
CNN经典模型——VGGNet
VGGNet出自论文《Very Deep Convolutional Networks For Large-Scale Image Recognition》。
VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间,但是这个模型很有研究价值。
模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。
VGG各种网络的网络结构如表1所示。
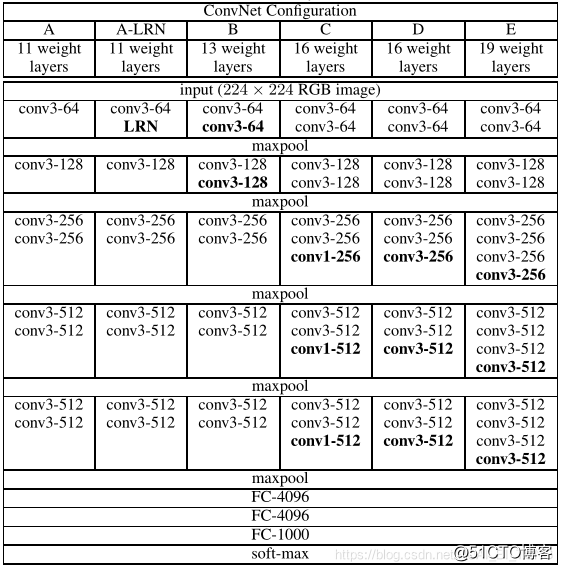
其中,网络结构D就是著名的VGG16,它包含了13个卷积层和3个全连层;网络结构E就是著名的VGG19,它包含了16个卷积层和3个全连层。
VGG结构由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大池化)分开,所有隐层的激活单元都采用ReLU函数。VGG最大的贡献就是证明了卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。
在VGG中,使用了3个3×3卷积核来代替7×7卷积核,使用了2个3×3卷积核来代替5×5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。作者认为两个3×3的卷积堆叠获得的感受野大小,相当一个5×5的卷积;而3个3×3卷积的堆叠获取到的感受野相当于一个7×7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7×7的参数为49个,而3个3×3的参数为27)。
VGG网络探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16-19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
以VGG16网络为例,介绍其各层的处理过程,VGG16的网络结构如图1所示,也可点击查看更加形象化的VGG16网络。
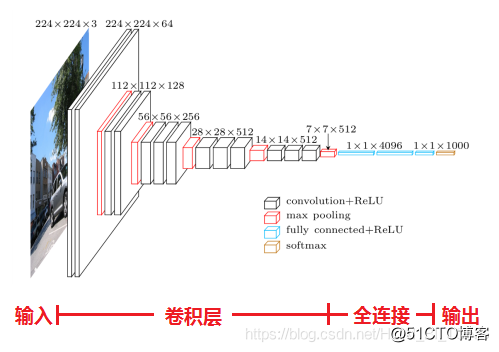
VGG16各层的处理过程:
输入224×224×3的图片,经64个3×3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224×224×64;
作max pooling(最大化池化),池化单元尺寸为2×2(效果为图像尺寸减半),池化后的尺寸变为112×112×64;
经128个3×3的卷积核作两次卷积+ReLU,尺寸变为112×112×128;
作2×2的max pooling池化,尺寸变为56×56×128;
经256个3×3的卷积核作三次卷积+ReLU,尺寸变为56×56×256;
作2×2的max pooling池化,尺寸变为28×28×256;
经512个3×3的卷积核作三次卷积+ReLU,尺寸变为28×28×512;;
作2×2的max pooling池化,尺寸变为14×14×512;
经512个3×3的卷积核作三次卷积+ReLU,尺寸变为14×14×512;
作2×2的max pooling池化,尺寸变为7×7×512;
与两层1×1×4096,一层1×1×1000进行全连接+ReLU(共三层);
通过softmax输出1000个预测结果。
VGG网络的优缺点:
VGG优点: VGG网络的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3×3)和最大池化尺寸(2×2);几个小滤波器(3×3)卷积层的组合比一个大滤波器(5×5或7×7)卷积层好;验证了通过不断加深网络结构可以提升性能。
VGG缺点:VGG耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。
©著作权归作者所有:来自51CTO博客作者๑~夏时~๑的原创作品,如需转载,请注明出处,否则将追究法律责任