
Pandas的DataFrame如何做交集,并集,差集与对称差集
这篇文章主要介绍了Pandas的DataFrame如何做交集,并集,差集与对称差集,Python的数据类型集合由不同元素组成的集合,集合中是一组无序排列的可 Hash 的值,可以作为字典的Key,下面来看看文章的详细内容吧
目录
一、简介
二、交集
三、并集
四、差集
五、对称差集
一、简介
Python的数据类型集合:由不同元素组成的集合,集合中是一组无序排列的可 Hash 的值(不可变类型),可以作为字典的Key
Pandas中的DataFrame:DataFrame是一个表格型的数据结构,可以理解为带有标签的二维数组。
常用的集合操作如下图所示:
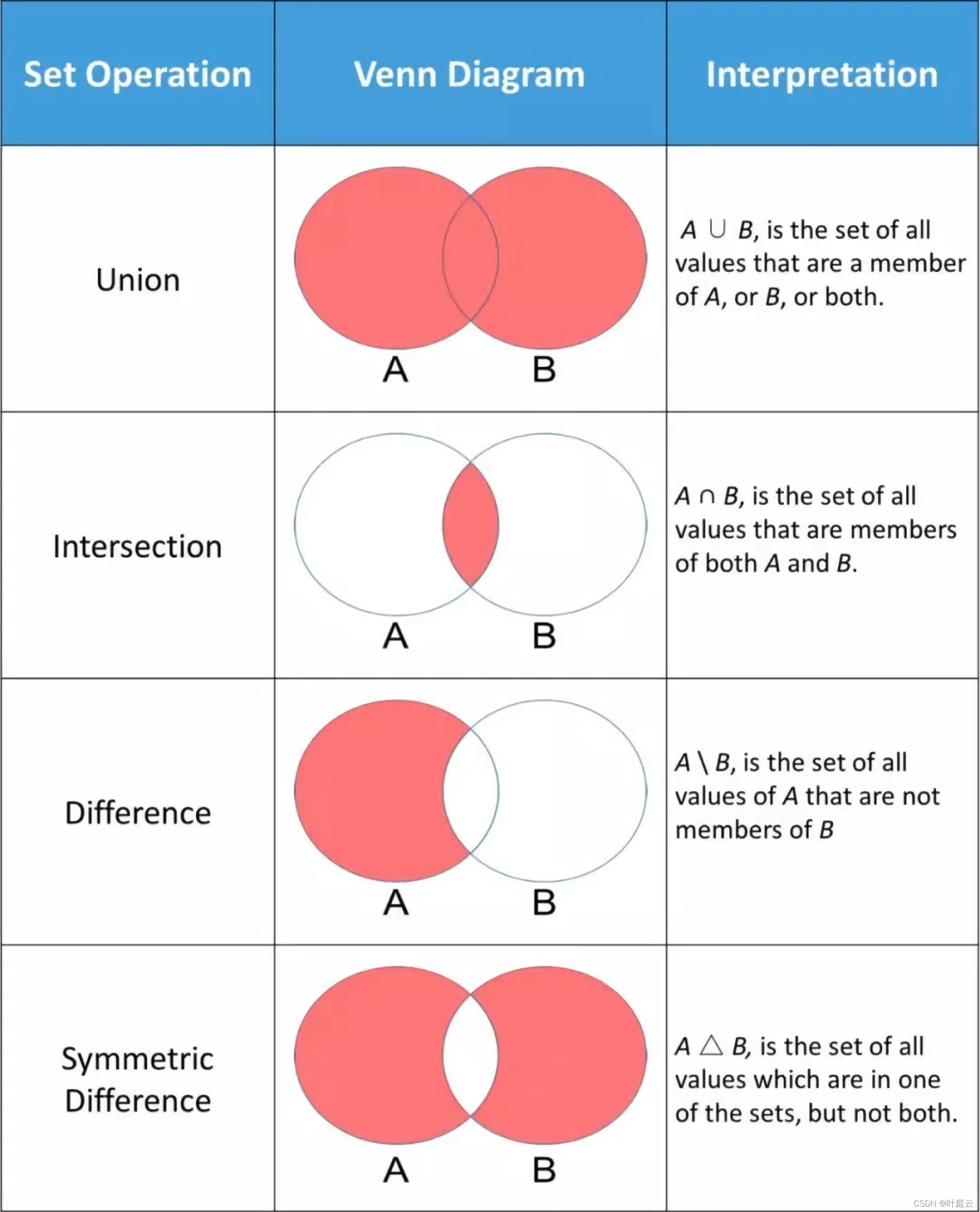
二、交集

pandas的merge功能默认为 inner 连接,可以实现取交集集合
set可以直接用 & 取交集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import pandas as pdprint("CSDN叶庭云:https://yetingyun.blog.csdn.net/")set1 = {"Python", "Go", "C++", "Java"}set2 = {"Go", "C++", "JavaScript", "C"}set1 & set2df1 = pd.DataFrame([ ['1', 'Python'], ['2', 'Go'], ['3', 'C++'], ['4', 'Java'], ], columns=['id','name'])df2 = pd.DataFrame([ ['2','Go'], ['3','C++'], ['5','JavaScript'], ['6','C'], ], columns=['id','name'])pd.merge(df1, df2, on=['id','name']) |
操作如下所示:

三、并集

Pandas的 merge 方法里参数 how 的取值有 “left”, “right”, “inner”, “outer”,默认是inner。outer外连接可以实现取并集。另一种方法也可以df1.append(df2)后去重,保留第一次出现的也可以实现取并集。
集合 set 可以直接用 | 取并集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | set1 = {"Python", "Go", "C++", "Java"}set2 = {"Go", "C++", "JavaScript", "C"}set1 | set2print("CSDN叶庭云:https://yetingyun.blog.csdn.net/")df1 = pd.DataFrame([ ['1', 'Python'], ['2', 'Go'], ['3', 'C++'], ['4', 'Java'], ], columns=['id','name'])df2 = pd.DataFrame([ ['2','Go'], ['3','C++'], ['5','JavaScript'], ['6','C'], ], columns=['id','name'])pd.merge(df1, df2, on=['id','name'], how='outer') df3 = df1.append(df2)df3.drop_duplicates(subset=['id'], keep="first") |

四、差集

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | set1 = {"Python", "Go", "C++", "Java"}set2 = {"Go", "C++", "JavaScript", "C"}set1 - set2print("CSDN叶庭云:https://yetingyun.blog.csdn.net/")set1 = {"Python", "Go", "C++", "Java"}set2 = {"Go", "C++", "JavaScript", "C"}set2 - set1# df1-df2df1 = pd.DataFrame([ ['1', 'Python'], ['2', 'Go'], ['3', 'C++'], ['4', 'Java'], ], columns=['id','name'])df2 = pd.DataFrame([ ['2','Go'], ['3','C++'], ['5','JavaScript'], ['6','C'], ], columns=['id','name'])df1 = df1.append(df2)df1 = df1.append(df2)set_diff_df = df1.drop_duplicates(subset=df1.columns, keep=False)set_diff_df# df2-df1df1 = pd.DataFrame([ ['1', 'Python'], ['2', 'Go'], ['3', 'C++'], ['4', 'Java'], ], columns=['id','name'])df2 = pd.DataFrame([ ['2','Go'], ['3','C++'], ['5','JavaScript'], ['6','C'], ], columns=['id','name'])print("CSDN叶庭云:https://yetingyun.blog.csdn.net/")df2 = df2.append(df1)df2 = df2.append(df1)set_diff_df = df2.drop_duplicates(subset=df2.columns, keep=False)set_diff_df# df1-df2df1 = pd.DataFrame([ ['1', 'Python'], ['2', 'Go'], ['3', 'C++'], ['4', 'Java'], ], columns=['id','name'])df2 = pd.DataFrame([ ['2','Go'], ['3','C++'], ['5','JavaScript'], ['6','C'], ], columns=['id','name'])pd.concat([df1, df2, df2]).drop_duplicates(keep=False)# df2-df1df1 = pd.DataFrame([ ['1', 'Python'], ['2', 'Go'], ['3', 'C++'], ['4', 'Java'], ], columns=['id','name'])df2 = pd.DataFrame([ ['2','Go'], ['3','C++'], ['5','JavaScript'], ['6','C'], ], columns=['id','name'])pd.concat([df2, df1, df1]).drop_duplicates(keep=False) |

五、对称差集

1 2 3 4 5 6 7 8 9 | print("CSDN叶庭云:https://yetingyun.blog.csdn.net/")set1 = {"Python", "Go", "C++", "Java"}set2 = {"Go", "C++", "JavaScript", "C"}set1 ^ set2 # 对称差集# 去重 不保留重复的:即可实现取对称差集df3 = df1.append(df2)df3.drop_duplicates(subset=['id'], keep=False) |

到此这篇关于Pandas的DataFrame如何做交集,并集,差集与对称差集的文章就介绍到这了
原文链接:https://blog.csdn.net/fyfugoyfa/article/details/122588761