
GreenPlum数据库故障恢复测试
GreenPlum数据库故障恢复测试
本文介绍gpdb的master故障及恢复测试以及segment故障恢复测试。
环境介绍:
Gpdb版本:5.5.0 二进制版本
操作系统版本: centos linux 7.0
Master segment: 192.168.1.225/24 hostname: mfsmaster
Stadnby segemnt: 192.168.1.227/24 hostname: server227
Segment 节点1: 192.168.1.227/24 hostname: server227
Segment 节点2: 192.168.1.17/24 hostname: server17
Segment 节点3: 192.168.1.11/24 hostname: server11
每个segment节点上分别运行一个primary segment和一个mirror segment
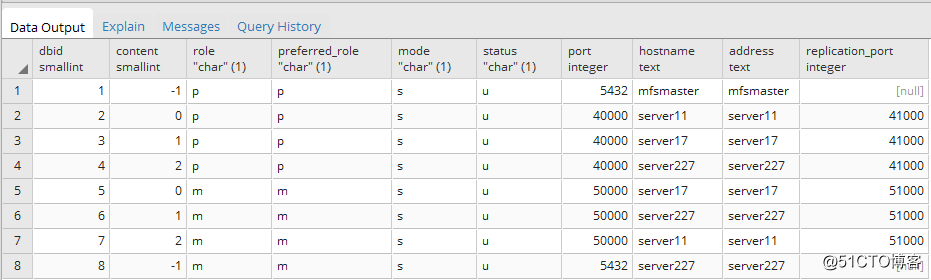
一、查看原始状态
select * from gp_segment_configuration;
$ gpstate -f20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:-Starting gpstate with args: -f20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:-local Greenplum Version: 'postgres (Greenplum Database) 5.5.0 build commit:67afa18296aa238d53a2dfcc724da60ed2f944f0'20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 8.3.23 (Greenplum Database 5.5.0 build commit:67afa18296aa238d53a2dfcc724da60ed2f944f0) on x86_64-pc-linux-gnu, compiled by GCC gcc (GCC) 6.2.0, 64-bit compiled on Feb 17 2018 15:23:55'20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:-Obtaining Segment details from