Hi3559AV100 NNIE开发(5)mobilefacenet.wk仿真成功量化及与CNN_convert_bin_and_print_featuremap.py输出中间层数据对比过程
Hi3559AV100 NNIE开发(5)mobilefacenet.wk仿真成功量化及与CNN_convert_bin_and_print_featuremap.py输出中间层数据对比过程
前面随笔给出了NNIE开发的基本知识,下面几篇随笔将着重于Mobilefacenet NNIE开发,实现mobilefacenet.wk的chip版本,并在Hi3559AV100上实现mobilefacenet网络功能,外接USB摄像头通过MPP平台输出至VO HDMI显示结果。下文是Hi3559AV100 NNIE开发(5)mobilefacenet.wk仿真成功量化及与CNN_convert_bin_and_print_featuremap.py输出中间层数据对比过程,目前实现PC端对mobilefacenet.wk仿真成功量化,为后续在板载chip上加载mobilefacenet.wk输出数据进行比较做准备。
1、开发环境
操作系统:Windows 10
仿真工具: Ruyi Studio 2.0.28
开发平台: Hi3559AV100
网络模型: Mobilefacenet
框架:Caffe
2、测试前提
测试前需要搭建好RuyiStudio开发环境,能够正确运行工程,并进行了mobilefacenet 网络训练,生成mobilefacenet.caffemodel,确定好mobilefacenet.prototxt(因为mobilefacenet的所有网络层都是NNIE支持的网络层,所以不需要手动修改、增加或者删除操作,可以通过marked_prototxt中的mark和check操作查看是否正确生成对应的网络结构)。
3、mobileface.wk仿真量化参数配置与测试过程
在测试前先给出NNIE一般量化流程:
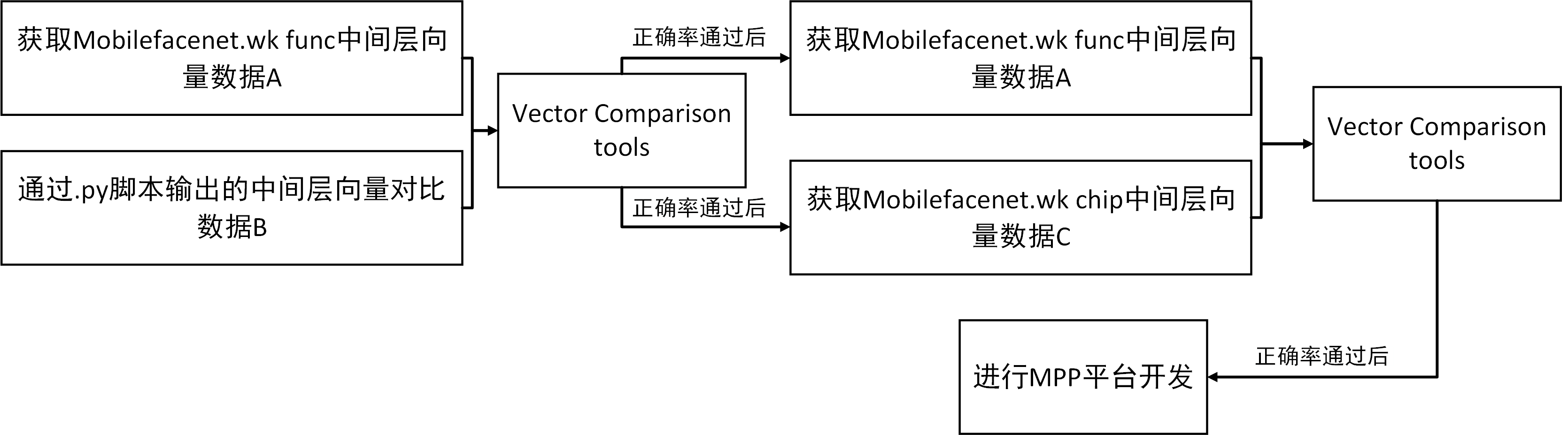
(1)需要把其他非caffemodel模型对应转换到caffemodel模型,因为Hi35xx系列NNIE只支持caffemodel模型;
(2)配置仿真量化参数(即配置mobilefacenet.cfg)进行PC仿真量化,获得中间层输出结果A(mapper_quant目录下);
(3)使用RuyiStudio提供的python中间层输出工具,获得中间层输出结果B(data/ouput目录下);
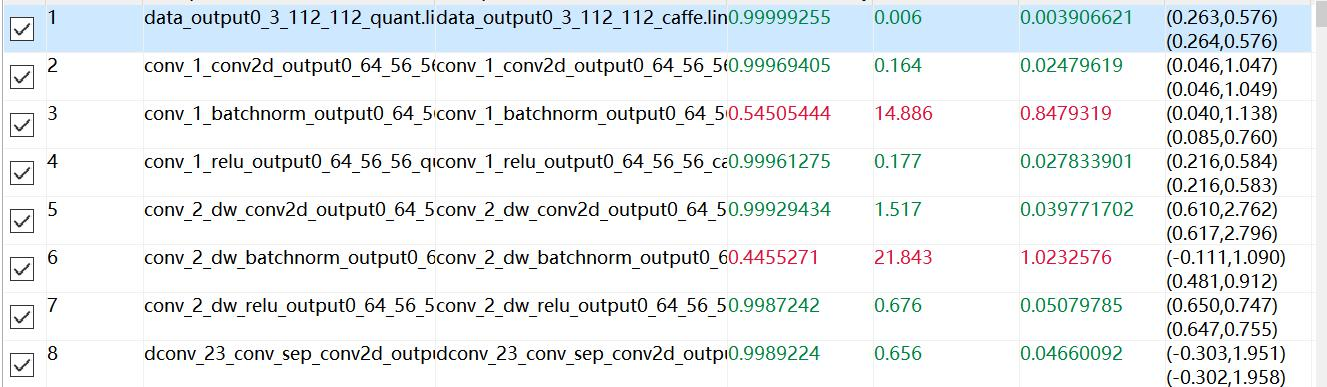
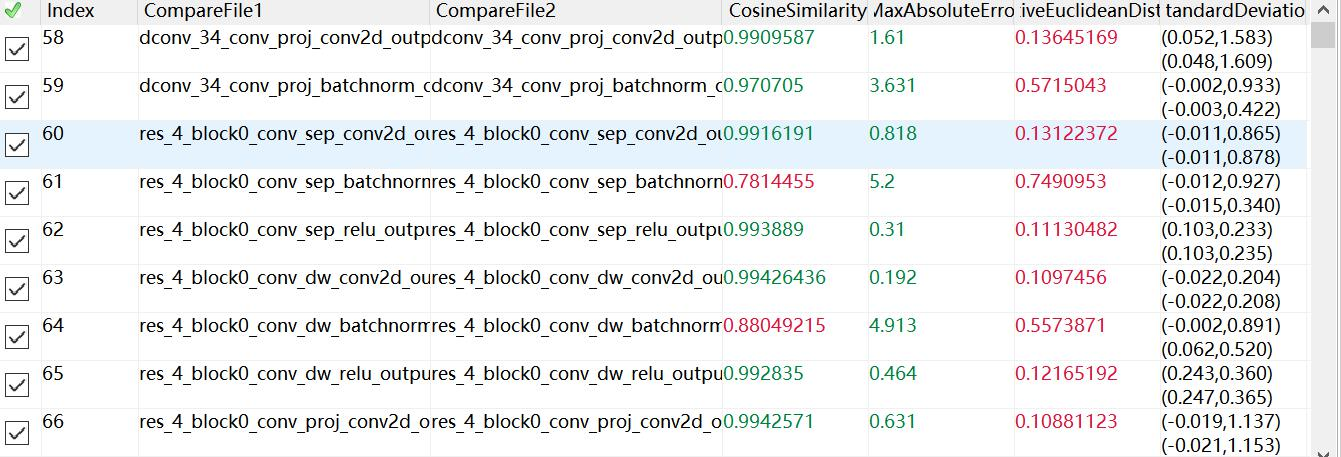
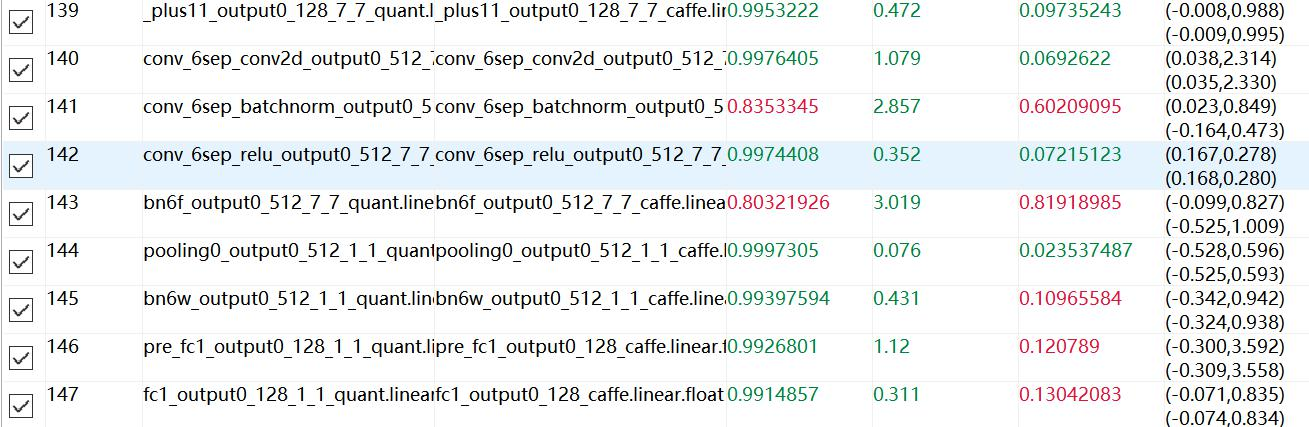
(4)使用Ruyi Studio的向量对比工具Vector Comparison对A和B进行对比,观察误差,使误差控制在一定范围(利用CosineSimilarity参数);
(5)配置板载chip运行量化参数生成mobilefacenet.wk文件,上板运行获得输出结果C;
(6)对比结果A和C,使仿真与板载误差控制在可接受范围内。
创建好工程后,首先配置mobilefacenet.wk文件,需要注意以下几点:
(1)首先选择is_simulation为Simulation进行仿真测试,对比结果正确后再进行Inst/Chip生成板上运行的wk文件。因为mobilefacenet的所有网络层都是NNIE支持的网络层,所以不需要手动修改、增加或者删除操作,可以通过marked_prototxt中的mark和check操作查看是否正确生成对应的网络结构;
(2)log_level = 3可以输出所有中间层的结果,在进行仿真对比调试时应当开启,方便进行向量对比调试;
(3)batch_num不能取大,取到之后会报错,目前batch_num = 16;
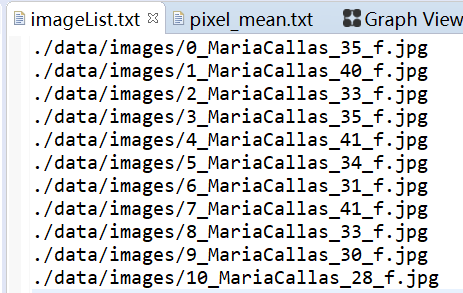
(4)image_list的设置十分关键,其决定了你实际输入给模型的图片数据是怎么样的。其中image_type默认选择U8,RGB_order表示输入给网络的RGB图像的RGB三通道顺序,norm_type是对图像数据的预处理,这里我们选择channel mean_value with data_scale,对输入图像的数据进行减均值并归一。设置data_scale为0.0078125,即1/128,pixel_mean.txt如下图所示。即让原本[0,255]区间的像素值转换到[-1,1]的区间内。下面给出imageList.txt文本内容:
(5)mapper_quant中保存了所有的输出信息,Mobileface_func.wk是生成的仿真wk文件。注意:mapper_quant中保存的输出信息是选择的image_list文件的最后一张图片的输出(这个非常关键,为后面.py输出中间层结果对比的时候确认是哪张图片进行向量数据对比)

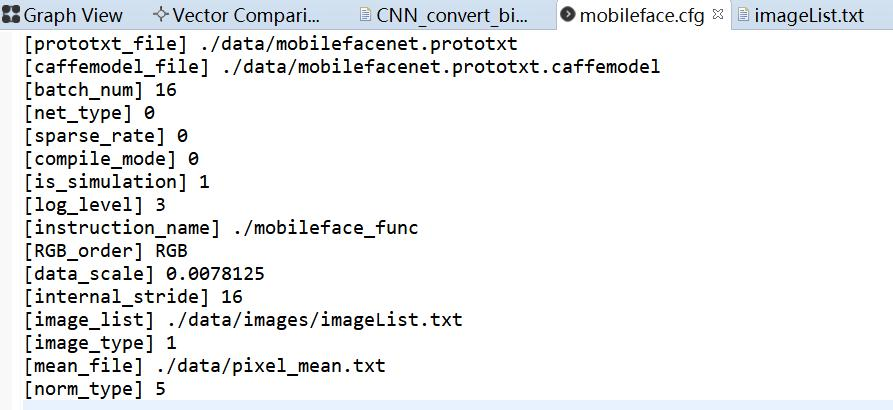
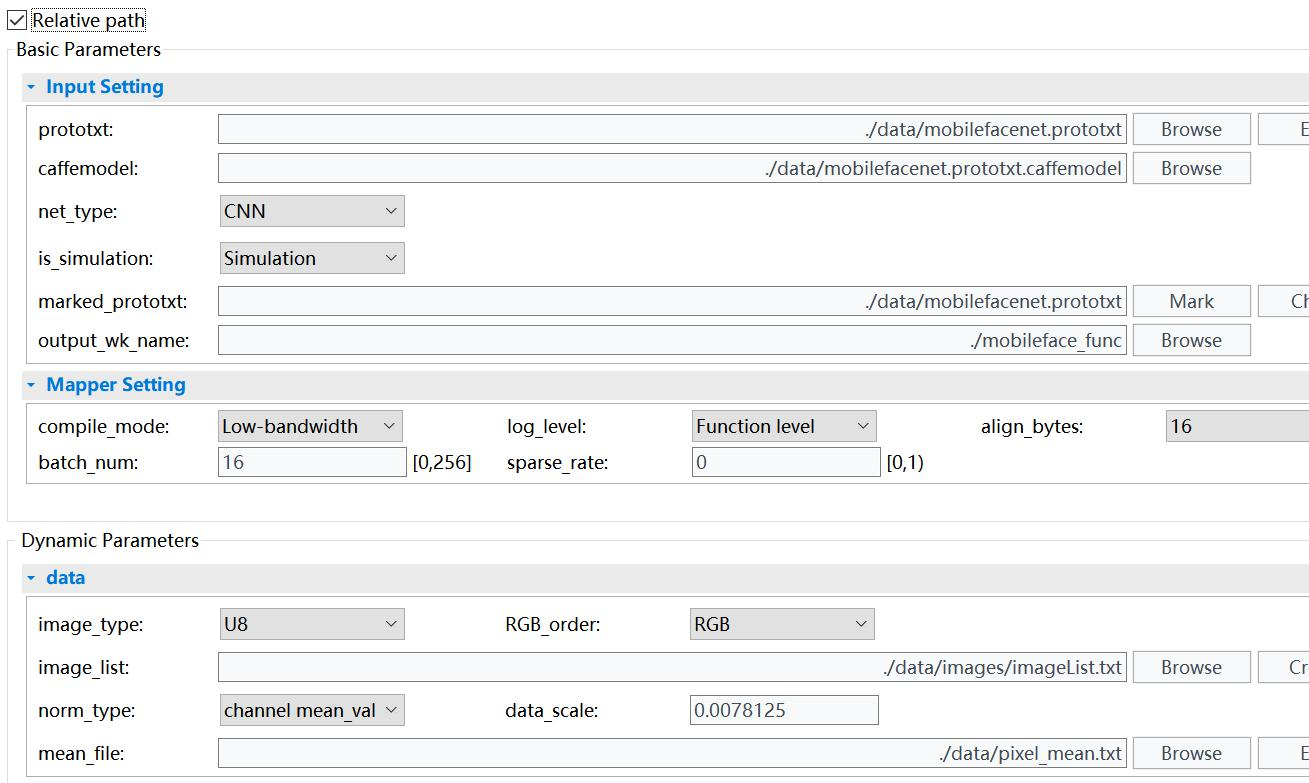
给出mobileface.cfg的具体配置:(具体.cfg参数设置可以见:Hi3559AV100 NNIE开发(3)RuyiStudio软件 .wk文件生成过程-mobilefacenet.cfg的参数配置 https://www.cnblogs.com/iFrank/p/14515089.html)
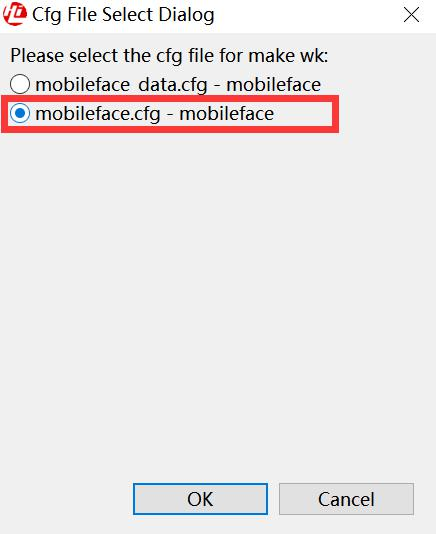
随后点击RuyiStudio软件左上角的make Wk按钮,跳出下面示意图,点击OK即可生成mobileface.wk:
4、xx.py输出中间层数据配置与过程
给出CNN_convert_bin_and_print_featuremap.py(RuyiStudio版本为2.0.28):(见此文件放置到mobileface工程data目录下)

