
谷歌科学家:目标优化不好使?今天聊聊泛化这件事儿

身处机器学习时代的我们通常头脑被目标函数和优化算法所充斥。这可能会将我们禁锢到认知的角落中无法脱身。
当我们跳出这个怪圈儿,将一直所追求的“优化目标”变成“泛化能力”时,说不定能够事半功倍,得到意想不到的好处。比如,我们甚至可以去要求那种高深莫测的“直觉”。
编译 Don
编辑青暮
在这篇文章中,谷歌机器人方向研究科学家 Eric Jang 将介绍一个深度学习构建工程中的大杀器,也是他在工作学习中经常使用、总结和坚信的一个关键的工程设计原则。
“这个原则指导着我,并让我形成如今的“研究品味”,也构成了我工作中的设计思路。这样的习惯或者设计原则让我走的更远,指导着我构建出大规模、通用的机器学习系统。”
以下为全文分享:
近年来,随着“神经网络缩放法则(Neural Scaling Laws)”的诞生,人们能够更加方便的利用起互联网上大规模的数据,也就是使用无监督的方法进行预训练操作,当然还有一些其他关于模型的工作。这就为机器学习未来的发展指出了一条令人兴奋的道路:
对于泛化来说,数量巨大而内容丰富的数据是很重要的,远比那些巧妙的模型设计技巧更加有效。
如果你相信上一点的话,那么你所训练的模型的泛化能力,将和你喂给模型的数据的多样性以及速度,呈现出明显的正比例关系。
所以很多人认为,如果你使用有监督的数据去训练你的深度学习模型,那么你的模型就会像个容量很大的“数据海绵”一样——它们可以记住大量的数据,并且可以通过数以万计的批量训练过程,快速的学习、记忆并且输出模型结果。
也许你会说数据多了也没用,好多模型的学习容量就仅此而已。但是目前来看,ResNet 和 Transformers 这样的现代深度学习架构还处于一种“没有吃饱”的状态,他们在训练的过程中还能吃下更多的有监督数据。
我们知道,在模型训练的过程中,如果损失函数(或者叫经验风险)降低到最低的时候,这个模型在理论上就已经“记住”了喂入的训练集。从传统的意义上来讲,当损失函数降低到最小之后,如果继续训练的话,会出现过拟合的问题。
但是对于参数量和泛化能力惊人的深度学习模型来说,似乎即便是过拟合了,它的泛化能力表现的也还不错。以下是“Patterns, Prediction, and Actions”一书中关于“双重下降(Double Descent)”现象的描述:它说明了在某些问题上,即使训练损失完全最小化,过度的训练模型也能继续减少测试误差或测试风险。
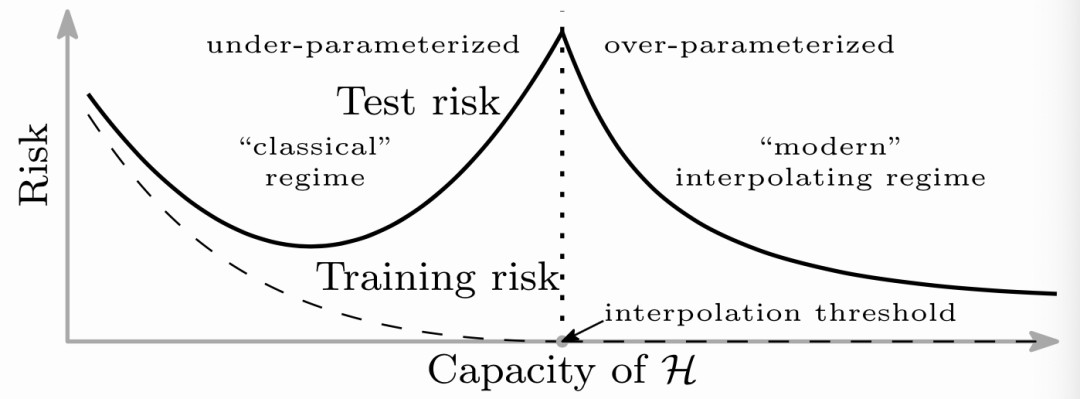
在最近 ICLR 的一个 Workshop 中的论文也研究了这一现象,他们在一个合成数据集上进行了实验。
结果表明,如果你的模型已经收敛,损失函数很低,并且在这种零训练损失的模式下仍然继续训练,当训练的时间足够长的时候,模型就会突然有一种“顿悟 Epiphany”,并在接下来的训练过程中学着去归纳总结(作者将之称作“摸索 Grokking”)。此外,该论文还提出了证据,表明增加训练数据,实际上减少了归纳所需的优化操作次数。
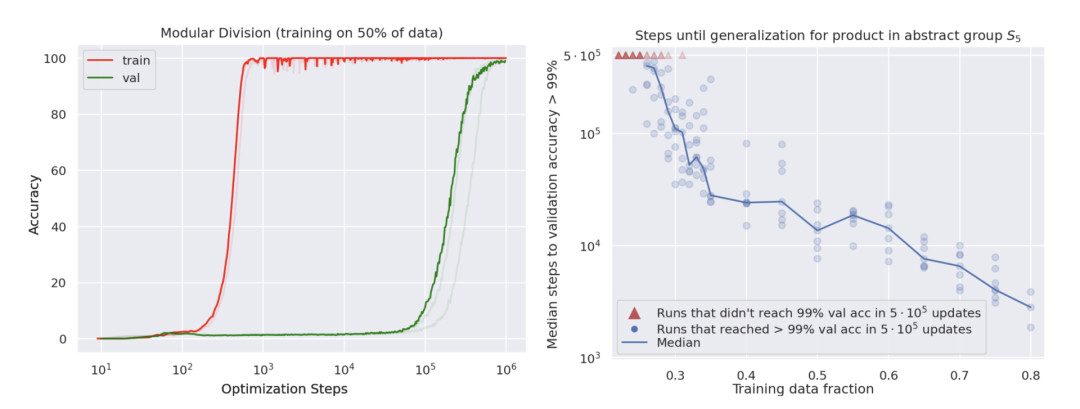
这就像我的同事 Chelsea Finn 曾经跟我说的那样:“记忆是走向泛化的第一步!”
