
ESP内生转化概率模型是什么, 如何做, 如何解释, 为什么需要它?
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
正文
关于下方文字内容,作者:蒋泽鸿,英国南安普敦大学经济学,通信邮箱:jiangzehonguk@163.com
作者之前的文章:①万能cmp程序, 有了他, 建议把其他程序全删掉!②弹性DID, DID的终极大法, 关于DID各方法总结太赞了!
与ESP相关的内容:1.内生转换模型vs内生处理模型vs样本选择模型vs工具变量2SLS,2.Heckman模型out了,内生转换模型掌控大局
一、ESP 内生转化概率模型简介
在内生转化概率模型中,一个转化等式将个体分为两种状态,每一个观察到的个体只属于其中一种状态。在拟合具有二值内生回归量的内生转化模型时,容易出现计量方面的问题。例如,Lokshin and Glinskaya (2009),它分析了尼泊尔男性移民对女性在劳动力市场行为的影响,其结果表明,男性移民对留下的女性劳动力参与率水平有消极影响。但是,这篇文章在分析男性移民的影响时,基于可观测和不可观测的特征,发现了大量异质性问题。除此之外,这类计量问题还出现在研究房产需求和市场失衡等方向。
内生转化概率模型可以通过两个heckprob估计,或者通过最大似然估计,一次拟合一个分支,即选择方程或结果方程(请参见[R] biprobit和[R] heckprob)。然而,这两种方法效率都不高,并且biprobit命令具有局限性,因为它假定两种干预状态的结果方程中的系数相等。由此发展出了通过switch_probit命令对此类模型进行拟合。
二、switch_probit命令简介