1 #from __future__ import print_function 2 import caffe 3 import pickle 4 from datetime import datetime 5 import numpy as np 6 import struct 7 import sys, getopt 8 import cv2, os, re 9 import pickle as p 10 import matplotlib.pyplot as pyplot 11 import ctypes 12 import codecs 13 import caffe.proto.caffe_pb2 as caffe_pb2 14 import google.protobuf as caffe_protobuf 15 import google.protobuf.text_format 16 import platform 17 18 supported_layers=[ 19 "Convolution", "Deconvolution", "Pooling", "InnerProduct", "LRN", "BatchNorm", "Scale", "Bias", "Eltwise", "ReLU", "PReLU", "AbsVal", "TanH", "Sigmoid", "BNLL", "ELU", "LSTM", "RNN", "Softmax", "Exp", "Log", "Reshape", "Flattern", "Split", "Slice", "Concat", "SPP", "Power", "Threshold", "MVN", "Parameter", "Reduction", "Proposal", "Custom", "Input", "Dropout"] 20 21 def isSupportedLayer(layer_type): 22 for type in supported_layers: 23 if(layer_type == type): 24 return True 25 return False 26 27 28 def image_to_array(img_file, shape_c_h_w, output_dir): 29 result = np.array([]) 30 print("converting begins ...") 31 resizeimage = cv2.resize(cv2.imread(img_file), (shape_c_h_w[2],shape_c_h_w[1])) 32 b,g,r = cv2.split(resizeimage ) 33 height, width, channels = resizeimage.shape 34 length = height*width 35 #print(channels ) 36 r_arr = np.array(r).reshape(length) 37 g_arr = np.array(g).reshape(length) 38 b_arr = np.array(b).reshape(length) 39 image_arr = np.concatenate((r_arr, g_arr, b_arr)) 40 result = image_arr.reshape((1, length*3)) 41 print("converting finished ...") 42 file_path = os.path.join(output_dir, "test_input_img_%d_%d_%d.bin"%(channels,height,width)) 43 with open(file_path, mode='wb') as f: 44 p.dump(result, f) 45 print("save bin file success") 46 47 def image_to_rgb(img_file,shape_c_h_w, output_dir): 48 print("converting begins ...") 49 #image = cv2.imread(img_file) 50 image = cv2.imdecode(np.fromfile(img_file, dtype=np.uint8), 1) 51 image = cv2.resize(image, (shape_c_h_w[2],shape_c_h_w[1])) 52 image = image.astype('uint8') 53 height = image.shape[0] 54 width = image.shape[1] 55 channels = image.shape[2] 56 file_path = os.path.join(output_dir, "test_input_img_%d_%d_%d.rgb"%(channels,height,width)) 57 fileSave = open(file_path,'wb') 58 for step in range(0,height): 59 for step2 in range (0, width): 60 fileSave.write(image[step,step2,2]) 61 for step in range(0,height): 62 for step2 in range (0, width): 63 fileSave.write(image[step,step2,1]) 64 for step in range(0,height): 65 for step2 in range (0, width): 66 fileSave.write(image[step,step2,0]) 67 68 fileSave.close() 69 print("converting finished ...") 70 71 def image_to_bin(img_file,shape_c_h_w, output_dir): 72 print("converting begins ...") 