
unicode码表转换(数字的unicode编码对比)
计算机运算和存储使用的是二进制数,也就是0和1。这样就需要一套标准,把英文字符对应成二进制数输入到计算机,这样才能被计算机识别。
于是,ASCII码诞生了。

ASCII码
英文名称:(American Standard Code for Information Interchange,美国信息互换标准代码)
起源:ASCII码是鼻祖,在1967年由美国发表规范标准。
前 128位:
一个ASCII字符占用1个字节(8bit)。因此,ASCII编码能够表示的最大字符数是256。事实上美国使用的英文字符就那么几个,所以前128个已足够。这当中包含了控制字符、数字、大写和小写字母和其它一些标点符号。前128个属于强制标准,各国必须遵循,一直沿用至今。
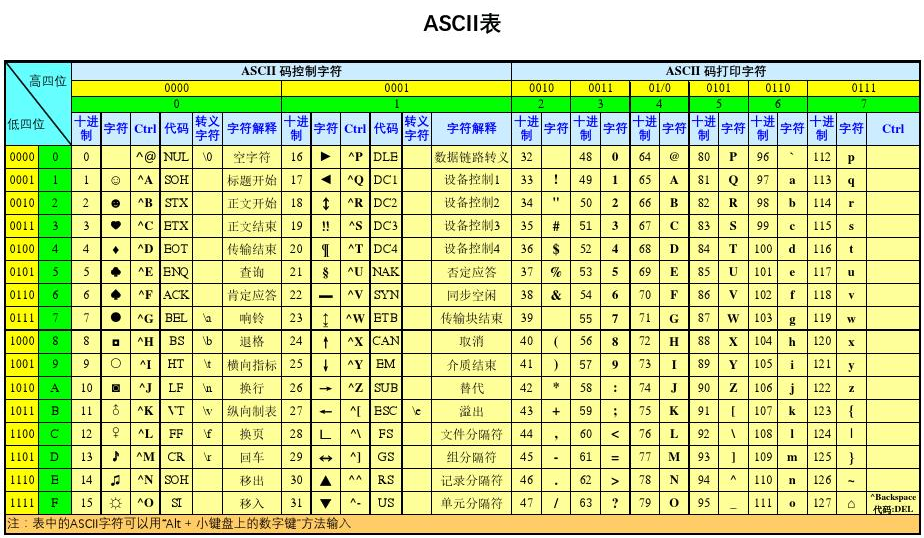
后 128位:
而最高位为1的后128个字符被称为“扩展ASCII码”,属于非强制标准。当时,美国用它来存放英文的制表符、部分音标字符等等的一些其它符号。但是,美国万万没想到是,这后128个“扩展ASCII码”尽成为了其他国家的五花八门之地。
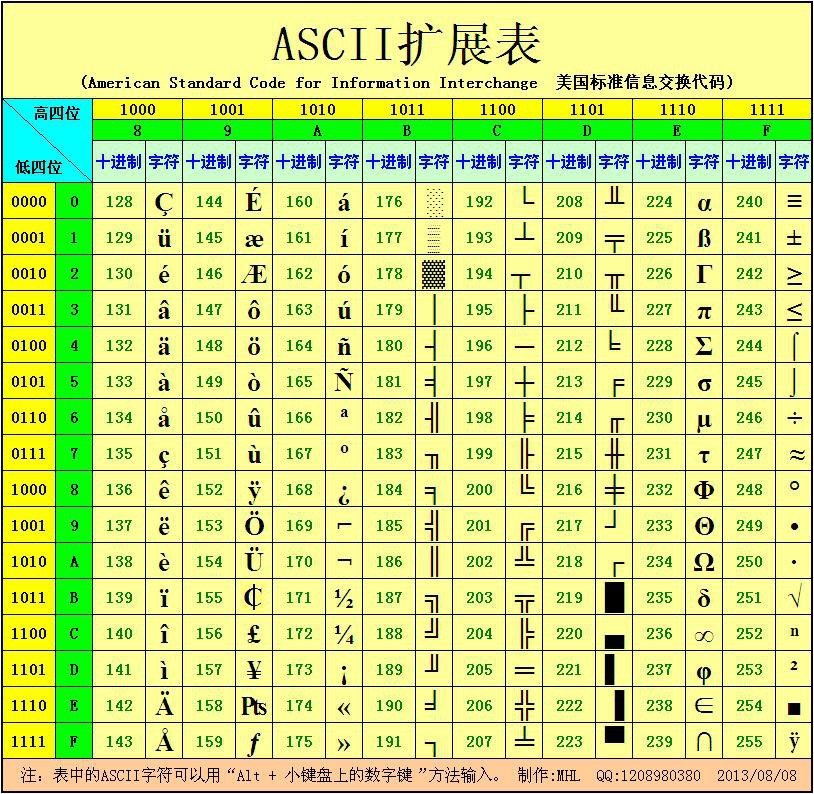
扩展ASCII码:
既然后128字符并不是强制标准,于是,各个国家纷纷制定了属于自己的文字编码规范,中国也制定了自己的编码规范GB2132,它是和ASCII码兼容的一种编码规范,事实上就是利用“扩展ASCII码”没有真正标准化这一点,把一个中文字符用两个扩展ASCII字符来表示,也就是一个中文字符占用2个字节。
局限问题:
在英语中,用前128个符号编码便可以表示所有字母,但是用来表示其他语言,这128个符号是远远不够的。比如,在法语中,字母上方有注音符号,这咋办呢?于是,一些欧洲国家就自行决定,利用后128位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,一些欧洲国家也开始使用这种编码方式,但最多也只有256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母。因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有各国编码方式中,0–127表示的符号都是一样的,不同的是128–255的这一段 。
关于亚洲国家的文字种类繁多,使用的符号就更多了,光汉字就多达10万种左右。一个字节仅仅只能表示256种符号,肯定是不够用的,那就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,规定使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个汉字 。
可以看出,如果让全世界都使用“ASCII码”或是“扩展ASCII码”,显然存在着诸多局限性问题。
ANSI标准
英文名称:(AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI 美国国家标准学会)
起源:从1918年成立,到1969年正式命名为美国国家标准学会(ANSI)
ANSI定义:
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,比如:汉字 ‘中’ 在中文操作系统中,使用 2个字节来表示1个字符。
ANSI编码:
不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GB2312编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 JIS 编码。
“ANSI编码”和“ASCII编码“有何关联:
看到这里你是否感觉“ANSI编码”和“ASCII编码”的概念有相似之处?!其实,ANSI编码所定义的0x00~0x7f 范围(0–127)的1 个字节来表示 1 个英文字符,即ASCII码。而定义中使用0x80~0xFFFF范围(128–35535)来编码使用2个字节表示1个字符,即扩展ASCII码。而且,不同 ANSI 编码(即不同国家的扩展ASCII码)之间互不兼容。当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。ANSI编码表示英文字符时用一个字节,表示中文字符用两个字节。
举一个例子:
Windows记事本默认保存编码是ANSI,这个大家可以在另存为窗口中看到可选择的编码方式。而这个ANSI编码,它在英文操作系统下用的是ASCII码,它在简体中文操作系统下用的是GB2312,它在繁体中文操作系统下用的是Big5,等等诸如此类。
适用对象:
ANSI编码作为中国以及部分亚太地区的多字符编码格式,其Windows系统和macOS都是提供原生支持的。但在Linux下却是UTF-8编码大行其道,特别是开发者清一色都使用UTF-8编码格式。这样看来,普通用户用ANSI编码,因为他们无需理解什么是ANSI编码,而专业的开发者都以UTF-8编码为主,开发者需要知道编码的含义及应用场景,关于UTF-8具体后面会讲到。
附图

Unicode(统一码)
非标准编码产生的问题:
中国自己制定的GB2312只是国家标准,而非国际标准,像台湾也自己制定一个Big5编码,其他如韩国、日本等都有自己的编码,这些通通不是国际标准。这种方法最大的问题就是,各国文字只适用于自己国家的编码,不能通用在其他国家。
我们再来看看这个“扩展ASCII码“,尽管没有真正的标准化,可是PC里的ASCII码还是有一个事实标准的(存放着英文制表符),所以早期非常多的软件利用这些符号来画表格。这样的软件用到中文系统中,这些表格符就会被误认作中文字,破坏版面。并且,统计中英文混合字符串中的字数,也是头疼的一件事,我们必须判断这个字符是否是“扩展ASCII码”,在逻辑上处理起来显得比较复杂。
这时候,我们就知道,要真正解决中文问题,不能从“扩展ASCII”的角度入手,也不能仅靠中国一家来解决。而必须有一个全新的编码系统,这个系统要能够将中文、英文、法文、德文……等等全部的文字统一起来考虑,为每一个文字都分配一个单独的编码,这样才不会有上面那种现象出现。
于是,Unicode诞生了:1990年研发,到1994年正式发布1.0版本,到2020年发布13.0版本。