结果中表示,如果我们过度训练,用这样的方式训练出来的最先进的神经网络模型,能够做出真正让人印象深刻的事情。我们在这里展示一个 DALL-E模型。当我们告诉它,要生成一个“一只香蕉在表演脱口秀”的时候,它画出了这样的图片:

一张不过瘾?再来一个。如果我们让 DALL-E生成“一个戴着耳机的熊猫宝宝盯着镜子里的倒影”的图片。

请注意,在我们喂给模型的训练数据中并没有“熊猫照镜子”或者“香蕉样子的喜剧演员”这样的图片(我觉得),所以这些结果表明,DALL-E模型已经学会从文本中区分并解释不同的概念,然后在图像中渲染对应的事物实体,并让它们在一定程度上做出我们想要的动作或状态。
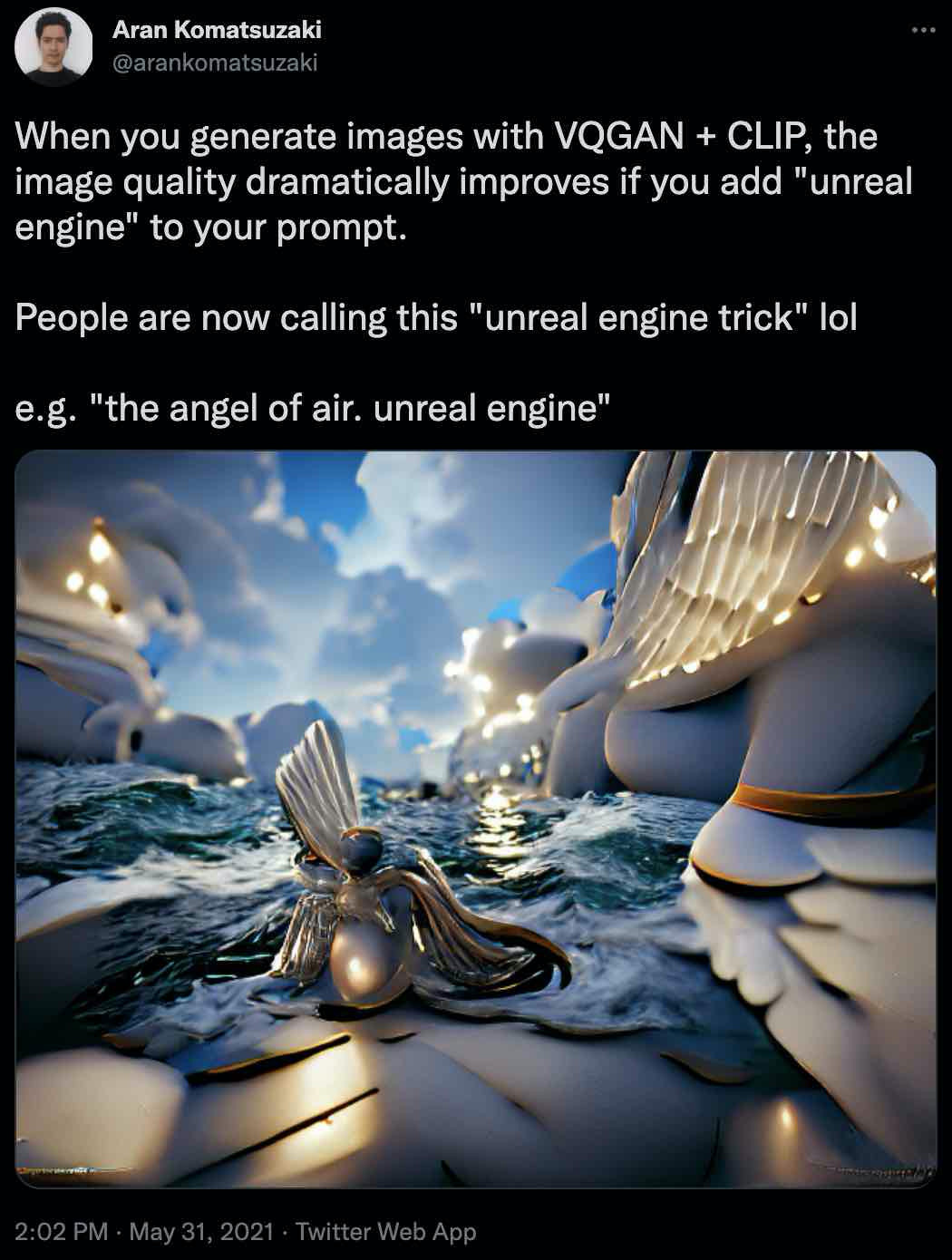
细思极恐,我们只要通过这种“单纯命令(Just Ask)”的语言命令,就能指导深度学习模型来输出或执行一些我们甚至都不知道是什么玩意儿的东西。这启发了我们!让我们觉得,这种“提示工程 Prompt engineering”式的模型,能够用来改善我们的机器学习模型。这里我们展出一条推文,讨论了用“虚幻引擎 Unreal Engine”这个词儿给 VQGAN+CLIP 模型打底,是怎么让图像质量大幅提高的。
进一步来说,如果我们能够将“只要求泛化”这一原则扩展到其他无法进行性能分析的挑战性问题上呢?