master...20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:-Standby master details20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:-----------------------20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:- Standby address = server22720180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:- Standby data directory = /home/gpadmin/master/gpseg-120180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:- Standby port = 543220180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:- Standby PID = 2227920180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:- Standby status = Standby host passive20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--------------------------------------------------------------20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--pg_stat_replication20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--------------------------------------------------------------20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--WAL Sender State: streaming20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--Sync state: sync20180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--Sent Location: 0/CF2C47020180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--Flush Location: 0/CF2C47020180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--Replay Location: 0/CF2C47020180320:13:50:38:021814 gpstate:mfsmaster:gpadmin-[INFO]:--------------------------------------------------------------
二、master主从切换
1、模拟当前主库宕机,这里直接采用killall gpadmin用户下的所有进程来模拟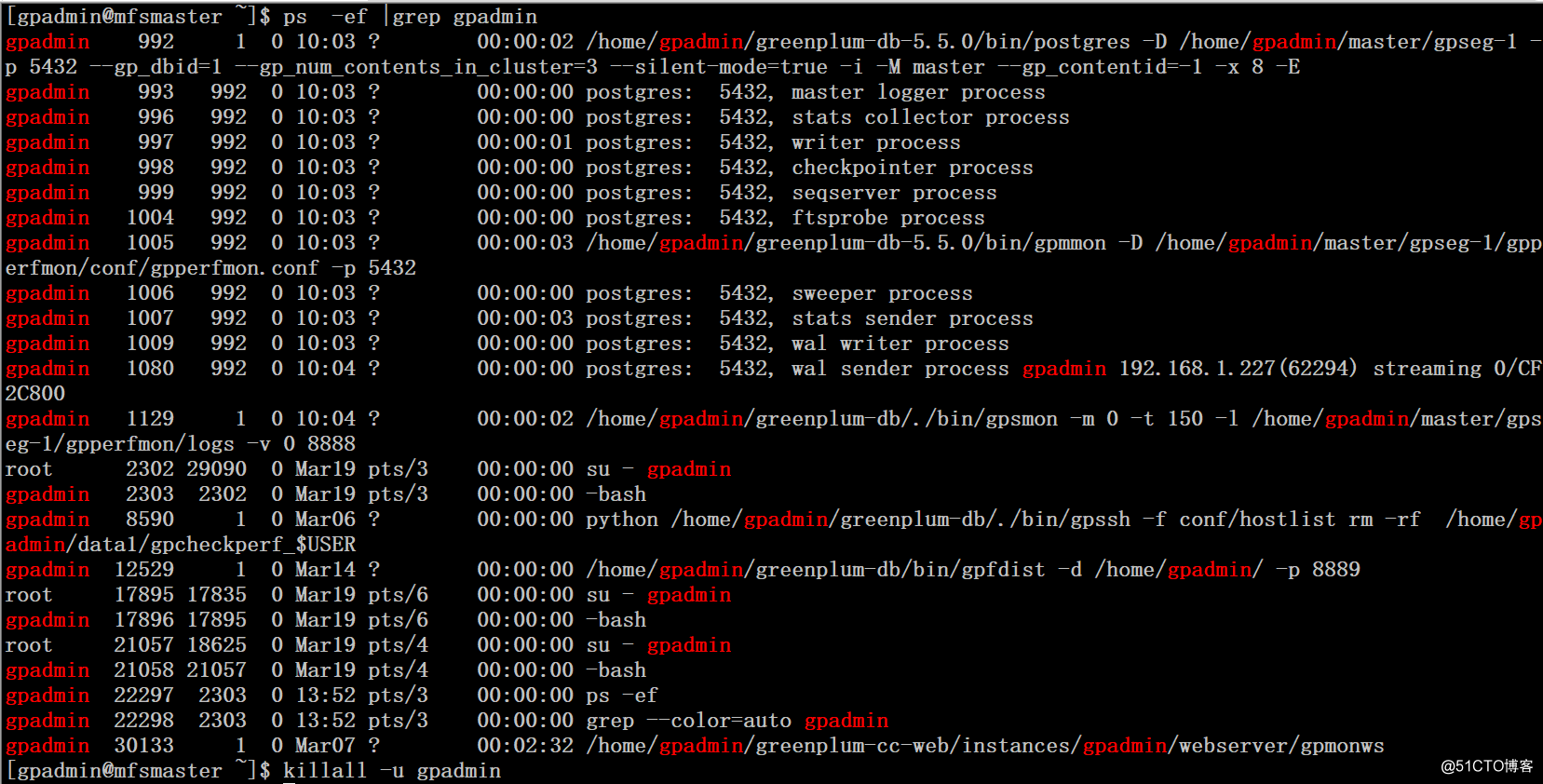
2、在master standby节点(227服务器上)进行执行切换命令,提升227为master
$ gpactivatestandby -d master/gpseg-1/20180320:13:53:20:030558 gpactivatestandby:server227:gpadmin-[INFO]:------------------------------------------------------20180320:13:53:20:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Standby data directory = /home/gpadmin/master/gpseg-120180320:13:53:20:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Standby port = 543220180320:13:53:20:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Standby running = yes20180320:13:53:20:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Force standby activation = no20180320:13:53:20:030558 gpactivatestandby:server227:gpadmin-[INFO]:------------------------------------------------------Do you want