73 #image = cv2.imread(img_file) 74 image = cv2.imdecode(np.fromfile(img_file, dtype=np.uint8), 1) 75 image = cv2.resize(image, (shape_c_h_w[2],shape_c_h_w[1])) 76 image = image.astype('uint8') 77 height = image.shape[0] 78 width = image.shape[1] 79 channels = image.shape[2] 80 file_path = os.path.join(output_dir, "test_input_img_%d_%d_%d.bin"%(channels,height,width)) 81 fileSave = open(file_path,'wb') 82 for step in range(0,height): 83 for step2 in range (0, width): 84 fileSave.write(image[step,step2,2]) 85 for step in range(0,height): 86 for step2 in range (0, width): 87 fileSave.write(image[step,step2,1]) 88 for step in range(0,height): 89 for step2 in range (0, width): 90 fileSave.write(image[step,step2,0]) 91 92 fileSave.close() 93 print("converting finished ...") 94 95 def image_to_bgr(img_file,shape_c_h_w, output_dir): 96 print("converting begins ...") 97 #image = cv2.imread(img_file) 98 #print(shape_c_h_w[2]) 99 #print(shape_c_h_w[1])100 image = cv2.imdecode(np.fromfile(img_file, dtype=np.uint8), -1)101 image = cv2.resize(image, (shape_c_h_w[2],shape_c_h_w[1]))102 image = image.astype('uint8')103 b,g,r = cv2.split(image)104 height = image.shape[0]105 width = image.shape[1]106 channels = image.shape[2]107 file_path = os.path.join(output_dir, "test_input_img_%d_%d_%d.bgr"%(channels,height,width))108 fileSave = open(file_path,'wb')109 for step in range(0,height):110 for step2 in range (0, width):111 fileSave.write(b[step,step2])112 for step in range(0,height):113 for step2 in range (0, width):114 fileSave.write(g[step,step2])115 for step in range(0,height):116 for step2 in range (0, width):117 fileSave.write(r[step,step2])118 119 fileSave.close()120 print("converting finished ...")121 122 def bin_to_image(bin_file,shape_c_h_w):123 #fileReader = open(bin_file,'rb', encoding='utf-8')124 if(platform.system()=="Linux"):125 fileReader = open(bin_file,'rb')126 else:127 fileReader = open(bin_file.encode('gbk'),'rb')128 height = shape_c_h_w[1]129 width = shape_c_h_w[2]130 channel = shape_c_h_w[0]131 imageRead = np.zeros((shape_c_h_w[1], shape_c_h_w[2], shape_c_h_w[0]), np.uint8)132 for step in range(0,height):133 for step2 in range (0, width):134 a = struct.unpack("B", fileReader.read(1))135 imageRead[step,step2,2] = a[0]136 for step in range(0,height):137 for step2 in range (0, width):138 a = struct.unpack("B", fileReader.read(1))139 imageRead[step,step2,1] = a[0]140 for step in range(0,height):141 for step2 in range (0, width):142 a = struct.unpack("B", fileReader.read(1))143 imageRead[step,step2,0] = a[0]144 fileReader.close()145 return imageRead146 147 def isfloat(value):148 try:149 float(value)150 return True151 except ValueError:152 return False153 154 155 def get_float_numbers(floatfile):156 