
用户RFM模型及应用
用户RFM模型及应用
RMF含义
R(Recency)(用户粘性,越小越好):用户最近一次交易时间的间隔。R值越大,表示用户交易发生的日期越久,反之则表示用户交易发生的日期越近
F(Frequency)(用户忠诚度,越大越好):用户在最近一段时间内交易的次数,F值越大,表示客户交易越频繁,反之则表示用户交易不够活跃。
M(Monetary)(用户贡献度,越大越好):用户在最近一段时间内交易的金额。M值越大,表示用户价值越高,反之则表示用户价值越低。
| R | F | M | 用户群体类型 |
|---|---|---|---|
| 0 | 1 | 1 | 重要价值用户 |
| 1 | 1 | 1 | 重要唤回用户 |
| 0 | 0 | 1 | 重要深耕用户 |
| 1 | 0 | 1 | 重要挽留用户 |
| 0 | 1 | 0 | 潜力用户 |
| 1 | 1 | 0 | 一般维持用户 |
| 0 | 0 | 0 | 新用户 |
| 1 | 0 | 0 | 流失用户 |
用户RMF模型的用途
针对不同类型用户,提出可落地的策列建议,采取不同运营手段措施。
用户RMF模型处理思路
以电商数据为例
1、确认待分析数据
不同业务R、F、M指标定义不同。
例如:
在电商销售案例中,通过最后一次消费时间间隔(R)、消费频率(F)和消费金额(M)进行定义;
在用户使用产品案例中,通过用户最后一次使用的时间间隔(R)、使用频率(F)、和对产品功能的使用(M)进行定义;
在借贷平台的与其用户案例中,通过最后一次进入还款页面的时间间隔(R)、进入还款页面的次数(F)、应还款的账单金额(M)进行定义
| 值 | 计算方法 | 计算需要的数据 |
|---|---|---|
| R | 最后一次订单日期据今天(或设定时间)的间隔 | 用户ID、订单日期 |
| F | 一年内用户下单次数 | 用户ID |
| M | 一年内用户下单总额 | 用户ID、销售额 |
2、计算需要的数据
3、给R、F、M按值划分高低维度
方法一:平均值
平均值作为依据进行划分,(R值计算的大小和用户价值呈反比,故高于依据的作为低值)
注:由于大部分数据呈长尾分布,导致平均数被拔高或压低,此时以平均数作为参考并不合适。例如:有一用户的消费金额达到100K,普遍用户消费1K,此时平均值被拔高。
方法二:中位数或四分位数(推荐)
选择四分位数作为依据进行划分,(R值计算的大小和用户价值呈反比,故高于依据的作为低值)
4、量化用户价值
将RFM总值量化为用户价值
方法一:字符串对应法
方法二:数值计算法
将R、F、M三组数据分别无量纲化处理映射到[0,1]区间再合理放大然后相加。(即跳过了给第三步给RFM划分高低维度的步骤)
无量纲化处理具体原理和方法
min-max归一化
公式:x′=x−minmax−min
通过无量纲化处理将不同量级的数据归一化至同一量级,一般将该数放大100倍
RFM计算公式:RFM总值 = R值 * (-1) + F值 + M值 +100
注:-1是由于R值大小和用户质量成反比,+100是为了保证数据结果不会出现负数,该数不是固定的,如果RFM归一化未放大100倍,此处+1即可
RFM模型案例
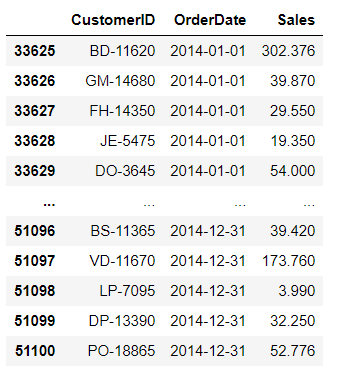
现有一电商销售订单的数据表,使用用户RFM模型对用户数据进行分析
