
字符串匹配算法(一)
字符串匹配算法(一)
字符串匹配在工作中我们经常会用到,同时也是各大公司面试中的常考题目。字符串匹配的算法有很多,所以需要深入学习的东西也有很多。我们接下来会有一系列的文章去把字符串匹配算法尽量说明白。
今天我们主要聊一下单模式串匹配算法---即一个串去跟另外一个串去比较。在开始之前,为了后续方便讲解,我们先明确两个定义,即主串和模式串。如果我们要在长度为n的字符串A中查找长度为m字符串B,那么A就是主串,B就是模式串,其中n>m。我们先从最简单的BF算法说起。
BF算法
BF算法也叫做暴力匹配算法,也是最直接、简单的算法。所谓的暴力匹配算法,就是固定主串,然后模式串一步步向前移动,一位一位的对比,直到在主串中找到相匹配的子串。如下图所示。
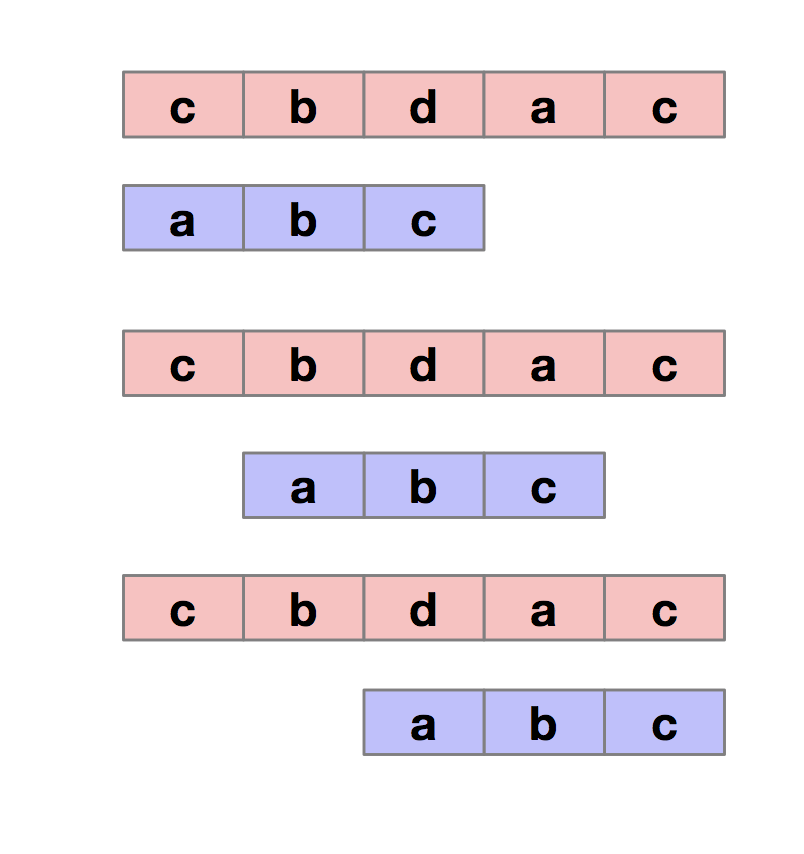
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | def bf(a, b): n= len(a) m= len(b) if n <= m: return 0 if b== aelse -1 for iin range(n-m+1): for jin range(m): if a[i+j]== b[j]: if j== m-1: return i else: continue else: break return -1if __name__== '__main__': a= 'cbdac' b= 'ac' start=bf(a, b) print('result:', start)#####输出####result:3 |
从上面的代码我们可以看出,这种算法的最坏情况时间复杂度是 O(n*m)。
RK算法
RK算法的全称叫Rabin-Karp算法。是由它的两位发明者 Rabin 和 Karp 的名字来命名的。RK算法的思想就是通过比较2个字符串的Hash值来判断字符串是不是相等的。我们在BF算法中,如果主串的长度是n,模式串的长度是m,我们需要暴力的比较n-m+1个子串和模式串,来找出主串和模式串相匹配的子串。在子串和模式串比较的时候,需要一位一位的对比,所以BF算法的时间复杂度较高,是O(N*M)。而RK算法的思路是:通过哈希算法把n-m+1个子串分别求hash值,然后再和模式串的hash值比较大小。如果某个子串的哈希值和模式串相等。那就说明对应的子串和模式串相匹配了(我们先忽略哈希冲突的情况)。因为hash值的比较是非常快速的,所以子串和模式串比较的效率就提高了。如下图所示。
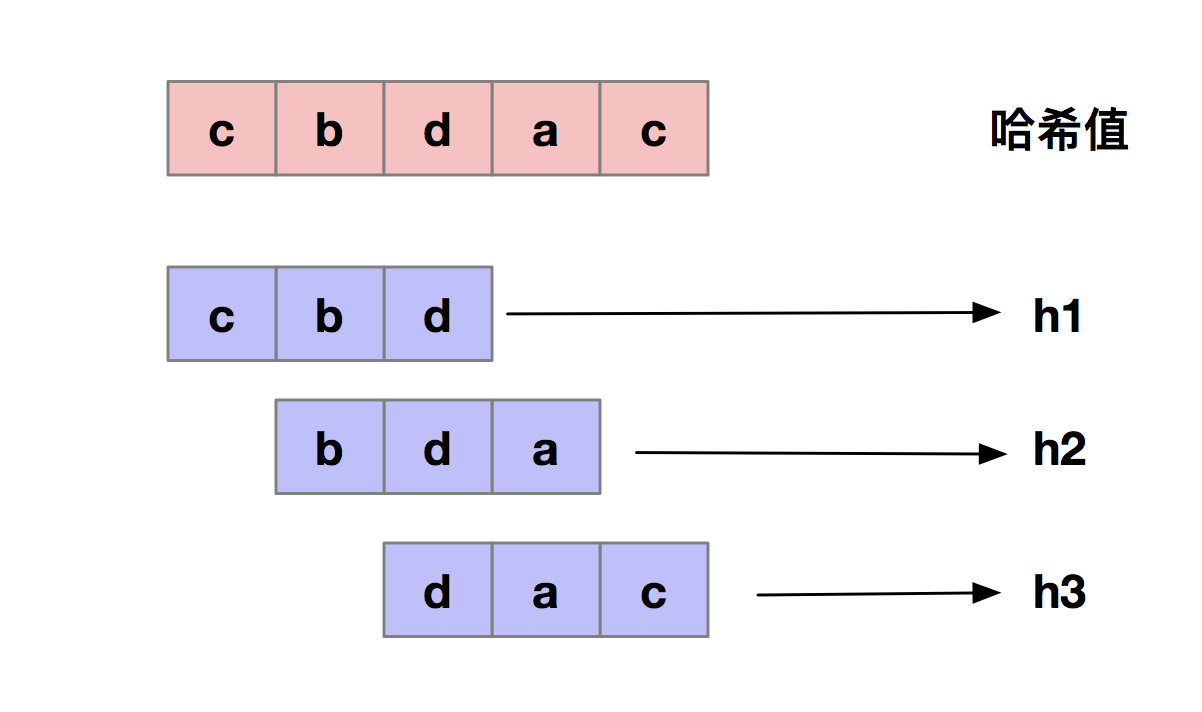
不过,通过哈希算法计算哈希值的时候,是需要遍历子串中的每个字符。虽然子串和模式串比较的效率提高了,但是算法的整体效率却没有提高,那如何提高哈希算法计算子串哈希值的效率呢?这就需要设计一个更高效的哈希算法。我们假设要匹配的字符串的字符集中只包含K个字符,我们可以用一个K进制数来表示一个子串,这个K进制数转化成十进制数,作为子串的哈希值。我们举个例子来说明一下。假如我们要处理的字符串只含有a~z这26个小写字母,我们把a~z映射到0~25这26个数字中,a表示0,b表示1,依次类推。所以字符串"cdb"的哈希值为:
1 | Hash("cdb")=c*26*26+d*26+b=2*26*26+3*26+1=1431 |
这种哈希算法有一个特点,就是在主串中,相邻两个子串S[i-1]和S[i](其中i表示子串在主串中的起始位置),对应的哈希值的计算公式是有交集的,也就是说我们可以根据S[i-1]的哈希值,很快的计算出S[i]的哈希值。我们来用公式表示一下。
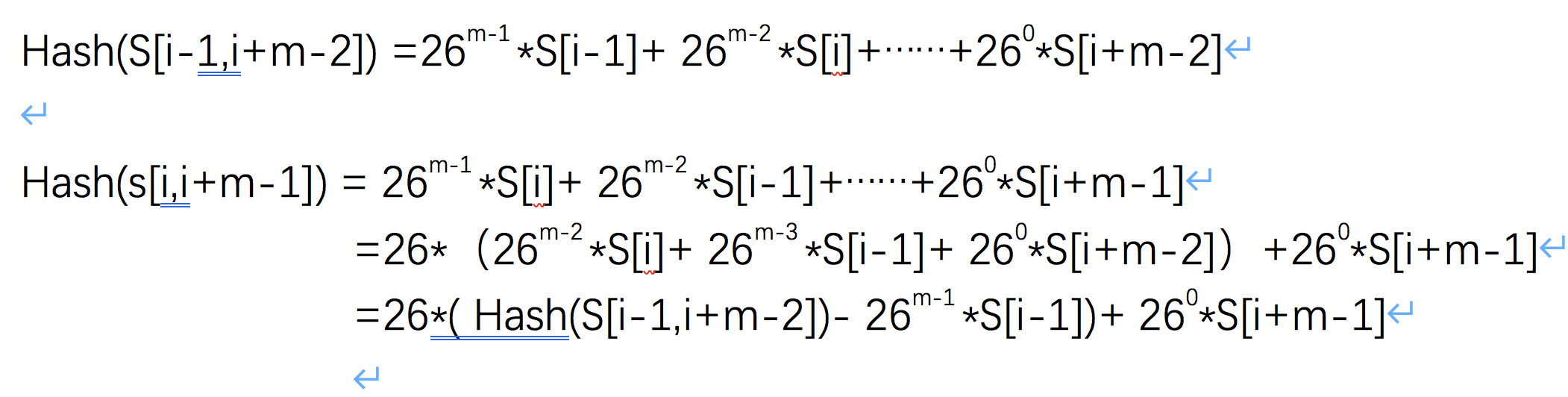
我们可以把26^0、26^1、26^2......26^(m-1)先计算出来,并且存储在一个长度为m的数组中,公式中的“次方”就对应数组的下标。当我们需要计算26的x次方的时候,就可以从数组的下标为x的位置取值,直接使用,这样我们就省去了计算的时间。
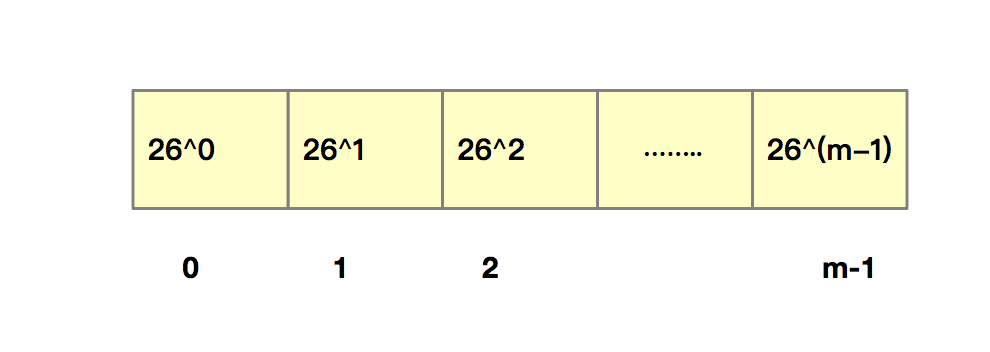
RK算法中主要包括计算子串的哈希值和模式串哈希值与子串哈希值之间的比较。由于我们可以通过设计特殊的哈希算法,只需要扫描一遍主串就能计算出所有子串的哈希值了,所以计算子串哈希值的时间复杂度为O(n)。
模式串哈希值与每个子串哈希值之间的比较的时间复杂度是O(1),总共需要比较 n-m+1 个子串的哈希值,所以,这部分的时间复杂度也是 O(n)。所以,RK 算法整体的时间复杂度就是 O(n)。
还有一个问题需要注意,如果我们通过上面计算哈希值的方法计算的哈希值太大,超过了计算机表示的范围,那我们该如何解决呢?刚刚我们设计的哈希算法是没有散列冲突的,也就是说,一个字符串与一个二十六进制数一一对应,不同的字符串的哈希值肯定不一样。实际上,我们为了能将哈希值落在整型数据范围内,可以牺牲一下,允许哈希冲突。这个时候哈希算法该如何设计呢?其实很简单,我们可以对一个大的素数取模。这样的话就会带来hash冲突的问题,如果有哈希冲突的话,我们在发现一个子串的哈希值跟模式串的哈希值相等的时候,还需要去对比一下子串和模式串本身。
好了,我们今天就先聊到这里,下篇文章我们再来聊一下更高效的字符串匹配算法BM算法和KMP算法。
来源https://www.cnblogs.com/laohanshuibi/p/15082863.html