mat = []157 if(platform.system()=="Linux"):158 with open(floatfile, 'rb') as input_file:159 for line in input_file:160 line = line.strip()161 for number in line.split():162 if isfloat(number):163 mat.append(float(number))164 else:165 with open(floatfile.encode('gbk'), 'rb') as input_file:166 for line in input_file:167 line = line.strip()168 for number in line.split():169 if isfloat(number):170 mat.append(float(number))171 return mat172 173 def isHex(value):174 try:175 int(value,16)176 return True177 except ValueError:178 return False179 180 def isHex_old(value):181 strvalue=str(value)182 length = len(strvalue)183 if length == 0:184 return False185 i = 0186 while(i < length):187 if not (strvalue[i] >= 'a' and strvalue[i] <= 'e' or strvalue[i] >= 'A' and strvalue[i] <= 'E' or strvalue[i] >= '0' and strvalue[i] <= '9'):188 return False189 i += 1190 return True191 192 def get_hex_numbers(hexfile):193 mat = []194 if(platform.system()=="Linux"):195 with open(hexfile) as input_file:196 for line in input_file:197 line = line.strip()198 for number in line.split():199 if isHex(number):200 mat.append(1.0*ctypes.c_int32(int(number,16)).value/4096)201 else:202 with open(hexfile.encode("gbk")) as input_file:203 for line in input_file:204 line = line.strip()205 for number in line.split():206 if isHex(number):207 mat.append(1.0*ctypes.c_int32(int(number,16)).value/4096)208 return mat
209 210 def print_CNNfeaturemap(net, output_dir):211 params = list(net.blobs.keys())212 print (params)213 for pr in params[0:]:214 print (pr)
215 res = net.blobs[pr].data[...]216 pr = pr.replace('/', '_')217 pr = pr.replace('-', '_')218 print (res.shape)219 for index in range(0,res.shape[0]):220 if len(res.shape) == 4:221 filename = os.path.join(output_dir, "%s_output%d_%d_%d_%d_caffe.linear.float"%(pr,index,res.shape[1],res.shape[2],res.shape[3]))222 elif len(res.shape) == 3:223 filename = os.path.join(output_dir, "%s_output%d_%d_%d_caffe.linear.float"%(pr, index,res.shape[1],res.shape[2]))224 elif len(res.shape) == 2:225 filename = os.path.join(output_dir, "%s_output%d_%d_caffe.linear.float"%(pr,index,res.shape[1]))226 elif len(res.shape) == 1:227 filename = os.path.join(output_dir, "%s_output%d_caffe.linear.float"%(pr,index))228 f = open(filename, 'wb')
229 230 np.savetxt(f, list(res.reshape(-1, 1)))231 232 # save result by layer name233 def save_result(train_net, net, output_dir):234 #logging.debug(net_param)235 max_len = len(train_net.layer)236 237 # input data layer238 index = 0239 for input in train_net.input:240 layer_data = net.blobs[input].data[...]241 layer_name=input.replace("/", "_")242 layer_name=input.replace("-", "_")243 shape_str= str(layer_data.shape)244 