switch_probit命令利用充分信息最大似然估计法,同时估计模型的二值选择和二值结果部分,可以产生一致的标准误差的估计值。该方法依赖于选择方程和结果方程中误差项的联合正态性假设。在估计完模型的参数后,switch_probit命令还可以得出平均干预效应(ATE),处理组的平均干预效应(ATT),对照组的平均干预效应(ATU),边际干预效应(MTE)的结果。
switch_probit命令作为一个d2最大似然估计量被执行,由此得出总体对数似然值及其一阶和二阶导数。该命令可以执行weight, cluster, robust以及所有与Stata最大似然估计程序相关的所有选项。该命令的通用语法如下:(与movestay命令的语法相似)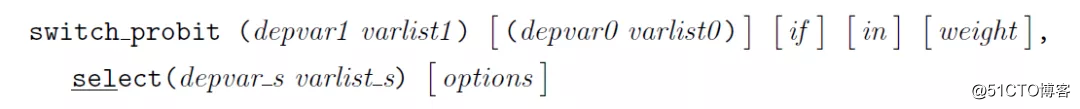
depvar1:状态1中的二值结果变量
varlist1:状态1的结果方程中的解释变量集
depvar0:状态0中的二值结果变量
varlist0:状态0的结果方程中的解释变量集
depvar_s:选择方程中的二值因变量
varlist _s:选择方程中的解释变量集
另外,switch_probit命令的结果有特定的保存形式,即e( )。例如,e(k)表示参数的数量,e(depvar)表示因变量的名称, e(sample)表示标记的估计样本。
在switch_probit命令执行后,通常还会利用predict命令计算预测的统计值。这个统计值可以来自样本内外,例如输入“predict … if e(sample) …”表示产生的统计值仅针对估计的样本内。其在Stata中的通用语法如下: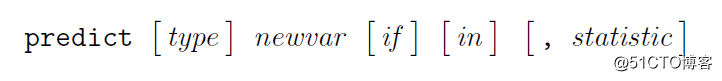