1
强化学习:不是块好的数据海绵
与监督学习相比,强化学习算法在面对大量差异化的数据时,其利用能力和计算效率要低的多。为了深入了解为什么会这样,让我们考虑一个思想实验:我们要去训练一个通用的机器人,让这个机器人在非结构化的环境中完成数百万的任务。
标准的马尔可夫决策过程设置如下:策略被表示为行动的状态条件分布,p(as);而环境则由奖励函数组成:r(st,at);转换函数表示为p(st+1st,at)。初始状态和任务目标被编码在初始状态 s0 中,它是一个从分布p(s0) 中取样的。
我们算法的目标是使整个事件中的奖励函数之和最大化,在不同的初始状态下取样自p(s0):

让我们假设存在某种“最优策略”,该策略可以实现最大化的激励 max0(R0)。“Supremum”可能在这种情况下更合适,但是为了让这个式子更好的计算和记忆,我们简化之。我们想让模型p(theta (as)尽可能的接近于p*(as).
如果我们能够得到最优策略p*(as),并将之称作“上帝视角 Oracle”,并可以像有监督的数据集一样通过查询上帝视角来获取其标签。这样的话,我们就可以去训练一个前馈策略,将状态映射到上帝视角上,并且享受一切监督学习方法所特有的优点:稳定的训练过程和操作、大批量、多样化的离线数据集,不用费劲儿和环境互动。

然而,在强化学习中,我们往往没有专家系统可以查询,所以,我们必须从模型自身所收集的经验数据中找到监督信息,并据此改进我们的策略。要做到这一点,我们需要估计出,能够使模型策略更接近于最优点的梯度,这就需要得到当前策略在这个环境中的平均偶发回报值(average episodic return of the current policy),然后估计该回报相对于参数的梯度。如果你把环境收益当做一个关于某些参数的黑箱来看的话,你可以使用对数衍生技巧(log-derivative)来估计这些梯度。
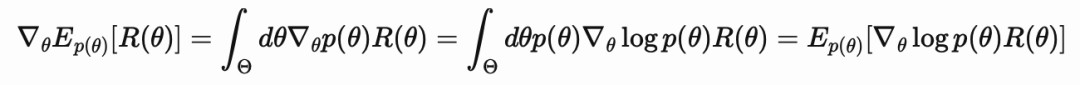
这个梯度估计包含两个期望组成,我们需要对其进行数学近似。首先是计算其本身,它是对起始状态的一个期望值。在我之前的文章中,我提到过对二项式变量(例如机器人在单一任务上的成功率)的精确估计可能需要成千上万次的实验,这样才能达到百分之几的统计确定性。这是对于当时我那篇文章中假设的通用型机器人来说的。
但是我们的任务可能包括数以百万计的任务和数不清的超多场景,那这使得精确评估的成本过高,可能我们强化学习算法还没学会,时间却过去几百年了。
第二个期望是在策略梯度的估计中遇到的一些算法,比如 CMA-ES,直接从策略参数分布中采样样本,而其他强化学习算法,如 PPO,则是从策略分布p_theta (as)中抽取样本,并使用反向传播法则来计算收益相对于参数的梯度。
而后者通常是实际中最常用的解决方法,因为行动参数的搜索空间,通常要比策略参数的搜索空间要小(因此需要更少的环境交互来估计梯度)。
如果在一个单一的上帝视角标记的标签a~p*(as)上进行监督的克隆操作,会得到一些监督的梯度向量g*。但是如果使用强化学习的话,想要达到同样的效果,是需要相当于O(H(s0)*H(a))倍的梯度向量监督才能实现的,而且其估计只能看做是一个相对较低的变异估计(low-variance estimate)。这种操作无疑是十分复杂的,会让我们的人工成本和操作过程十分复杂,手忙脚乱。在这种操作中,我们需要假设初始状态的熵分布有一个乘法系数O(H(s0)),并用其来估计R(theta)的分布。而且还要用O(H(a))来估计 Delta_thetaR (theta)本身。
所以说,强化学习,尤其是在奖励稀疏化、多样化、任务可能是多样性的场景中进行在线的强化学习,是需要大量的轮回滚动来准确估计回报以及他们的梯度向量的。
你必须在每一个小批量(mini-batch)的更新中来提供这些信息,这是这种操作所必须的成本!当环境需要处理繁复多样化的场景,并要求对未见过的情况进行归纳、总结和预测的时候,会需要在训练的过程中提供更多更全面的训练数据样本,也要求数据样本具有更加全面的多样化。
OpenAI DOTA 的开发团队发现,在训练过程中,只有他们的 mini-batch 中拥有数以百万计的样本的时候,才能将梯度噪声降低到可以接受的水平。
这在直觉上是可以讲的通的:如果我们是模型R(theta),在我们进行训练和学习的时候,每次接收 mini-batch 个样本,而我们需要去对 s0 个场景进行学习区分,而且还不能狗熊掰棒子似的学着新的而慢慢忘了之前的,那么当我们从监督学习转变成在线强化学习的时候,可能就会需要更大的训练样本量,更多的训练 batch,这个样本个数的增加可能是数倍、数十倍的增加。
2
那离线强化学习怎么样呢?