shape_str=shape_str[shape_str.find(", ") + 1:].replace("(", "").replace(")", "").replace(" ", "").replace(",", "_")245 filename = os.path.join(output_dir, "%s_output%d_%s_caffe.linear.float"%(layer_name, index, shape_str))246 np.savetxt(filename, layer_data.reshape(-1, 1))247 index = index + 1248 # other layer249 i = 0250 for layer in train_net.layer:251 index = 0252 for top in layer.top:253 # ignore inplace layer254 if 1 == len(layer.top) and 1 == len(layer.bottom) and layer.top[0] == layer.bottom[0]:255 break256 layer_data = net.blobs[top].data[...]257 layer_name=layer.name.replace("/", "_")258 layer_name=layer.name.replace("-", "_")259 shape_str= str(layer_data.shape)260 shape_str=shape_str[shape_str.find(", ") + 1:].replace("(", "").replace(")", "").replace(" ", "").replace(",", "_")261 filename = os.path.join(output_dir, "%s_output%d_%s_caffe.linear.float"%(layer_name, index, shape_str))262 np.savetxt(filename, layer_data.reshape(-1, 1))263 index = index + 1264 # update the process_bar265 i = i + 1266 k = i * 100 / max_len267 process_str = ">" * int(k) + " " * (100 - int(k))268 sys.stdout.write('\r'+ process_str +'[%s%%]'%(k))269 sys.stdout.flush()270 sys.stdout.write("\n")271 sys.stdout.flush()272 273 def main(argv):274 if len(argv) < 6:275 print ('CNN_convert_bin_and_print_featuremap.py -m <model_file> -w <weight_file> -i <img_file or bin_file or float_file> -p <"104","117","123" or "ilsvrc_2012_mean.npy">')276 print ('-m <model_file>: .prototxt, batch num should be 1')277 print ('-w <weight_file>: .caffemodel')278 print ('-i <img_file>: .JPEG or jpg or png or PNG or bmp or BMP')279 print ('-i <bin_file>: test_img_$c_$h_$w.bin')280 print ('-i <float_file>: %s_output%d_%d_%d_%d_caffe.linear.float')281 print ('-n <norm_type>: 0(default): no process, 1: sub img-val and please give the img path in the parameter p, 2: sub channel mean value and please give each channel value in the parameter p in BGR order, 3: dividing 256, 4: sub mean image file and dividing 256, 5: sub channel mean value and dividing 256')
282 print ('-s <data_scale>: optional, if not set, 0.003906 is set by default')283 print ('-p <"104", "117", "123" or "ilsvrc_2012_mean.npy" or "xxx.binaryproto">: -p "104", "117", "123" is sub channel-mean-val, -p "ilsvrc_2012_mean.npy" is sub img-val and need a ilsvrc_2012_mean.npy')284 print ('-o <output_dir: optional, if not set, there will be a directory named output created in current dir>')285 print ('-c <0 or 1> 1, gpu, 0 cpu')286 print ('any parameter only need one input')287 288 sys.exit(2)289 norm_type = 0290 data_scale = 0.003906291 output_dir = 'output/'292 opts, args = getopt.getopt(argv, "hm:w:i:n:s:p:o:c:")293 