三、案例分析
下面将运用swtich_probit命令,分析丈夫移民对妻子劳动力参与率的影响。模型建立如下: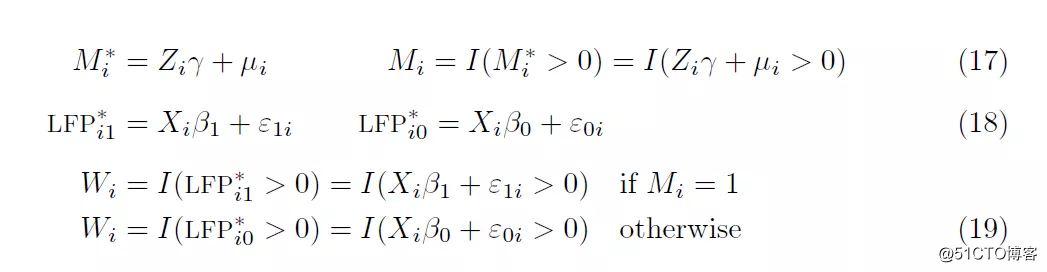

在这类模型中经常会做这样的假设,妻子决定进入劳动力市场对于其丈夫决定移民是内生的。一些无法观察的特征,会影响丈夫移民的可能性,也会影响妻子决定工作与否。如果忽略这些选择性影响,可能会对估计丈夫移民影响妻子劳动力参与率产生偏差。同时利用(17), (18) 和 (19) 进行最大似然估计,以及合适的移民决定工具变量可能会纠正这种偏差。
下面是运用swtich_probit命令进行最大似然估计,对该模型拟合所得到的结果: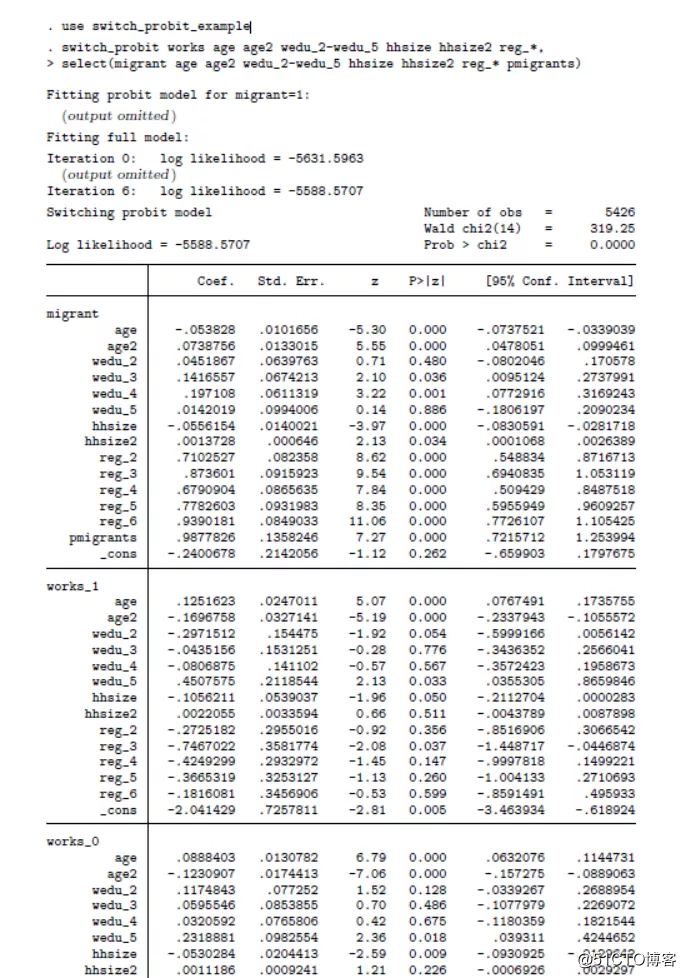
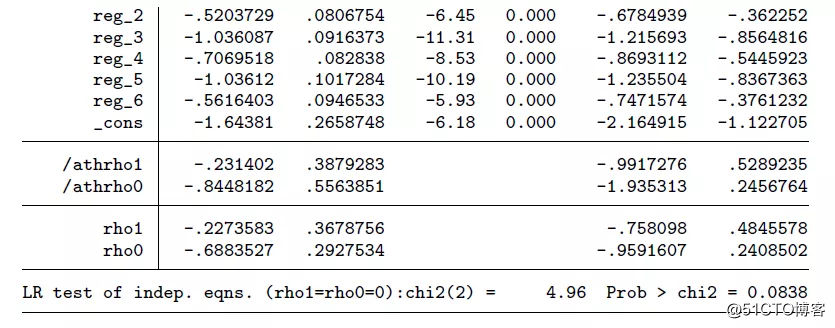
丈夫移民方程(17)的结果显示在表格上方的“migrant”部分。妻子劳动力参与率方程-状态1(18,其丈夫移民)的结果显示在“work_1”部分。妻子劳动力参与率方程-状态0(18,其丈夫未移民)的结果显示在“work_0” 部分。变量/athrho1和/athrho0是运用在最大似然估计过程的辅助参数。相关性系数rho1、rho0分别指的是丈夫移民方程(17)误差项与妻子劳动力参与率方程-状态1(18,其丈夫移民)误差项或妻子劳动力参与率方程-状态0(18,其丈夫未移民)误差项的相关性。输出结果的最后一行,显示了方程联合独立性的似然率检验结果,即拒绝原假设H0:rho1= rho0。另外,为了降低偏差,丈夫移民方程中(17)包含了一个工具变量“pmigrants”,即移民比例。通常认为,移民比例会影响丈夫是否移民,但不会影响妻子工作与否。