既然在线强化学习不太行,那离线版本的强化学习会不会更好呢?我们现在讨论一下 Deep Q-Learning 这样的离线强化学习方法在(S,A,R,S)这样的数据集上的表现。
这种方法是通过 bootstrapping 来工作的。其中我们将价值函数回归到的目标值是使用相同网络对下一个状态的最佳动作值估计的副本来计算的。
这些离线强化学习方法的吸引力在于,你可以从不同的、离策略的数据中得到最佳的策略,因此就不需要去和环境进行交互。像 QCL 这样的 Q learning 的改进版本的算法,在离线数据集上的效果还能更好,并且在数据量较小的模拟控制环境中还显示出了出色的性能和令人兴奋的前景。
但不幸的是,bootstrapping 并不能和泛化很好的结合起来。众所周知,函数近似(function approximation)、Bootstrapping 和 Off Policy data(学习来自目标策略之外的数据)这三个操作都会导致训练的不稳定性。
我认为在强化学习中,这个问题只会越来越严重,越来越被放大,因为我们扩大了数据集的规模,并期望在越来越抽象和一般化的任务上训练它们。
这项工作表明,反复的 bootstrapping 会迭代地降低神经网络的泛化能力和容量。如果你也同意深层神经网络的过度训练是泛化的关键这一观点的话,那么对于相同的神经网络架构,离线强化学习就不像监督学习那样具有“数据吸收 Data Absorbent”的能力。
在实践中,即便是一些优化后的强化学习算法,比如 CQL,它们在数据量很大、真实世界的数据集上进行扩展和调试的话,仍然具有很大的挑战性。我的同事曾经在大规模机器人问题上尝试了 AWAC 和 CQL 的几种扩展变化的算法,发现它们比行为克隆(Behavior Cloning)这样的原始的方法更难处理、更棘手。
那么我们自然会想到,与其费劲周折折腾半天,不如将经历放在深层网络所擅长的方面——通过有监督的学习和对大规模的数据泛化来快速获取数据,这样做的话,效果如何?我们是否能够通过利用泛化的工具而不是直接优化的操作来完成强化学习的学习目的?
3
学习分布,而不是学习到最佳的状态
如果我们将泛化作为算法设计的首要任务,或者说一等公民,并将其他的一切都视作是为其服务的二等公民,会发生什么呢?然后当我们可以通过监督学习简单地学习所有的策略,并“礼貌的要求 just ask nicely”般地要求其进行某些策略学习,又会发生什么呢?
让我们来看一下最近新兴的关于 Decision Transformer(DT)的工作,作者没有对单一的策略进行建模,而是用强化学习对齐进行迭代改进,他们只是用监督学习加上一个顺序模型来预测许多不同的策略的轨迹。
这个模型以回报率作为条件,以便它可以预测于实现这些回报的这个策略相一致的行动。Decision Transformer 只是用监督学习对所有策略,包括好的和坏的,进行建模,然后利用深度学习泛化的魔力,从专家挑战的策略中进行推断。
这些现象其实已经在之前的一些同时期进行的工作结果中被发现,并且得到了一些利用和发展,比如奖励条件策略(Reward-Conditioned Policies)、颠倒强化学习(Upside Down Reinforcement Learning)和“强化学习作为一个大序列建模问题 Reforcement Learning as One Big Sequence Modeling Problem”。
AlphaStar 团队还发现,以人类玩家的统计数据(例如他们最终建造的未来单位)为条件,用来模仿所有的玩家数据,比只去模仿专家级别的建造命令的训练效果要好。
这种技术也常用于自动驾驶的汽车领域,对好的司机和技术不佳的司机进行联合的建模,尽管自动驾驶策略只被用来模仿好的驾驶行为,但是这样的训练方法通常会得到较好的训练结果和模型。
4
马后炮式重新标记 Hindsight
在一些高层级语义的场景中,Decision Transformer 将监督下的学习目标以一些高层次的描述为条件,这些描述根据g的值来划分策略在未来会做什么。
对于强化学习任务来说,反向的操作(return to go)是强化学习中很占分量的操作,但是你也可以通过目标状态或《星际争霸》的构建顺序,甚至是对所完成的工作的自然语言描述来表达未来的结果。
在"Learning Latent Plans from Play"一文中,作者将任意的算法轨迹与事后的自然语言命令描述内容进行配对,然后训练一个模型来克隆那些以语言描述为条件的行为。
在测试的过程中,他们则会简单的要求这个策略以零为起点的方式完成一项新的任务。这些技术的好处是,它们对于在像蚂蚁迷宫这样的强化学习任务中,以少量探索(即稀疏)的目标驱动是与生俱来的。这就支持了这样的说法:在长周期的任务中,跨目标条件的泛化、概括和推理可以比对单一稀疏目标的暴力搜索做的更好。
语言是作为条件输入的一个良好的选择,因为它不仅可以用来划分算法轨迹,还可以按任务进行划分,按照策略的探索成都划分,按照它所达到的“动物性”的程度进行划分,还按照人类可能对算法轨迹的任何其他观察和评价指标进行划分。
输入的语言句子可以是临时拼凑的,比较随意,不用特意为机器人可能完成的所有结果,特意开发一个正式的专业语法甚至语言。
对于现实世界的结果和行为的多样性,语言是一种理想的“模糊”标识,随着我们要对越来越多的数据集进行操作、划分和分割,用自然语言进行命令的输入和执行,将会越来越重要。
5
从不完美的数据中进行泛化与归纳
我最近发现了一项有意思的工作,并且从中受到启发:D-REX,它解决了从次有策略的演示和数据中推断出环境的奖励函数的问题。
之前的时候,我们的训练场景中,都是默认输入给我们的系统和模型的都是最佳的策略,在这种情况中,我们能够使用离策略算法,比如 Q learning 来估计价值函数。
使用深度神经网络的离线价值估计方法可能会对不在演示轨迹中的状态-动作数据对产生不良的泛化作用,因此需要仔细调整算法,以确保价值函数的收敛。
一个收敛性差的算法会使训练损失最小化,从而使得泛化的能力和最终收敛到的状态十分脆弱。
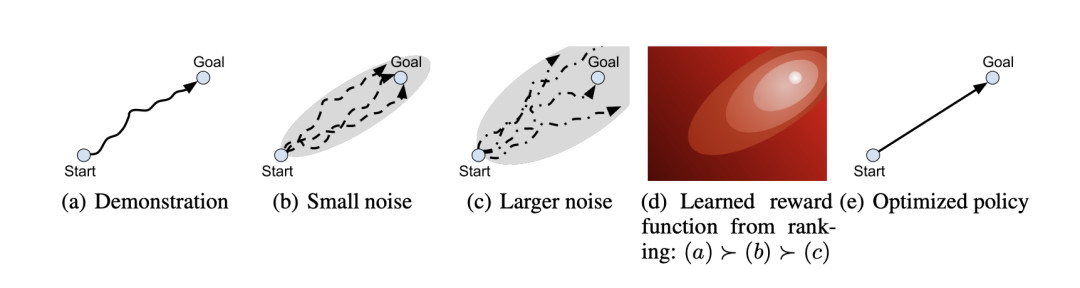
D-REX 提出了一个非常聪明和睿智的小技巧,来在数据策略是次优的情况下,绕过根本没有任何奖励标签的问题:
给出一个次优的策略 pi_theta,通过允许策略于环境的互动来生成轨迹滚动图。在轨迹滚动图中,向动作数据中添加一定量的噪声 sigma。
假设添加噪声的操作会让次优的策略的效果更差,也就是R(tao)>R(tao+sigma).
训练一个评分模型f_theta (tao_i, tao_j)来预测 tao_i和 tao_j谁有更高的评分,然后返回更高者。
评分模型可以神奇地推断出 tao_theta 能够推断出的模型中,哪个的效果比较好,即便评分模型从未在轨迹上训练得比 pi_theta 更优。
实话说,我很喜欢这种方法,因为评分模型训练起来是很稳定的,它们只是一些分类器,而且这种方法不是通过贝尔曼不等式的方法明确构建或者通过学习模型的隐性规划来实现优于示范者的行为,而是通过对一系列扰动的推断来实现的。
6
强化学习还需要从经验中学习并改进吗
在前文中,我们描述了如何“泛化和推断”从而绕过搜索,甚至可以从稀疏的奖励结果中进行逆向的强化学习。但是,我们是否想过“根据策略自身的经验进行改进,tabular rasa”呢?这是人们忍受实现 RL 算法的痛苦的主要原因。我们可以用监督学习算法和一些泛化来替代它吗?