两套标准:
Unicode有两套标准,一套叫UCS-2(Unicode-16),用2个字节为字符编码,还有一套叫UCS-4(Unicode-32),用4个字节为字符编码。
目前使用的是UCS-2,它能够表示的字符数为2^16=65535,基本上能够容纳全部的欧美字符和绝大部分的亚洲字符。而UCS-4是为了防止将来2个字节不够用才开发的。在Unicode里,全部的字符被一视同仁。汉字不再使用“两个扩展ASCII”,而是使用“1个Unicode”。注意,如今的汉字是“一个字符”了,于是,拆字、统计字数这些问题也就自然而然地攻克了。
可是,这个世界不是理想的,不可能在一夜之间全部的系统都使用Unicode来处理字符,所以Unicode在诞生之日,就必须考虑一个严峻的问题,和ASCII字符集之间的不兼容问题。我们知道,ASCII字符是单个字节的,比方“A”的ASCII是65。而Unicode是双字节的,比方“A”的Unicode是0065,这就造成了一个非常大的问题:以前处理ASCII的那套机制不能被用来处理Unicode了。
unicode定义和编码规则:
广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unicode 字符集和 UTF-8、UTF-16、UTF-32 等等编码。所以,简单来讲,Unicode可以看作一种标准,它包含了世界上所有的字符,什么语言、文字、符号统统包含在里面。如果可以,你甚至可以理解为unicode全球统一字符集。但这个unicode全球统一字符集不能直接输入到计算机中,所以需要一套编码方式才能让计算机认识,于是UTF-8、UTF-16、UTF-32 等等编码产生了,使用这些编码就可以在计算机中进行存储了。
UTF-8,当今的王者:
UTF-8属于Unicode的一种可变长度字符编码,用1到4个字节表示,它可以表示Unicode全球统一字符集中的任何字符,且其编码中的第一个字节仍与ASCII相容,在UTF-8编码中一个英文占1个字节,一个中文汉字占3个字节。
举一个例子:
既然Unicode 全球统一字符集为每一个字符分配一个码位。就拿我们应用最广泛的UTF-8来说(UTF-8 顾名思义,是一套以 8 位为一个编码单位的可变长编码),它将一个码位编码为 1 到 4 个字节。
如下表,编码对应二进制:
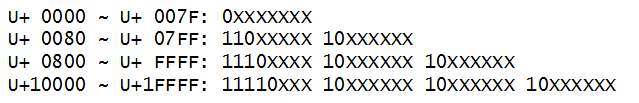
例如「知」的码位是 30693,记作 U+77E5(30693 的十六进制为 0x77E5)
根据上表中的编码规则,「知」字的码位 U+77E5 属于第三行的范围,中文汉字使用了3个字。

我们再来看一个具体一点的例子(来自互联网):
windows操作系统记事本另存为时,有四种编码:
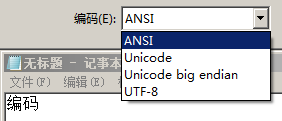
我们把四种编码分别存为4个文件:
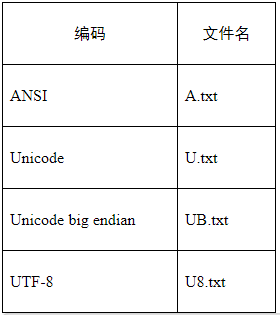
我们用VC++6.0或Visual Studio以二进制方式打开这4个文件,如下图所示:
1)ANSI编码
A.txt有四个字节:B1 E0 C2 EB。使用了GBK编码,其中B1 E0是指”编”,C2 EB指是”码”。
所以,记事本里的ANSI编码,在简体中文操作系统中,用的就是GBK编码。在繁体中文操作系统中,用的就是Big5编码……
2)UTF16BE编码
UB.txt有六个字节:FE FF 7F 16 78 01。其中FE FF是BOM(Byte Order Mark)。使用了Unicode字符集的UTF-16编码,0x7F16是指”编”,0x7801是指”码”。
UTF16BE编码是16位(2字节)的Unicode字符集编码,BE表示big endian,即高位字节在前,低位字节在后。0x7F16的高位字节是7F,低位字节是16,UTF16BE编码就是7F 16。
3)UTF16LE编码
U.txt有六个字节:FF FE 16 7F 01 78。其中FF FE是BOM。使用了Unicode字符集的UTF-16编码,0x7F16是指”编”,0x7801是指”码”。
UTF16LE编码是16位(2字节)的Unicode编码,LE表示little endian,即低位字节在前,高位字节在后。0x7F16的高位字节是7F,低位字节是16,UTF16LE编码就是16 7F。
由此可见:UTF16LE与UTF16BE只是高低位字节交换了一下而已。
4)UTF-8编码
U8.txt有九个字节:EF BB BF E7 BC 96 E7 A0 81。其中EF BB BF是BOM。使用了Unicode字符集的UTF-8编码,E7 BC 96是指”编”,E7 A0 81是指”码”。
5) BOM
BOM是Byte Order Mark的缩写,它用来指明编码,如下所示:
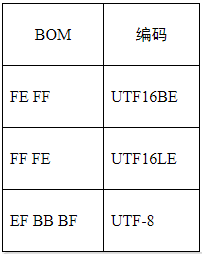
上面的FE FF和FF FE正好逆序,这也就是Byte Order Mark(字节顺序标记)的来由吧。
6) 乱码
windows记事本是通过BOM来区分不同编码,为什么ANSI不用BOM?原因在于——向下兼容。从DOS到Win98再到如今的Win10,记事本默认都是ANSI编码,从没考虑过加BOM。所以BOM对于windows记事本来说是没必要的,也是无关紧要的。
通过BOM来区分各种编码,是一个非常好的方法。不过,没有历史包袱的Linux不买账——Linux默认使用UTF-8编码,而且是没有BOM的UTF-8编码。
为了能够打开Linux生成的没有BOM的UTF-8编码文件,记事本在打开没有BOM的文本文件时,会对其进行检查。如果所有编码符合UTF-8,就以UTF-8编码打开。
我们把Linux下生成的UTF-8编码的txt拿到windows下,可以正常打开和显示,并在windows下把内容”编码”替换为”联通”,另存为选ANSI编码。再次打开,显示如下图所示:
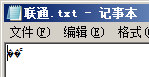
使用VC++6.0打开这个文件,一切正常,如下图所示:

windows下记事本显示乱码,是因为它会把”联通”的GBK编码C1 AA CD A8当做UTF-8编码进行显示。而VC++6.0没有显示乱码,是因为它不支持UTF-8编码,只支持ANSI编码。
附上一个编码字节数表