现在,我们利用predict命令得出处理组的干预效应,即将丈夫移民作为干预手段,分析丈夫移民对妻子劳动力参与率的影响。
结果表明,在丈夫移民的家庭中,其妻子工作的概率是11.6%。
四、蒙特卡罗模拟(Monte Carlo simulations)
下面将简要讨论模型中估计量的敏感性和有关误差项分布的假设。为了阐述估计量的性质,我们将对一系列模型设定进行蒙特卡罗模拟。
数据生成过程基于以下模型: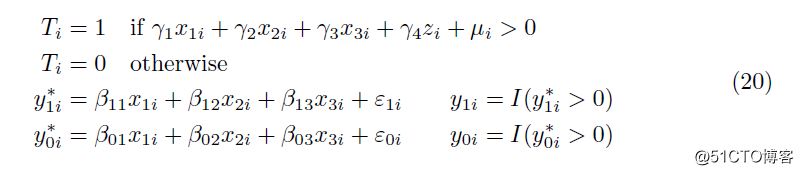
我们对10000个观测值(包含1000个重复值)的样本进行了四种环境下的蒙特卡罗模拟。在所有模拟中,我们显示了γi与βi的比率(i = 1,...,3),以确保不同模型设定之间的估计结果具有可比性。
x1,x2,x3和z作为独立的标准正态随机变量。下表的顶部面板显示了系数β和γ的真实值。
表1. 不同模型设定的蒙特卡罗模拟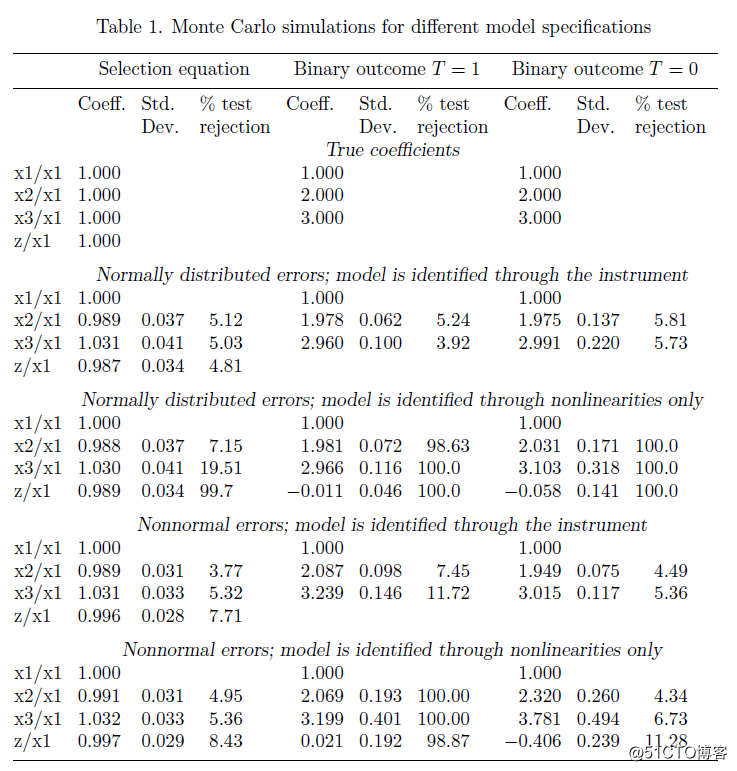
上述结果表明,本文描述的估计量在模型识别方面相对稳健。这个发现与Wilde(2000)的结论是一致的,即在具有内生虚拟回归变量的递归多方程概率模型中,如果数据有足够的变化,则不需要对外生变量设置排除性限制(exclusion restrictions)。
下面,我们还将通过预测ATE和ATT来评估估计量的表现。这些模拟中的数据生成过程与(20)中描述的数据生成过程相似,但是除了根据10000个观测值的显示结果外,我们还对200至30000个观测值的样本量生成了ATT和ATE。
图1显示了ATE和ATT的蒙特卡罗模拟结果,其模型设定具有正态分布的误差项和1000次重复值。结果表明,即使对于较小的样本量,该方法也可以有效且无偏地估计ATE和ATT。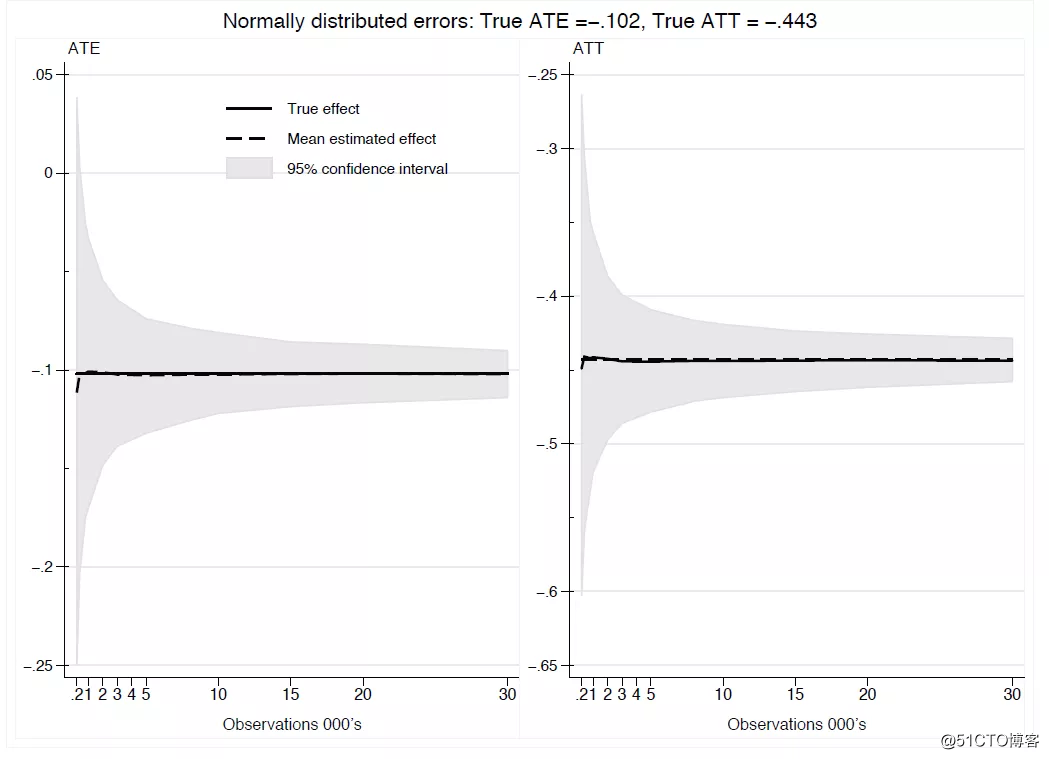
图1. ATE和ATT的蒙特卡罗模拟结果,其模型设定具有正态分布的误差项
图2显示了ATE和ATT的蒙特卡罗模拟结果,其模型设定具有非正态分布的误差项和1000次重复值。结果显示,违反正态性假设会导致ATE和ATT的估计偏差,尤其对基于较小样本量的估计,偏差较大。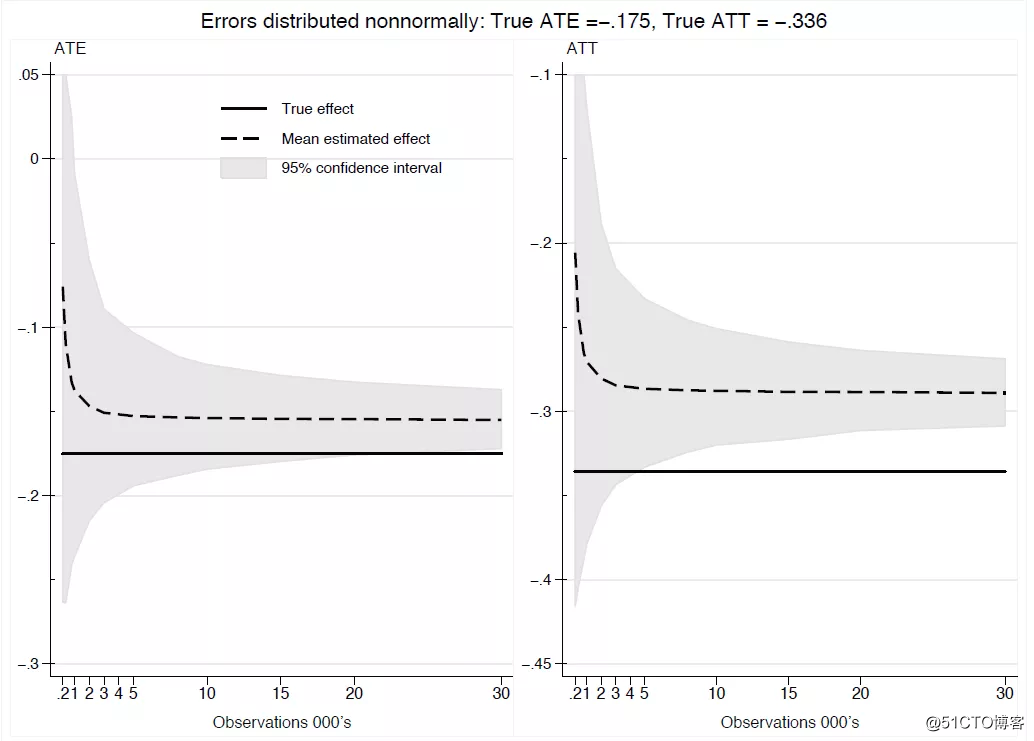
图2. ATE和ATT的蒙特卡罗模拟结果,其模型设定具有非正态分布的误差项
最后,我们将根据(20)中误差项的联合分布的假设来检验置信区间的有效性。图3显示了ATE和ATT的覆盖率。该覆盖率是针对(20)中具有正态分布(实线)和非正态分布误差项(虚线)的模型设定构造的。该模拟是基于ATE和ATT的置信区间的bootstrap估计,其重复值为1000个蒙特卡洛重复值的1000次重复,即最大似然模型估计的每个样本数量为1,000,000。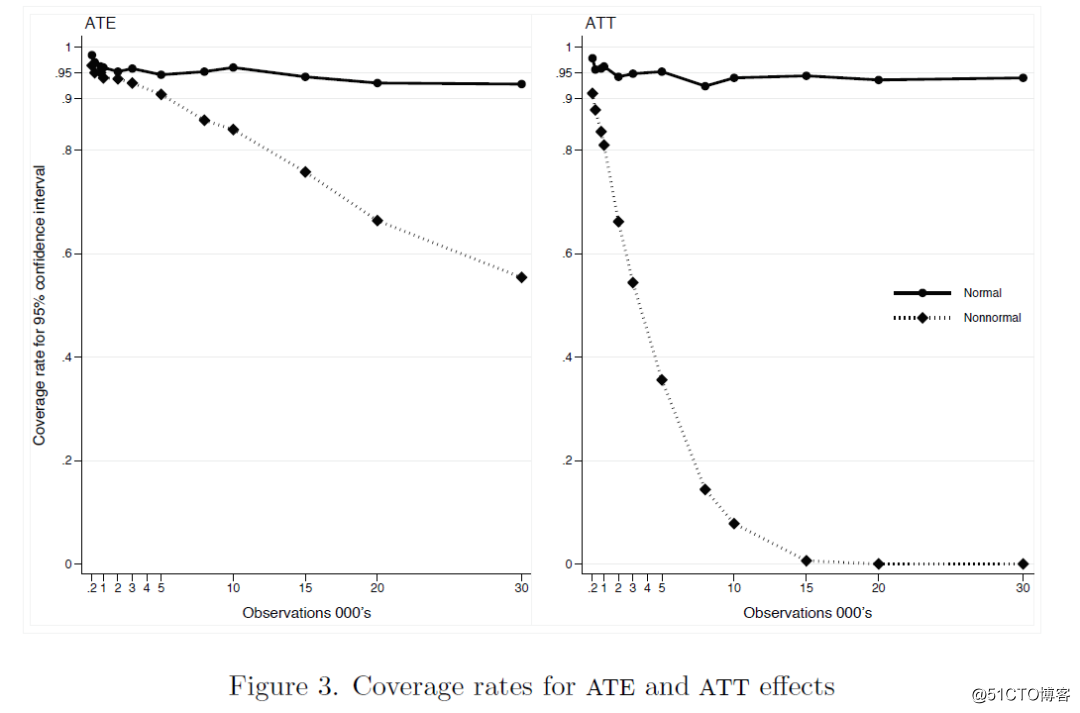
图3. ATE和ATT的覆盖率
图3与图2所示ATE和ATT的偏差和置信区间的结果一致。
五、总结
switch_probit命令扩展了Stata应用于内生转化模型的最大似然估计算法集,例如Lokshin和Sajaia(2004)提出的movestay命令。另外,这个命令根据不同分组产生的干预效应估计值的能力,对于影响评估(例如,上文所述的男性移民对留下的女性劳动力参与率水平的影响)具有不可忽视的实际价值。
上述三个不同方式的蒙特卡洛模拟的结果表明,虽然估计量在正态分布误差项的假设下表现良好,但如果违反正态性假设,则会产生估计偏差。如果研究者怀疑正态性假设不太可能成立,可能会对此类模型使用其他半参数或非参数估计方法。
参考文献:
Lokshin, M., and E. Glinskaya. 2009. The effect of male migration on employment patterns of women in Nepal. World Bank Economic Review 23: 481–507.
Lokshin, M., and Z. Sajaia. 2004. Maximum likelihood estimation of endogenous switching regression models. Stata Journal 4: 282–289.
Wilde, J. (2000). Identification of multiple equation probit models with endogenous dummy regressors. Economics Letters. 69: 309–312.
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
2.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
©著作权归作者所有:来自51CTO博客作者mb5fd86dae5fbf6的原创作品,如需转载,请注明出处,否则将追究法律责任