
实例复习机器学习数学 - 2. 几种典型离散随机变量分布
实例复习机器学习数学 - 2. 几种典型离散随机变量分布
随机变量的引入
上一节我们讨论的都是随机事件,某一个随机事件可能包含若干个随机试验样本空间中的随机结果,如果对于每一个可能的实验结果都关联一个特定的值,这样就形成了一个随机变量。
例如抛一个骰子,将抛出的骰子的值作为随机变量的值;足球比赛,将某一只球队进球的个数作为随机变量的值;抛一根标枪,抛出的距离作为随机变量的值;今年一年的降水量作为随机变量等等。
离散型随机变量相关概念
随机变量的取值并不是连续的,而是有限个数值,或者是可以计数的无限个数值,这样的随机变量被称为离散随机变量。回顾一下上面提出的四个例子,投一个骰子,将抛出的骰子的值作为随机变量的值,这些值只可能是 1,2,3,4,5,6,所以是离散随机变量分布;足球比赛,将某一只球队进球的个数作为随机变量的值,这个进球数可能是无限个,只不过数值很大的时候概率很低而已,这也是离散随机变量分布。但是对于抛一根标枪,抛出的距离作为随机变量的值和今年一年的降水量作为随机变量这些是无法计数的,被称为连续随机变量。
对于离散随机变量,搞清楚每个值的概率也是很重要的,将随机变量的每个值映射到其概率上,这就是概率质量函数(PMF).记随机变量为 X,PMF 为 P(X=k)。接下来,我们就来详细说明几种典型的随机变量以及其概率质量函数。
只有两种可能的多次实验分布 - 二项分布
我们有如下几个例子:
射门 n 次,假设进球概率为p,每次射门彼此之间都是相互独立的,随机变量 X 对应 n 次射门进球的次数。
投一个硬币 n 次,假设正面朝上的概率为 p,每次抛掷彼此之间都是相互独立的,随机变量 X 对应 n 次抛掷得到的是正面的次数。
坐某个航班的飞机,假设准点到达的概率为p,每次这个航班到达彼此之间都是相互独立的,随机变量 X 对应 n 次航班准点的次数。
以上这些例子中,都可以理解为在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能:发生或者不发生。我们假设该项试验独立重复地进行了 n 次,那么就称这一系列重复独立的随机试验为 n 重伯努利试验。n 重伯努利试验结果的分布就是二项分布
二项分布的 PMF为:
P(X=k)=Cknpk(1−p)n−k
根据 PMF 推导期望与方差,假设伯努利实验的随机变量只有两个值 0(不发生),1(发生),那么 n 次试验的期望为:
E[X]=1C1np(1−p)n−1+2C2np2(1−p)n−2+...+(n−1)Cn−1npn−1(1−p)+nCnnpn
根据 kCkn=nCk−1n−1,则有:
E[X]=nC0n−1p(1−p)n−1+nC1n−1p2(1−p)n−2+...+nCn−2n−1pn−1(1−p)+nCnnpn
=np(C0n−1(1−p)n−1+C1n−1p1(1−p)n−2+...+Cn−2n−1pn−2(1−p)+Cnnpn−1)
=np∑k=0n−1Cn−1−kn−1pk(1−p)n−1−k
根据 $(p+q)^n = C_n0pnq^0 + C_n1p{n-1}q^{1} +... + C_n{n-1}p{1}q^{n-1} + C_nnp0q^n = \sum_{k=0}{n}C_{n}{n-k}p{n-k}qk $,则有:
E[X]=np(1−p+p)n−1=np
n 次试验的方差为:
D[X]=E(X−E[X])2=E[X2−2xE[X]+E[X]2]=E[X2]−2E[X]E[X]+E[X]2=E[X2]−E[X]2
其中 E[X2] 为
E[X2]=12C1np(1−p)n−1+22C2np2(1−p)n−2+...+(n−1)2Cn−1npn−1(1−p)+n2Cnnpn
=∑k=0nk2Cknpk(1−p)n−k
根据 k2Ckn=knCk−1n−1=(k−1+1)nCk−1n−1=n(k−1)Ck−1n−1+nCk−1n−1=n(n−1)Ck−2n−2+nCk−1n−1,则有:
E[X2]=n(n−1)∑k=0nCk−2n−2pk(1−p)n−k+n∑k=0nCk−1n−1pk(1−p)n−k
设 k+j=n,则有:
E[X2]=n(n−1)∑j=0nCn−j−2n−2pn−j(1−p)j+n∑j=0nCn−j−1n−1pn−j(1−p)j
=n(n−1)p2∑j=0nCn−j−2n−2pn−j−2(1−p)j+np∑j=0nCn−j−1n−1pn−j−1(1−p)j
=n(n−1)p2(p+1−p)n−2+np(p+1−p)n−1=n(n−1)p2+np
则:
E[X2]−E[X]2=n(n−1)p2+np−n2p2=n2p2−np2+np−n2p2=np−np2=np(1−p)
接下来我们通过一个小程序来直观感受下二项分布:
from scipy.stats import binomimport matplotlib.pyplot as pltimport numpy as npimport seaborn#我个人比较喜欢这个主题seaborn.set_style("whitegrid")#使用内置库 binom 模拟 n = 10, p = 0.3 的情况,随机 100000 次binom_sim = data = binom.rvs(n=10, p=0.3, size=100000)#计算本次平均值以及标准差print ("Mean: %g" % np.mean(binom_sim))print ("Std: %g" % np.std(binom_sim, ddof=1))#绘图,利用归一化的直方图,这样展示的很接近概率质量函数plt.hist(binom_sim, bins=10, density=True, stacked=True)plt.show()可以看到输出为:
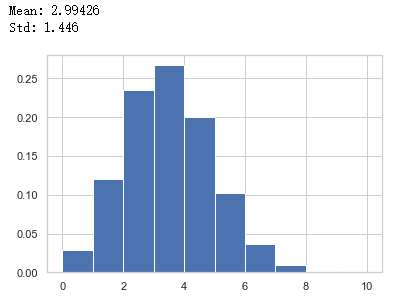
可以看到平均值很接近期望,标准差也是很接近我们用公式算出来的方差开根。
发生概率与试验次数相比很小的二项分布 - 泊松分布
当 n 比较大, p 比较小的时候,二项分布可以近似为 泊松分布。
由此可以推导出,泊松分布的期望方差为:
E[X]=np=λ
D[X]=np(1−p)=np∗1=np=λ
泊松分布的 PMF 为:
P(X=k)=limn→∞,p→0Cknpk(1−p)n−k=limn→∞,p→0n(n−1)...(n−k+1)k!pk(1−p)(n−k)
=limn→∞,p→0n(n−1)...(n−k+1)k!(λ/n)k(1−λ/n)(n−k)
分别来看每一部分:
limn→∞,p→0n(n−1)...(n−k+1)=nk
由于 n 趋近于无穷,所以
limn→∞(1+xn)n=ex
所以有:
limn→∞,p→0(1−λ/n)n=e−λ
最后:
limn→∞,p→0(1−λ/n)k=1k=1
合并带入:
limn→∞,p→0n(n−1)...(n−k+1)k!(λ/n)k(1−λ/n)(n−k)
=limn→∞,p→0nkk!λknke−λ
=λkk!e−λ
为何要近似为泊松分布呢?在生活中我们会根据历史数据来预测结果,同时有很多事件可以抽象为泊松分布,例如:
预测两只球队的胜平负结果,可以通过预测两只球队的进球情况。可以将两只球队进球概率设为 p,每次射门就是一次独立重复随机试验,那么这个试验结果应该符合二项分布。但是,预测进球概率是很难的,但是,我们可以通过历史数据来算出来这个球队的平均进球数,也就是 λ。同时,进球概率相对于射门次数来说,也是比较小的,可以近似为泊松分布。这样,我们就能通过泊松分布以及 λ 来计算出进 k 个球的概率。取两个球队进球数的概率分布列,计算胜平负结果的概率。
预测当天飞机晚点的次数。同样的,晚点概率相对于航班次数来说,是很小的,并且,晚点概率我们很难预测,但是可以通过历史数据得出平均晚点次数,抽象为泊松分布就可以算出晚点次数为 k 的概率。
对于这种,推测概率很难,但是可以通过历史数据描述其期望的,我们一般通过抽象为泊松分布来计算它的先验概率。
接下来我们继续通过程序模拟:
from scipy.stats import poissonimport matplotlib.pyplot as pltimport numpy as npimport seaborn#我个人比较喜欢这个主题seaborn.set_style("whitegrid")#使用内置库 poisson 模拟 λ=5 的情况,随机 10000 次poisson_sim = poisson.rvs(mu=5, size=10000)#计算本次平均值以及标准差print ("Mean: %g" % np.mean(poisson_sim))print ("Std: %g" % np.std(poisson_sim, ddof=1))#绘图,利用归一化的直方图,这样展示的很接近概率质量函数plt.hist(poisson_sim, density=True, stacked=True)