强化学习的目标是从当前的参数集合 theta^n和一些收集到的策略经验 tao,来变化学习成一组新参数 theta^(n+1),从而来实现更高的回报和价值结果。那么,我们是否可以不使用“适当的”强化学习算法来更新智能体函数,而是转而通过监督深度学习f:(theta^n,tao)->theta^(n+1) 来直接学习这个映射呢?
这个想法有时候也被成为“元强化学习 meta reinforcement learning”,因为它的目标,涉及到了学习比现成的强化学习算法更好的强化学习函数。
我和我的同事将这个想法应用于一个项目之中。在这个项目中,我们训练了一个神经网络,它从一个较小的策略经验的视频中预测“改进的策略行为”。即使我们从未在最优策略轨迹上进行训练,也许足够的数据增强可以使得一般改进算子外推到参数的最优策略机制。
人们经常将这种策略改进行为与 DQN 和 PPO 等“强化学习算法”混为一谈,但实际上,它们的行为与实现有些差异。“策略改进操作 Policy improvement operator” f:(theta^n,tao)->theta^(n+1) 可以通过你选择的强化学习或监督学习来进行学习,但以类似强化学习的方式进行部署,从而来和环境进行交互。
7
“泛化为目标的指令”驱动式方法
下面,我给出一个表格,表格中总结了前面提到的强化学习的问题,并比较了如何使用“泛化和推断”的方法,而不是直接优化的方式,来解决其中的每个问题。
目标 | 直接优化方法 | 泛化+推断的方法 |
具有稀疏奖励的强化学习 | 找到p*(atst) 来让 Rt=1, 使用暴力搜索思路 | DT:从众多策略中学习p(atst, Rt),推断p(atst, Rt=1)。H.E.R 推断收集轨迹最佳的任务,然后学习p(trajectorytask)。然后推断所需任务的最佳轨迹。 |
从次优轨迹中学习奖励函数 | 离线反向强化学习 | D-REX:轨迹增强+推断更好的轨迹。 |
从经验中改进策略 | Q Learning,策略梯度 | Watch Try Learn:学习p(theta^n+1theta^n, tao, task)。 |
在真实的环境中微调模拟策略 | 样本高效的强化学习微调 | 领域随机:在仿真数据和环境中训练,然后规则推测出在测试和预测阶段中这是属于那个世界(infers which world)。 |
用高概括的语言进行控制的方式很简单。如果你想找到问题 xi 的解决方法 yi,可以考虑首先设定问题和解决方案的配对所构成的数据集(x1, y1), ..., (x2, y2),然后预训练一个深度神经网络y=f_theta (x),这个神经网络就能根据你输入的高级自然语言指令,映射到解决方案上。然后替换你想要的 xi 并让深层神经网络推断出解决方案。“问题”是最抽象的术语,它可以指代强化学习深度学习的环境、数据集,甚至是单个实例。“解决方法/解决方案”可以标识为策略或神经网络的最佳参数,或者单个预测。
目标重新标记(Goal Relabeling Techniques)等技术有助于从解决方案中生成事后的问题,但也可以通过数据集增强技术来搭建这样的数据集。从本质上来说,我们正在将一个困难的优化问题转化为一个推理问题,并在问题的分布上训练一个监督学习模型,这些问题的解决方案的成本相对较低。
在此,我们总结这种方法中的三个建议:
选择一种能够将海量数据集的训练损失最小化的方法,即最大似然的监督学习。这将有助于扩展到复杂、多样化的数据集中,并从预测预算中获得最大的泛化成果和达到最佳的里程碑。
如果你想学习p(yx, task=g*),并用它来执行任务预测g*,那就可以尝试为许多相关但不同的任务学习p(yx, task) g~p(g), g!=g*,那么在测试的时候只需要满足g*就可以了。
制定出有助于划分数据分布的条件变量,同时仍然允许对来自p(g)的保留样本进行泛化。自然语言编码是一个不错的选择。
我们可以将优化问题转化成为推理问题,这个操作其实并不是什么稀奇事儿。例如,SGD 优化器可以转化为近似贝叶斯推理,因此可以通过 AICO 进行优化控制。这些工作都在理论上支撑了“近似可以作为优化的近似品”的理论根基,因为问题和算法可以相互来回转换。
尽管如此,但是我所建议的和上述观点稍有区别。我们没有将顺序决策问题转化为等效的顺序推理问题,我们更多的是构建“元问题”:它们的问题描述拥有类似的分布,很容易获得解决方案。然后我们通过将问题直接映射到解决方案来使用监督学习解决元问题主题。
不要想的太多,我们只要用最简单的方式训练深度神经网络,然后要求它进行泛化就可以了。
也许在不久的未来,我们就能够通过输入一些特别虚幻的泛化描述("generalize to unseen")来实现我们的目标。
8
如果只要求意识(Consciousness)会怎样呢?
