {
FSDataInputStream inputStream = local.open(fileStatus.getPath());
IOUtils.copy(inputStream, outputStream);
IOUtils.closeQuietly(inputStream);
}
} // 关闭输出流和文件系统
IOUtils.closeQuietly(outputStream);
local.close();
fileSystem.close();
}合并的结果,和通过命令合并的完全一致:

版权声明
作者:瘦风(https://healchow.com)
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)