to continue with standby master activation? Yy|Nn (default=N): > y 20180320:13:53:26:030558 gpactivatestandby:server227:gpadmin-[INFO]:-found standby postmaster process 20180320:13:53:26:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Updating transaction files filespace flat files... 20180320:13:53:26:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Updating temporary files filespace flat files... 20180320:13:53:26:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Promoting standby... 20180320:13:53:26:030558 gpactivatestandby:server227:gpadmin-[DEBUG]:-Waiting for connection... 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Standby master is promoted 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Reading current configuration... 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[DEBUG]:-Connecting to dbname='postgres' 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Writing the gp_dbid file - /home/gpadmin/master/gpseg-1/gp_dbid... 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-But found an already existing file. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Hence removed that existing file. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Creating a new file... 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Wrote dbid: 1 to the file. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Now marking it as read only... 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Verifying the file... 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:------------------------------------------------------ 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-The activation of the standby master has completed successfully. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-server227 is now the new primary master. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-You will need to update your user access mechanism to reflect 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-the change of master hostname. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Do not re-start the failed master while the fail-over master is 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-operational, this could result in database corruption! 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-MASTER_DATA_DIRECTORY is now /home/gpadmin/master/gpseg-1 if20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-this has changed as a result of the standby master activation, remember 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-to change this in any startup scripts etc, that may be configured 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-to set this value. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-MASTER_PORT is now 5432, if this has changed, you 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-may need to make additional configuration changes to allow access 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-to the Greenplum instance. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Refer to the Administrator Guide for instructions on how to re-activate 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-the master to its previous state once it becomes available. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-Query planner statistics must be updated on all databases 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-following standby master activation. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:-When convenient, run ANALYZE against all user databases. 20180320:13:53:27:030558 gpactivatestandby:server227:gpadmin-[INFO]:------------------------------------------------------
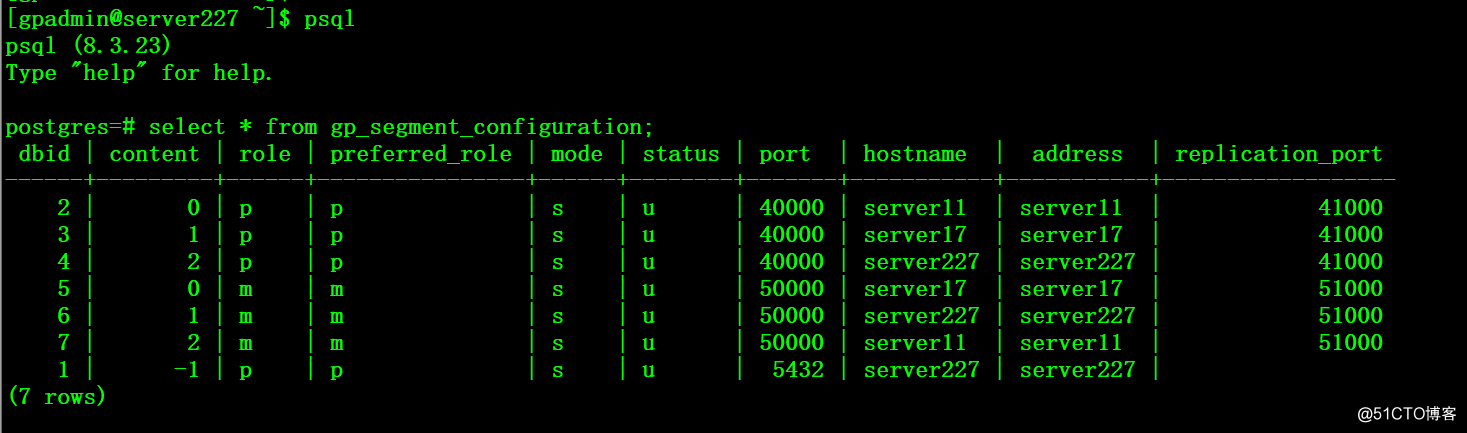
3、测试提升后的主库是否正常
$ psql -d postgres -c 'ANALYZE'postgres=# select * from gp_segment_configuration;
4、这里可能需要同步配置一下pg_hba.conf文件,才能通过客户端进行远程连接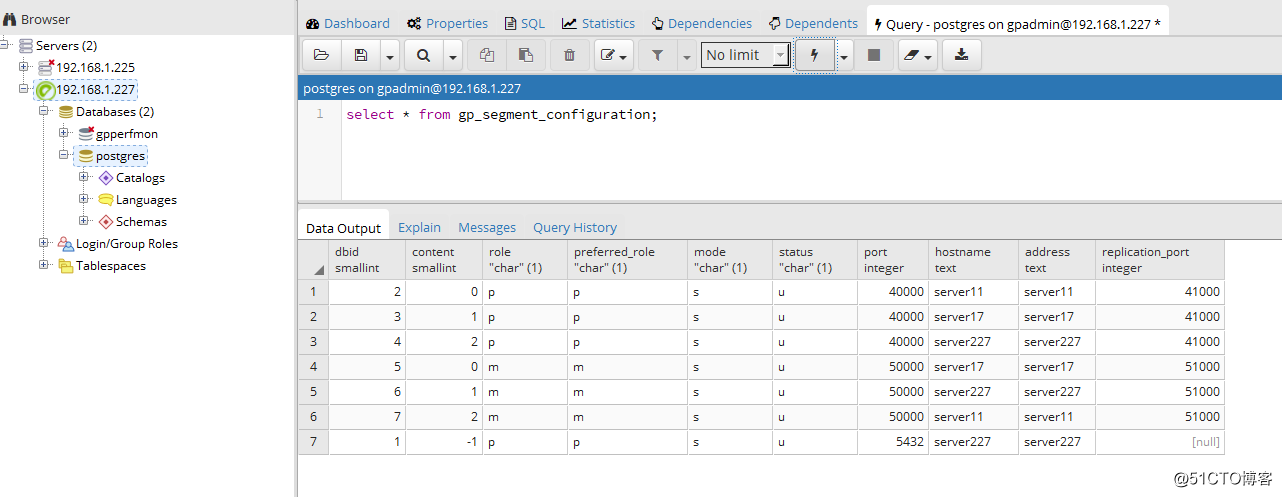
到这里我们已经完成了master节点的故障切换工作。
三、添加新的master standby
1、 在225服务器上执行gpstart -a命令启动gpdb数据库的时候报错”error: Standby active, this node no more can act as master”。当standby 提升为master的时候,原master服务器从故障中恢复过来,需要以standby的角色加入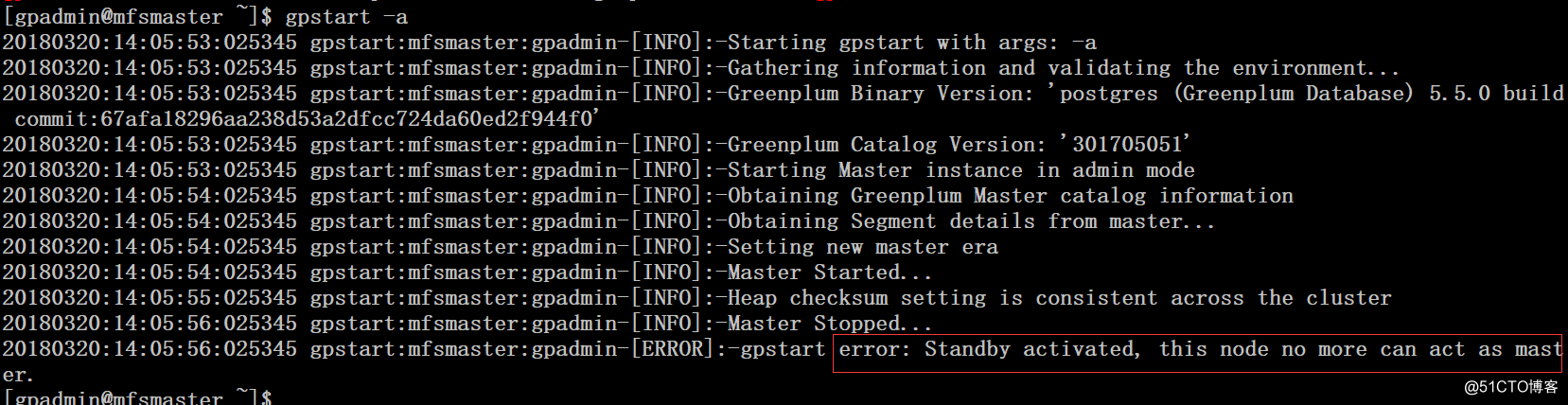
2、在原master服务器225上的数据进行备份
$ cd master/$ lsgpseg-1$ mv gpseg-1/ backup-gpseg-1
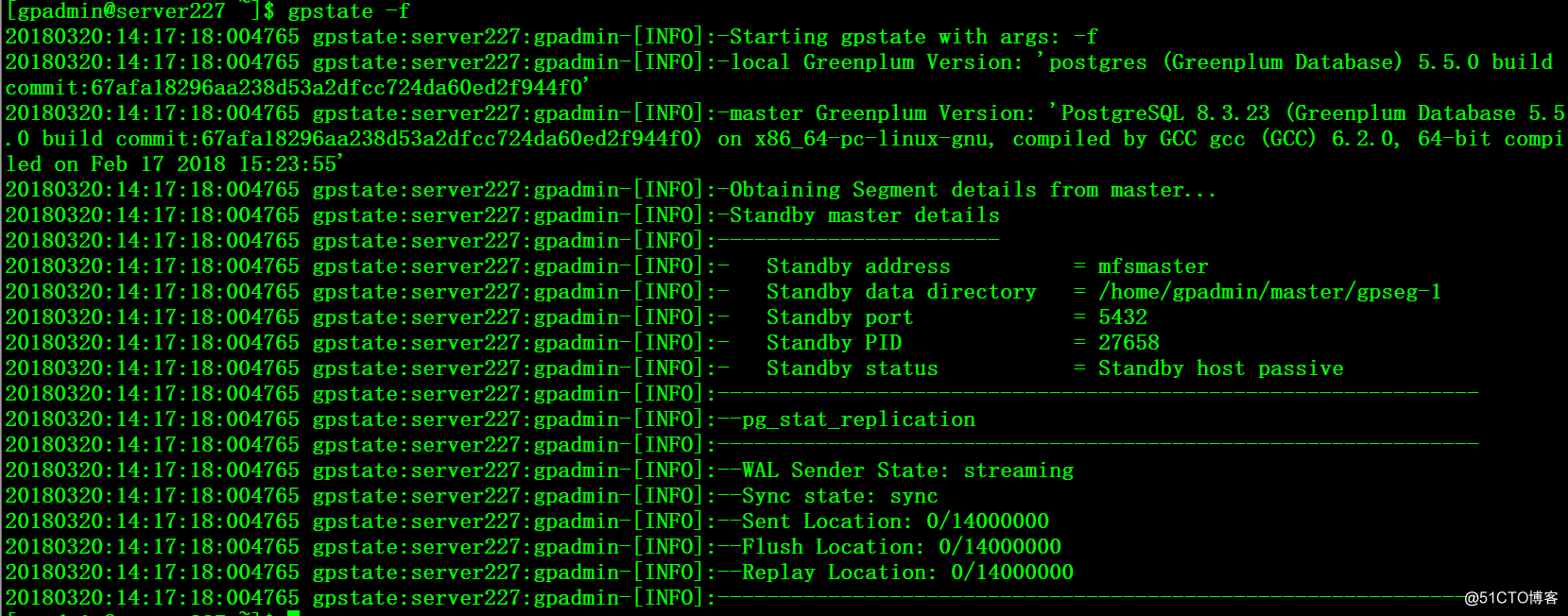
3、在当前master服务器227上进行 gpinitstandby添加225为standby
$ gpinitstandby -s mfsmaster$ gpstate -f
四、primary segment和mirror segment切换
1、首先我们来捋一下当前的数据库环境
Master segment: 192.168.1.227/24 hostname: server227
Stadnby segemnt: 192.168.1.225/24 hostname: mfsmaster
Segment 节点1: 192.168.1.227/24 hostname: server227
Segment 节点2: 192.168.1.17/24 hostname: server17
Segment 节点3: 192.168.1.11/24 hostname: server11
每个segment节点上分别运行一个primary segment和一个mirror segment
2、接着我们采用同样的方式把227服务器上gpadmin用户的所有进行杀掉
$ killall -u gpadmin
3、在225服务器上执行切换master命令
$ gpactivatestandby -d master/gpseg-1/
4、完成切换后使用客户端工具连接查看segment状态,可以看到227服务器上的server227
的primary和mirror节点都已经宕机了。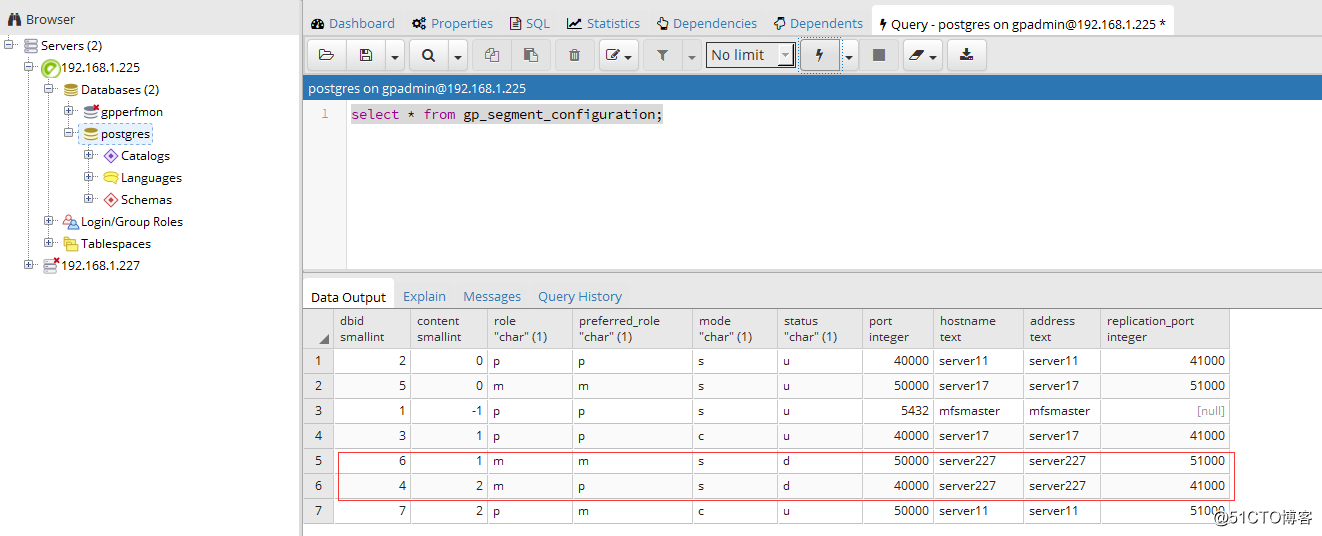
5、这里为了方面查看,我们使用greenplum-cc-web工具来查看集群状态
$ gpcmdr --start hbjy
需要将pg_hba.conf文件还原回去,因为227上所有的segment已经宕掉,执行gpstop -u命令会有报错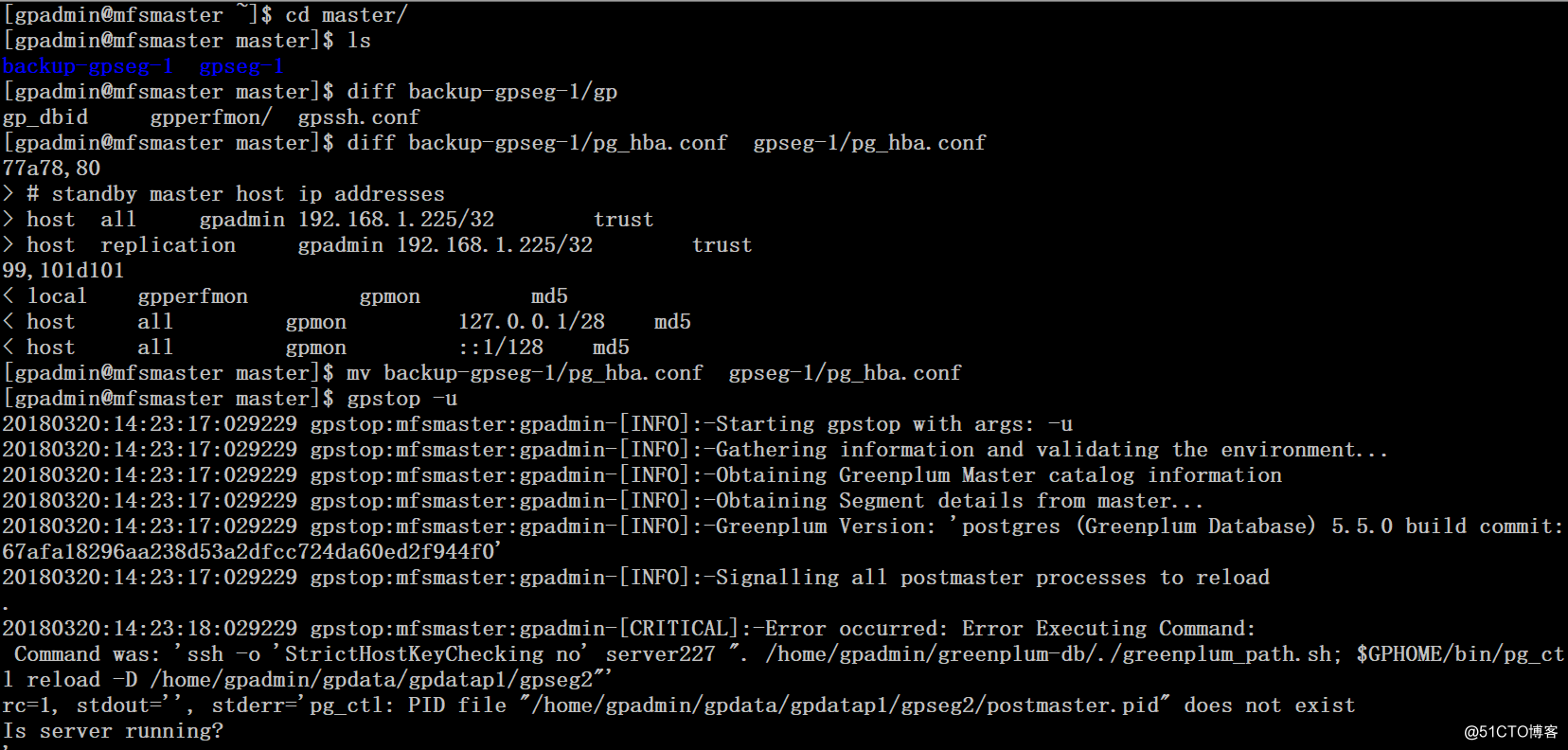
在segment status页面中可以看到当前segment的状态是异常的。server11上有两组的primary segment,这很危险,如果不幸server11也宕机了,整个集群的状态就变成不可用了。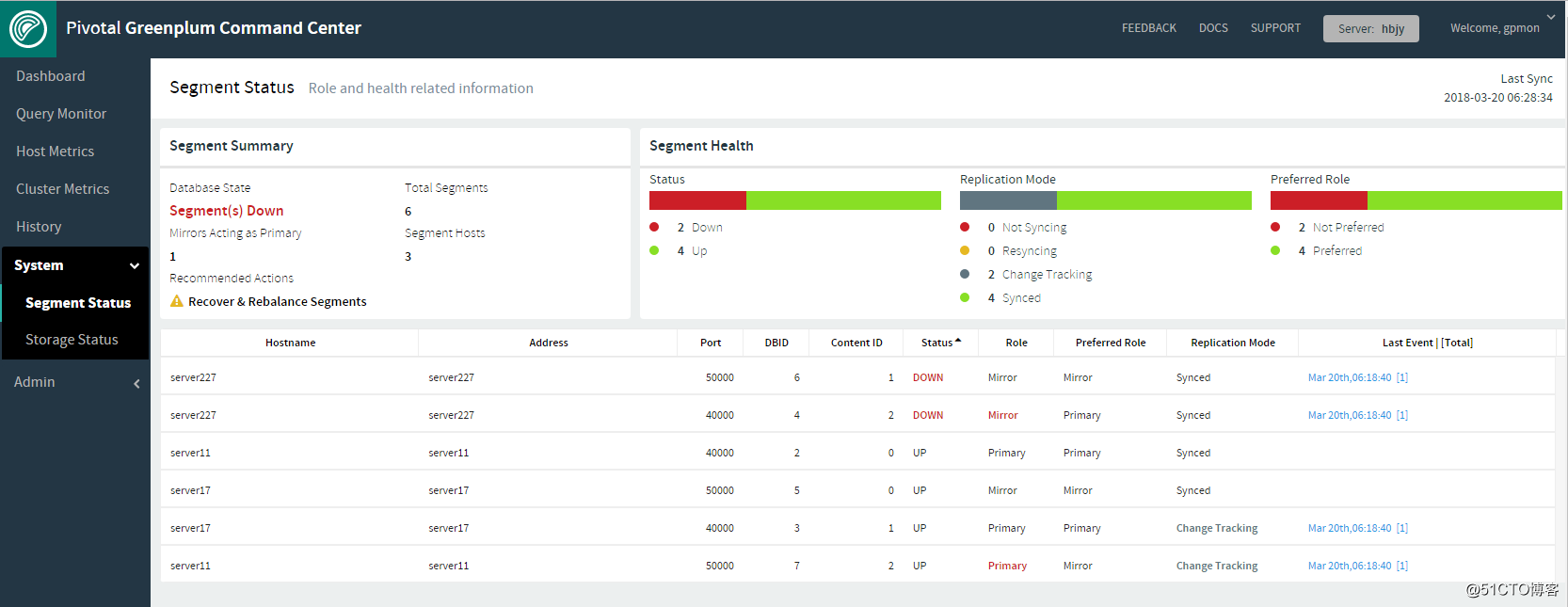
6、将server227做为master standby重新加入集群
$ cd master/$ mv gpseg-1/ backupgpseg-1$ gpinitstandby -s server227
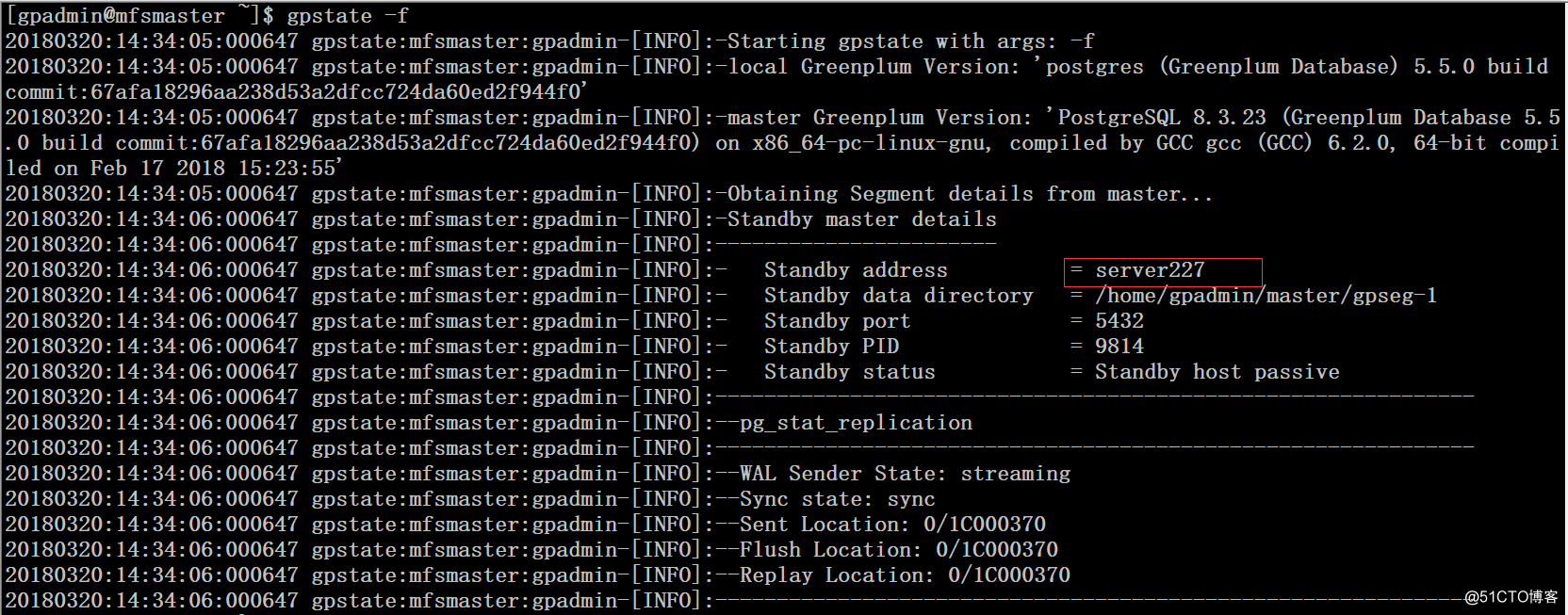
7、在master上重启集群
$ gpstop -M immediate$ gpstart -a
8、在master上恢复集群
$ gprecoverseg
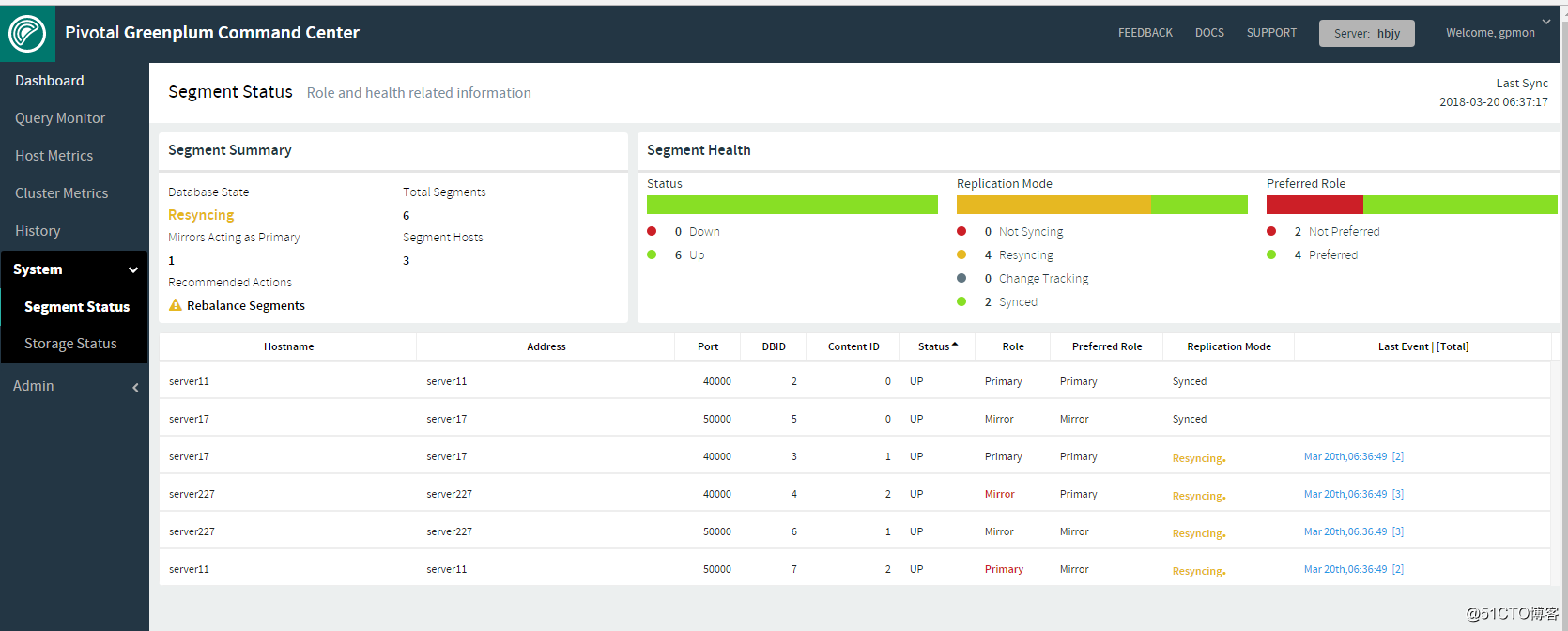
虽然所有的segment均已启动,但server11上有还是有两组的primary segment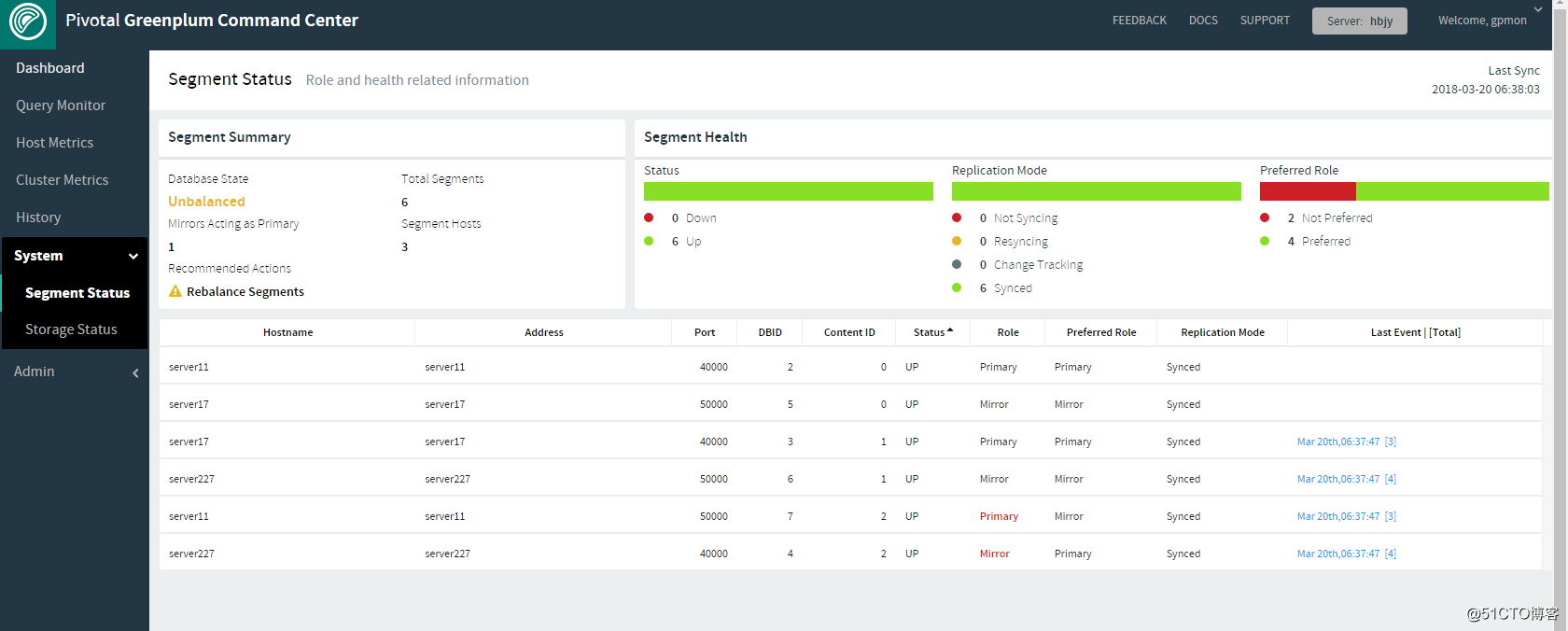
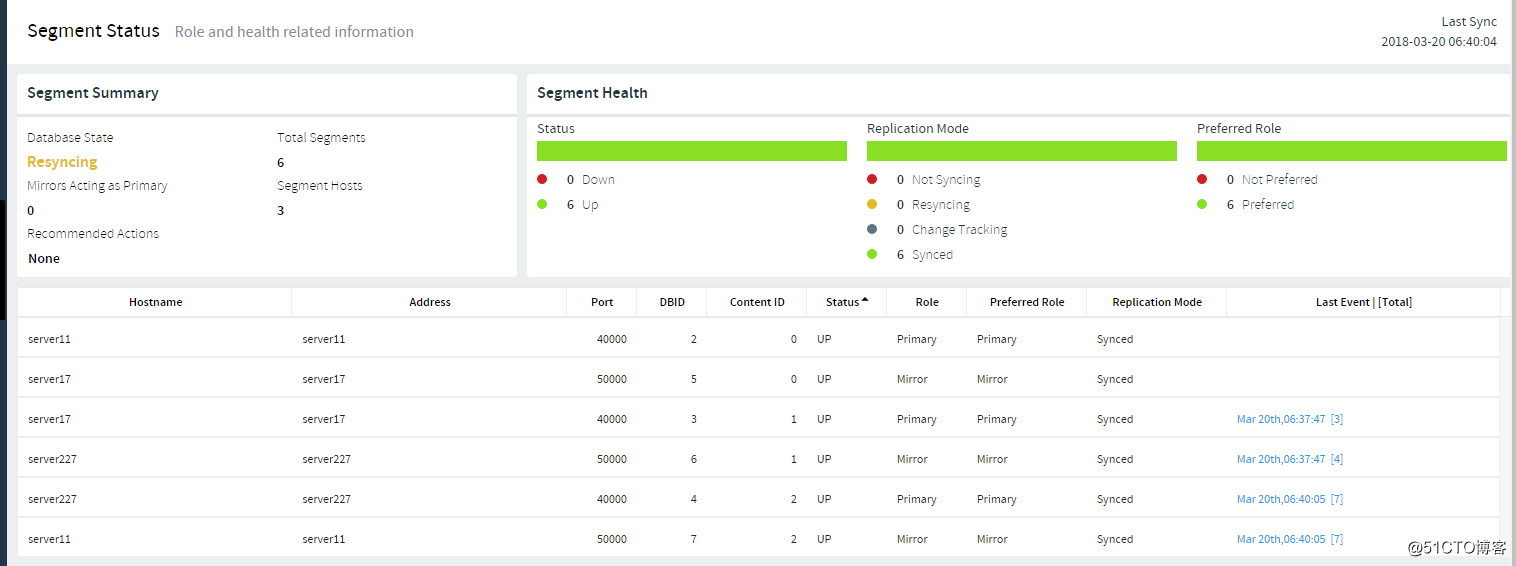
9、在master上恢复segment节点分布到原始状态
$ gprecoverseg -r
©著作权归作者所有:来自51CTO博客作者ylw6006的原创作品,如需转载,请注明出处,否则将追究法律责任
it论坛 http://www.137zw.com/