
AlexNet
标签:rac 初始 负数 响应 并行 矩阵 inline inf 随机
一、AlexNet网络
1.1 结构
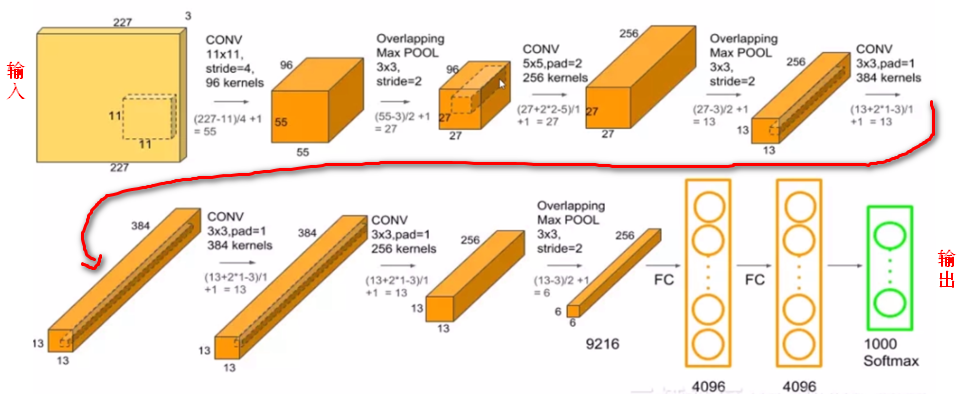
处理的步骤为
conv1 relu1 norm1 \(\rightarrow\) pool1 \(\rightarrow\) conv2 relu2 norm2 \(\rightarrow\) pool2 \(\rightarrow\) conv3 relu3 \(\rightarrow\) conv4 relu4 \(\rightarrow\) conv5 relu5 \(\rightarrow\) fc6 relu6 dropout6 \(\rightarrow\) fc7 relu7 dropout7 \(\rightarrow\) fc8(logits)\(\rightarrow\) softmax
1.2 创新点
成功使用Relu作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmod,成功解决了Sigmod在网络较深时的梯度消失问题。
训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽然有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
在CNN中使用重叠的最大池化,此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且让步长比池化核的尺寸小,这样池化层的输出之前会有重叠和覆盖,提升了特征的丰富性。
提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反应较小的神经元,增强了模型的泛化能力。(后来的VGG证明这个作用不大)
使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,同时AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
数据增强,随机地从\(256 \times 256\)的原始图像中截取\(224 \times 224\)大小的区域(以及水平翻转及镜像)对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,对这个Trick可以让错误率再下降1%。
二、Relu
2.1 激活函数
激活函数有很多种,一般一个网络只选择一种。常见激活函数如下,
\(tanh(x)\)
\(\tanh (x) = \frac{e^x-e^{-x}}{e^x+e^{-x}}\)
\(sigmod(x)\)
\(sigmod(x)=\frac{1}{1+e^{-x}}\)
\(relu(x)\)
\(relu(x)=max(0,x)\)
2.2 Relu优点
训练速度更快
相比于tanh,sigmod而言,relu的导数更好求,反向传播会涉及到激活函数的求导,tanh,sigmod包含指数且表达式复杂。增加网络非线性
relu为非线性函数,加入到神经网络中可以使网络拟合非线性的映射,因此增加了网络的非线性。防止梯度消失
当数值过大或者过小时,sigmod,tanh导数接近0,会导致反向传播的梯度消失问题,而relu作为非饱和激活函数不存在此问题。使网络具有稀疏性
relu可以使一些神经元输出为0,因此可以增加网络的稀疏性。
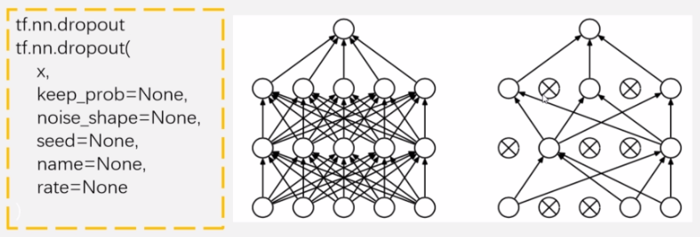
三、Dropout层
作用是随机将一定比例的神经元置为0。对于一个有N个节点的神经网络,有了dropout后,就可以看做是2n个模型的集合了,这相当于机器学习中的模型融合ensemble。
四、Softmax与Cross Entropy
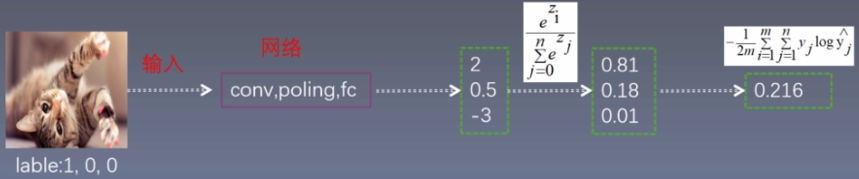
| softmax作用 | cross entropy作用 |
|---|---|
| 将神经网络的输出变为概率分布。 | 交叉熵衡量两个概率分布的距离 |
| 1.数据之和为1 | 1.值越小,两个概率越接近 |
| 2.负数变为正数 | 2.值越大,两个概率越不接近 |
| [2,0.5,-3]--->转变为[0.81,0.18,0.01] | 模型1预测的概率分布为[0.81,0.18,0.01], 则loss1 = -[\(1\times log(0.81)\)+\(0 \times log(0.18)\)+\(0\times log(0.01)\)]=0.21 |
五、卷积
5.1 网络参数
| 网络层 | kernel | deepth | strids | padding | input | output | parameters |
|---|---|---|---|---|---|---|---|
| conv1 | [11,11] | 96 | 4 | VALID | [227,227,3] | [55,55,96] | \begin{equation}(11\times 11\times 3 +1 ) \times 96\end{equation} |
| pool1 | [3,3] | 96 | 2 | VALID | [55,55,96] | [27,27,96] | --- |
| conv2_1 | [5,5] | 128 | 1 | SAME | [27,27,48] | [27,27,128] | \begin{equation} (5\times 5\times 48+1) \times 128\end{equation} |
| conv2_2 | [5,5] | 128 | 1 | SAME | [27,27,48] | [27,27,128] | \begin{equation}(5\times 5\times 48+1)\times 128\end{equation} |
| concate | --- | --- | --- | --- | ---- | [27,27,256] | --- |
| pool2 | [3,3] | 256 | 2 | VALID | [27,27,256] | [13,13,256] | --- |
5.2 计算公式
卷积特征图计算公式
\begin{equation}
F_0 = [\frac{F_{in} + 2p - k}{s}]+1
\end{equation}卷积方式为VALID
\begin{equation}
F_0 = [\frac{F_{in} - k + 1}{s}]
\end{equation}卷积方式为SAME
\begin{equation}
F_0 = [\frac{F_{in} }{s}]
\end{equation}连接数量计算公式,即
\(输出特征图尺寸 \times (卷积核大小 \times 卷积核通道 + 1) \ times 输出特征图通道数\)
\begin{equation}
F_0^2 = (K^2 \times K_C + 1) \times F_{0C}
\end{equation}
六、训练
6.1 训练数据
随机地从\(256 \times 256\)的原始图像中截取\(224 \times 224\)大小的区域(以及水平翻转及镜像),相当于增加了\(2 \times (256 - 224)^2 = 2048\)倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提高泛化能力。
对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,对这个Trick可以让错误率再下降1%。
进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。
6.2 超参数
批量大小
batchsize=128
权重衰减
weight decay = 0.0005
学习率
learning rate = 0.01 衰减率为0.1
轮数
epoches = 90
卷积核初始化方式:均值为0,方差为1的高斯分布。
偏置初始化方式:2,4,5卷积层及全连接层初始化为1,剩余层初始化为0。
标签:rac 初始 负数 响应 并行 矩阵 inline inf 随机
原文地址:https://www.cnblogs.com/yujingxiang/p/14461452.html