plt.gca().axes.set_xticks(range(0, 11))
plt.show()输出为: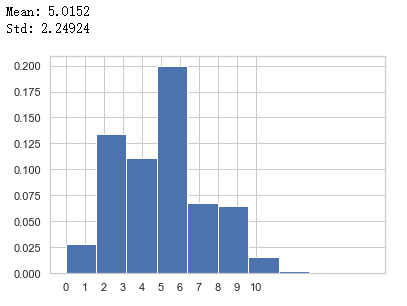
直到事件发生为止的分布 - 几何分布
类比二项分布的例子,我们稍微做下修改:
射门 n 次,假设进球概率为p,每次射门彼此之间都是相互独立的,直到射门射进为止,随机变量 X 对应射门进球是第几次。
投一个硬币 n 次,假设正面朝上的概率为 p,每次抛掷彼此之间都是相互独立的,直到抛出的硬币是正面为止,随机变量 X 对应抛掷得到的是正面是第几次。
坐某个航班的飞机,假设准点到达的概率为p,每次这个航班到达彼此之间都是相互独立的,随机变量 X 对应 n 次航班准点的次数。
这些随机变量的分布就是几何分布,其 PMF 为:
P(X=k)=p(1−p)k−1
根据 PMF 推导期望与方差,假设伯努利实验的随机变量只有两个值 0(不发生),1(发生),那么期望为:
E[X]=p+2p(1−p)+3p(1−p)2+...+np(1−p)n−1
(1−p)E[X]=p(1−p)+2p(1−p)2+3p(1−p)3+...+np(1−p)n
E[X]−(1−p)E[X]=p+p(1−p)+p(1−p)2+...+p(1−p)n−1−np(1−p)n
pE[X]=p1−(1−p)n1−(1−p)−np(1−p)n
E[X]=1−(1−p)n1−(1−p)−n(1−p)n
当 n 趋近于无穷的时候:
E[X]=1p
方差为:
D[X]=E[X2]−E[X]2
E[X2]=p+22p(1−p)+32p(1−p)2+...+n2p(1−p)n−1
E[X2]p=1+22(1−p)+32(1−p)2+...+n2(1−p)n−1
假设 q = 1-p,则有:
E[X2]1−q=1+22q+32q2+...+n2qn−1
根据求导公式,则有:
E[X2]1−q=(q+2q2+3q3+...+nqn)′
根据推导期望的结果,可以知道:
q+2q2+3q3+...+nqn=E(X)(q)1−q=q(1−q)2
根据求导公式[f(x)/g(x)]′=[f′(x)g(x)−f(x)g′(x)]/[g(x)]2,则有:
E[X2]1−q=(q(1−q)2)′=(1−q)2−((1−q)2)′q(1−q)4=1−2q+q2−(−2q+2q2)(1−q)4=1−q2(1−q)4=1+q(1−q)3
则:
E[X2]=1+q(1−q)2=2−pp2
则:
D[X]=E[X2]−E[X]2=2−pp2−1p2=1−pp2
接下来我们继续通过程序模拟:
from scipy.stats import geomimport matplotlib.pyplot as pltimport numpy as npimport seaborn#我个人比较喜欢这个主题seaborn.set_style("whitegrid")#使用内置库 geom 模拟 p = 0.5 的情况,随机 100000 次geom_rv = geom(p=0.5)
geom_sim = geom_rv.rvs(size=100000)#计算本次平均值以及标准差print ("Mean: %g" % np.mean(geom_sim))print ("Std: %g" % np.std(geom_sim, ddof=1))#绘图,利用归一化的直方图,这样展示的很接近概率质量函数plt.hist(geom_sim, bins=20, density=True, stacked=True)#设置要显示的坐标值plt.gca().axes.set_xticks(range(1,11))
plt.show()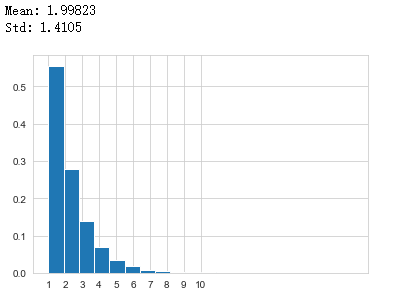
根据公式计算出的期望为 1p=2,与模拟的接近。根据公式计算出方差为 1−pp2=2,标准差约为 1.41421 也和模拟的接近。
来源https://www.cnblogs.com/zhxdick/p/15010143.html