cuda_flag = 0294 for opt, arg in opts:295 if opt == '-h':296 print ('CNN_convert_bin_and_print_featuremap.py -m <model_file> -w <weight_file> -i <img_file or bin_file or float_file> -p <"104","117","123" or "ilsvrc_2012_mean.npy">')297 print ('-m <model_file>: .prototxt, batch num should be 1')298 print ('-w <weight_file>: .caffemodel')299 print ('-i <img_file>: .JPEG or jpg or png or PNG or bmp or BMP')300 print ('-i <bin_file>: test_img_$c_$h_$w.bin')301 print ('-i <float_file>: %s_output%d_%d_%d_%d_caffe.linear.float')302 print ('-n <norm_type>: 0(default): no process, 1: sub img-val and please give the img path in the parameter p, 2: sub channel mean value and please give each channel value in the parameter p in BGR order, 3: dividing 256, 4: sub mean image file and dividing 256, 5: sub channel mean value and dividing 256')303 print ('-s <data_scale>: optional, if not set, 0.003906 is set by default')304 print ('-p <"104", "117", "123", "ilsvrc_2012_mean.npy" or "xxx.binaryproto">: -p "104", "117", "123" is sub channel-mean-val, -p "ilsvrc_2012_mean.npy" is sub img-val and need a ilsvrc_2012_mean.npy')305 print ('-o <output_dir: optional, if not set, there will be a directory named output created in current dir>')306 print ('-c <0 or 1> 1, gpu, 0 cpu')307 print ('any parameter only need one input')308 309 sys.exit()310 elif opt == "-m":311 model_filename = arg312 elif opt == "-w":313 weight_filename = arg314 elif opt == "-i":315 img_filename = arg316 elif opt == "-n":317 norm_type = arg318 elif opt == "-s":319 data_scale = arg320 elif opt == "-o":321 output_dir = arg322 elif opt == "-p":323 meanfile = arg # default is to divide by 255324 initialway = "sub mean by: " + meanfile325 elif opt == "-c":326 cuda_flag = arg327 328 if('1' == cuda_flag):329 caffe.set_mode_gpu()330 caffe.set_device(0)331 332 train_net = caffe_pb2.NetParameter()333 if(platform.system()=="Linux"):334 f=open(model_filename, 'rb')335 else:336 f=open(model_filename.encode('gbk'), 'rb')337 338 train_str = f.read()339 caffe_protobuf.text_format.Parse(train_str, train_net)340 f.close()341 layers = train_net.layer342 343 for layer in layers:344 if(False == isSupportedLayer(layer.type)):345 print("Layer " + layer.name + " with type " + layer.type + " is not supported, please refer to chapter 3.1.4 and FAQ of \"HiSVP Development Guide.pdf\" to extend caffe!")346 sys.exit(1)347 print ('model file is ', model_filename)348 print ('weight file is ', weight_filename)349 print ('image file is ', img_filename)350 print ('image preprocessing method is ', norm_type) # default is no process351 print ('output dir is ', output_dir)352 print ('data scale is ', data_scale)353 if(platform.system()=="Linux"):354 net = caffe.Net(model_filename, weight_filename, caffe.TEST)355 else:356 net = caffe.Net(model_filename.encode('gbk'), weight_filename.encode('gbk'), caffe.TEST)357 358 print ('model load success')359 360 if norm_type == '1' or norm_type == '4':