# 以2014年为时间段,计算F、M值# 获取2014年数据df_14 = df[df['Order_Year']==2014]''' |R|最后一次订单日期据今天(或设定时间)的间隔|用户ID、订单日期| |F|一年内用户下单次数|用户ID| |M|一年内用户下单总额|用户ID、销售额| 提取出需要的数据 '''df_14=df_14[['CustomerID','OrderDate','Sales']] df_14
# 将用户ID作为索引df_14.set_index('CustomerID',inplace=True)# 为了计算F,增加一列(因为需要累计同一用户订单个数df_14['orders'] = 1# 将同一用户的订单最大时间、下单次数总合、下单总额以数据透视表的方式计算并保存customer_pivot = pd.pivot_table(df_14,
index = 'CustomerID',
values=['OrderDate','orders','Sales'],
aggfunc={'OrderDate':'max', 'orders':'sum', 'Sales':'sum'})# R 以所用用户中最后下单的时间作为分析开始的一天customer_pivot['R'] = (customer_pivot.OrderDate.max()-customer_pivot.OrderDate).dt.days# F# 新建一个F列,或者可以直接将orders列进行重命名(customer_pivot.rename(columns=,inplace=)customer_pivot['F'] = customer_pivot.orders# Mcustomer_pivot['M'] = customer_pivot.Sales
customer_pivot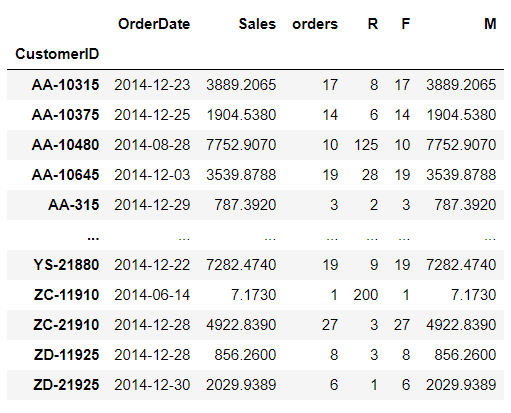
# 给RFM划分高低维度def func(x):
# 根据正负,标记1,0
# level是一个DataFrame类型分别有R、F、M三列
level = x.apply(lambda x:'1' if x >=0 else '0') # 将RFM值拼成一列 label是Series类型
label = level.R+level.F+level.M
# 构建字典 量化用户价值
d = { '011':'重要价值用户', '111':'重要唤回用户', '001':'重要深耕用户', '101':'重要挽留用户', '010':'潜力用户', '110':'一般维持用户', '000':'新用户', '100':'流失用户'
}
result = d[label] return result# 以中位数方式划分维度,以字符串对应法量化用户价值customer_pivot['label']=customer_pivot[['R','F','M']].apply(lambda x:x-x.median()).apply(func,axis=1)
customer_pivot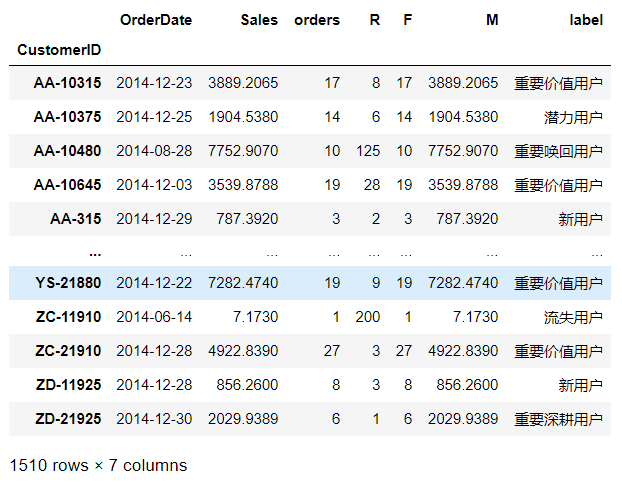
来源https://www.cnblogs.com/Wendy-r/p/14961692.html