作为直接优化的替代品,我们可以将“泛化和推断”的原则延伸到多远呢?这是一个“意识驱动的方法 Recipe for consciousness”,也许这种方法能够达到一些意想不到的效果:
训练一个以自然语言为输入的多策略模型p_theta (as,g),可以通过 Decision Transformer 或者其他的类似工具实现。
然后我们用这个模型来模仿各种策略:pi_1,..., pi_N,并且以这些自然语言的代理描述g为预测函数的条件输入。
在测试时,一些默认策略p(as, g=Behave as yourself)与另一个智能体描述交互 pi 测试多个步骤,之后我们指示模型,让它“表现得好像你是 pi 测试”。这种模型需要一种“对他人的元认知”的能力,因为它必须推断出什么政策 pi_test 会在特定情况下进行。
我们复制了多策略模型p_phy~p_theta,并在单个场景中嵌入步骤(1) 的多个测试时间迭代,具有数十个智能体。其中两个智能体的最初条件是p_theta (as,g=表现得像我自己),以及p_phy (as,g=表现得像我自己)。
这会产生一些智能体模仿其他智能体的情况,并且所有智能体都观察到这种行为。然后我们问p_phy,发出带有条件上下文的动作“表现的好像是 pi_theta 冒充你”。这将需要 pi_phy 建模 pi_theta 的模仿能力,以及 pi_theta 知道 pi_phy 当前状态的信息。
很多研究人员,比如 Jurgen Schmidhuber 之前曾经讨论过一个话题,就是为什么实体智能体的动态模型(或者叫世界模型)为何已经是“有意识的”了,因为他们发现成功地模拟自己周围环境的动态需要将自我表示为环境中的实体参与者。
虽然我认为“自我表示”是规划和动态预测问题的必要条件,但是我还是认为这个框架太空洞了。它无法用于再现令人新服的意识模仿现象。你想,毕竟在每个想象的轨迹展开的过程中,都会明确的标识“自我”的任何规划算法在当前的这种定义下都是有意识的。而其实一个A*迷宫规划起 maze-planner 就能满足意识的这种定义。
在此,我所提议的是使用一种“更有说服力”的意识形式,而不仅仅是基于“对自我进行规划的必要表示”。
算法更需要的,其实是基于对自我的理解,这种理解可以通过与任何特定目标无关的语言和行为进行传播。例如,这个模型不仅需要了解给定的策略是如何看待自己的,还需要了解其他各种政策是如何解释这个策略的行为,就像是扭曲一面游乐园中的镜子一样。我们假设,通过展示对“扭曲的自我反思”的理解,这种策略将能够学会识别自己,并模拟智能体与智能体交互中其他智能体的内部的动机和信念。
行文至此,还有一些重要的实现细节我没能详细说明,但是在更高的层次上,我真的认为监督学习和自然语言作为条件输入,以及强大的智能体交互数据集是学习有趣行为的,十分优秀的工具。这种工具能够使得代理具有某种自我意识,也能让其他智能体的元认知能力朝着令人新服的意识模仿的方向,迈出重要的一步。
9
问答
Igor Mordatch 先生在评阅本文的时候提出了一些有趣的问题,我们进行了相应的讨论。我在这里解释了他的问题,并在本节中给出答复。
你讨论了监督学习和强化学习,那么你是如何看待无监督学习和“蛋糕类比 The Cake Analogy”问题的呢?
答:我认为无监督学习只是针对不同任务的监督学习而已,它具有可比的梯度方差,因为除了增强之外,目标通常不会被嘈杂有噪地估计。最大似然估计和对比算法,比如 InfoNCE,似乎都有助于促进庞大模型的泛化。
对于稳重强化学习的第一个难点,也就是评估成功,是否也和当前的生成模型有类似的地方?我们很难妥善的去评估语言模型,比如我们可以看到很多人对 BLEU 分数的不满,也能看到基于非似然性的生成图像模型评估似然性是很困难的。
答:与无似然生成模型类似,它需要大量计算来进行训练、采样,或者似然估计。然而,在实践中,我认为评估所带来的负担是不能直接拿来比较的,因为边缘化对此类模型的观察的计算费用,与强化学习中成功率估计的边缘化相比的话,相形见绌。在强化学习中,你必须在O(硬币反转)*O(初始化状态分布)*O(动作分布)上推断出环境,从而获得“在所有状态和任务中提高成功率”的低方差策略梯度。O(反转硬币)是O(1000) 个样本级别的操作,用于在统计确定性的情况下,局部改进几个百分点,而我认为,如果使用 Langevin 采样O(minibatch=32) 等技术的话,隐含可能性的边缘化成本往往是更便宜的。此外,Langevin 动力学中使用的反向传播传递,通常比运行完整的环境模拟(在每一步都向前传递神经网络)更便宜。
当前语言模型工作的一项发现是,你真正想要的智能体目标函数,其实已经足够好了。简单的下一个 token 的预测方法会导致泛化问题。但是,在大型模型的领域中,如果你想让代理和你想要的结果真正保持一致的话,还是一个难题,而且我们还没有很好的解决方法(其实很讽刺的是,迄今为止,许多尝试都是和强化学习一起来使用)。
答:对齐目标可能缺少每个样本实例的替代损失。但是在“泛化,然后推断”的流派中,我会简单地建议去学习p(yx, alignment objective)这一目标,与众多事后对齐目标的最大似然,然后在测试的时候简单的以所需的对象对齐为条件进行模型构建。人们可以通过简单的实时运行模型来获得对齐描述的分布,然后用模型实现的相应对齐,进行事后标记。然后我们就可以简单的调用 Connor Leahy 的这个方法:
仅仅让 AI 去做某件事,这个方法听起来好像很轻率和不靠谱,但是在看到 DALL-E和其他大规模多模态模型的表现之后,我们能够发现,似乎随着模型变大,泛化效果会变得更好。因此,反过来,我们应该更认真的对待这些简单的、边缘幼稚的想法。
对于强化学习(梯度估计)的第二个难点,我们能够通过环境动态进行反向传播,从而获得更加准确的策略梯度。但是这样做,通常会导致更糟糕的结果。
答:这个问题让我想起了 Yann Lecun 的一篇旧闻,是关于 FB 的评论。他是讨论 ReLU 激活估计 Hessian 向量乘积的方法的,其中说可以使用随机估计器而不是精确的计算来分析 Hessian,因为 Relu 的二阶曲率是0,并且我们其实想得到的是函数平滑版本的 Hessian 向量乘积。
如果你不想使用动态信息,也不想使用无偏随机估计,而是想用可微分的模拟方式进行训练,那么我认为你又需要进行很繁琐的估计的怪圈之中。因为很多时候,你需要经过多次推导来推出平滑模拟方程,并减少其方差。但是,也许估计一个平滑的策略梯度所需的样本量是一个合理的权衡,而这正是获得梯度的一个良好的方法。
为什么像你文中提出的(概括然后推断)这种方法看起来很简单,但是目前为止还没有人做出来?
答:其实一些研究员其实已经在研究这个方向了。我的猜测是,科研界倾向于奖励增加智能复杂性的叙述,并认为“我们需要更好的算法”。而人们则是天天嚷嚷着想要“简单的想法”,但是很少有人愿意真正的追求简单性的极致,并扩展现有的想法。
另一个原因则是,研究人员通常不会将泛化视为理所当然的事情,因此,他们通常会增添明确的归纳偏置,而不去把归纳作为第一等需要考虑的事情来做,也不会专门儿去为了支持它而调整其他的设计和设定。
你关于意识的建议很好玩,它和 Schmidhuber 的“世界中的意识”,Friston 的“自由能量原理”,以及霍金的“思想记忆”的想法,有什么关系呢?
我认为 Schmidhuber 和 Friston 的统一理论,或多或少的说明了“优化控制需要良好的未来预测,而我在其中的未来预测,则需要自我呈现”。如果我们拿大型语言模型中的下一个单词预测做类比的话,也许就能完美地优化下一个状态的预测就足以归纳出所有意识类型的腥味,比如心智理论和我上面提到的有趣的自我反思的例子。然而,这需要一个环境,在这个环境中,准确预测这种动态对观察的可能性有很大的影响。我对 Schmidhuber 和 Fristo 的框架其实也有一些不同的想法,就是它们太笼统了,甚至可以普遍适用于海蛞蝓和人类。如果未来的预测需要一定的环境复杂性,以产生人类能接受的有意识的东西,那么主要的挑战是明确系统中的最小的复杂性是什么。
霍金的“意识是感知记忆”的理论似乎等多的与意识的主观质感方面有关,而不是与心灵理论相关。请注意,大多数人并不认为一个连接 numpy 数组的程序能够像人类那样“体验到质感”的感觉。也许缺少的是元认知方面的一些事情,比如策略需要表现出的行为表明,它在思考它所经历的事情。同样的,这需要一个精心设计的环境来要求这种元认知行为。
我认为这可以从我前文描述的心智理论模仿问题的训练部分中出现,因为代理函数将需要访问关于它如何感知事物的一致性表征,并通过各种“其他代理的视角”来转化它。能够通过自己对其他代理的感知能力的表征,来投射自己对感觉观察的表征,这种灵活的特性让我相信,这种代理理解了它可以对质感进行充分的元认知。
你对意识的表述只关注心智理论的行为,那对于注意力行为来说又是什么样的呢?
答:可以参考回答 6 的第二段。
在 Rich Sutton 的 Bitter Lesson Essay 中,他认为搜索和学习都很重要。你也认为搜索可以完全被学习方法所取代吗?
答:我是这样认为的:如果在你的程序中有一点搜索的话,是能够对学习和整体的表现有极大的帮助的。但这有点像蛋生鸡和鸡生蛋的关系一样。我们想一下,AlphaGo 的成功是因为 MCTS 使用了一个可学习的价值函数来搜索所带来的?然后策略的蒸馏只是因为搜索才起作用的吗?我的建议是,当搜索变得太难的时候(很多强化学习任务都是如此),那么可以使用更多的学习操作来进行训练。其实,在进行监督学习的时候,你仍然在进行搜索,有所区分的是,你在每一次计算中都能得到更多的梯度信号而已。
原文链接:https://evjang.com/2021/10/23/generalization.html
来自: 雷锋网