361 if not os.path.isfile(meanfile):362 print("Please give the mean image file path")
363 sys.exit(1)364 if meanfile.endswith('.binaryproto'):365 meanfileBlob = caffe.proto.caffe_pb2.BlobProto()366 if(platform.system()=="Linux"):367 meanfileData = open(meanfile, 'rb').read()368 else:369 meanfileData = open(meanfile.encode('gbk'), 'rb').read()370 meanfileBlob.ParseFromString(meanfileData)371 arr = np.array(caffe.io.blobproto_to_array(meanfileBlob))372 out = arr[0]373 np.save('transMean.npy', out)374 meanfile = 'transMean.npy'375 376 print ('model file is ', model_filename)377 print ('weight file is ', weight_filename)378 print ('image file is ', img_filename)379 print ('image preprocessing method is ', norm_type) # default is no process380 print ('output dir is ', output_dir)381 print ('data scale is ', data_scale)382 383 if not os.path.isdir(output_dir):384 os.mkdir(output_dir)385 386 if img_filename.endswith('.jpg') or img_filename.endswith('.png') or img_filename.endswith('.jpeg') or img_filename.endswith('.bmp') or img_filename.endswith('.JPEG') or img_filename.endswith('.PNG') or img_filename.endswith('.JPG') or img_filename.endswith('.BMP'):387 388 image_to_bin(img_filename, net.blobs['data'].data.shape[1:], output_dir)389 if net.blobs['data'].data.shape[1]==1:390 color = False391 elif net.blobs['data'].data.shape[1]==3:392 image_to_rgb(img_filename, net.blobs['data'].data.shape[1:], output_dir)393 image_to_bgr(img_filename, net.blobs['data'].data.shape[1:], output_dir)394 color = True395 img = cv2.imdecode(np.fromfile(img_filename, dtype=np.uint8), -1)396 #img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #add here397 inputs = img398 elif img_filename.endswith('.bin'):399 if(platform.system()=="Linux"):400 fbin = open(img_filename)
401 else:402 fbin = open(img_filename.encode('gbk'))
403 data = bin_to_image(img_filename,net.blobs['data'].data.shape[1:])404 inputs = data405 elif img_filename.endswith('.float'):406 data = np.asarray(get_float_numbers(img_filename))407 inputs = data408 inputs= np.reshape(inputs, net.blobs[list(net.blobs.keys())[0]].data.shape)409 elif img_filename.endswith('.hex'):410 data = np.asarray(get_hex_numbers(img_filename))411 inputs = data412 inputs= np.reshape(inputs,net.blobs[list(net.blobs.keys())[0]].data.shape)413 else:414 print("errors: unknown input file!")415 sys.exit(1)416 417 if len(inputs):418 transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})419 if net.blobs['data'].data.shape[1]==3:420 transformer.set_transpose('data', (2,0,1))421 if norm_type == '1' or norm_type == '4' and os.path.isfile(meanfile): # (sub mean by meanfile): 422 if net.blobs['data'].data.shape[1]==3:423 transformer.set_mean('data',np.load(meanfile).mean(1).mean(1))424 elif net.blobs['data'].data.shape[1]==1:425 tempMeanValue = np.load(meanfile).mean(1).mean(1)426 tempa = list(tempMeanValue)427 inputs = inputs - np.array(list(map(float, [tempa[0]])))428 elif norm_type == '2' or norm_type == '5':429 if net.blobs['data'].data.shape[1]==3:430 lmeanfile=meanfile.split(',')431 if len(lmeanfile) != 3:432 print("Please give the channel mean value in BGR order with 3 values, like 112,113,120")
433 sys.exit(1)434 if not isfloat(lmeanfile[0]) or not isfloat(lmeanfile[1]) or not isfloat(lmeanfile[2]):
435 print("Please give the channel mean value in BGR order")
436 sys.exit(1)437 else:438 transformer.set_mean('data',np.array(list(map(float,re.findall(r'[-+]?\d*\.\d+|\d+',meanfile)))))439 elif net.blobs['data'].data.shape[1]==1:440 lmeanfile=meanfile.split(',')441 if isfloat(lmeanfile[0]): # (sub mean by channel)442 inputs = inputs - np.array(list(map(float, [lmeanfile[0]])))443 444 elif norm_type == '3':445 inputs = inputs * float(data_scale)446 if img_filename.endswith('.txt') or img_filename.endswith('.float') or img_filename.endswith('.hex'):447 print (inputs.shape)448 data = inputs449 else:450 data = np.asarray([transformer.preprocess('data', inputs)])451 if norm_type == '4' or norm_type == '5':452 data = data * float(data_scale)453 454 data_reshape= np.reshape(data,net.blobs[list(net.blobs.keys())[0]].data.shape)455 net.blobs[list(net.blobs.keys())[0]].data[...] = data_reshape.astype('float')456 out = net.forward()457 save_result(train_net, net, output_dir)458 #print_CNNfeaturemap(net, output_dir)459 sys.exit(0)460 if __name__=='__main__':461 main(sys.argv[1:])
运行结束后会在data文件夹下生成一个output文件夹,其中存储了中间层输出结果B,cmder输入命令:(在mobilefacenet/data目录下)注意:此处-i参数选择的图片为上面生成mobileface_func.wk时imageList.txt的最后一张照片#key#
python CNN_convert_bin_and_print_featuremap.py -i .\images\10_MariaCallas_28_f.jpg -m mobilefacenet.prototxt -w mobilefacenet.prototxt.caffemodel -s 0.0078125 -n 5 -p "128","128","128"
5、中间层数据比较文件配置与结果
点击Vector Comparision,配置如下:
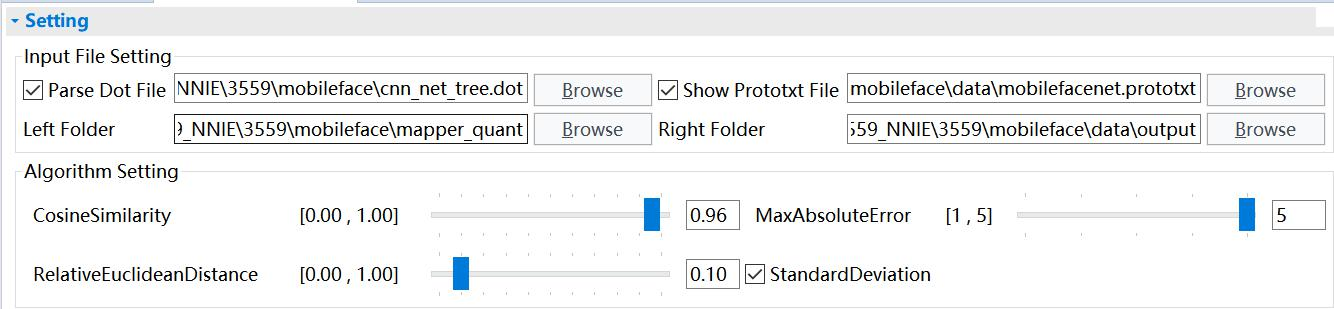
配置注意事项:
(1)Parse Dot File选择主目录下的cnn_net_tree.dot,Prototxt File为data目录下的mobilefacenet.prototxt;
(2)Left Folder和Right Folder分别选择mapper_quant文件夹和data/output文件夹;
(3)等待数据加载完成后点击compare即可开始对比;
测试结果:通过Vector Comparison进行数据对比,可以发现量化成功了,最终输出结果为0.991,然后中间有些层偏差比较大,怀疑可能是NNIE的层处理与caffe有所不同,这种误差可能可以通过merge_batchnorm操作消除,具体如下: