
Python深度学习之Unet 语义分割模型(Keras)
这篇文章主要介绍了语义分割任务中Unet一个有意思的模型-Keras。Keras是一个由Python编写的开源人工神经网络库,可进行深度学习模型的设计、调试、评估、应用和可视化。感兴趣的小伙伴快来跟随小编一起学习一下吧
目录
前言
一、什么是语义分割
二、Unet
1.基本原理
2.mini_unet
3. Mobilenet_unet
4.数据加载部分
参考
前言
最近由于在寻找方向上迷失自我,准备了解更多的计算机视觉任务重的模型。看到语义分割任务重Unet一个有意思的模型,我准备来复现一下它。
一、什么是语义分割
语义分割任务,如下图所示:

简而言之,语义分割任务就是将图片中的不同类别,用不同的颜色标记出来,每一个类别使用一种颜色。常用于医学图像,卫星图像任务。
那如何做到将像素点上色呢?
其实语义分割的输出和图像分类网络类似,图像分类类别数是一个一维的one hot 矩阵。例如:三分类的[0,1,0]。
语义分割任务最后的输出特征图 是一个三维结构,大小与原图类似,通道数就是类别数。 如下图(图片来源于知乎)所示:

其中通道数是类别数,每个通道所标记的像素点,是该类别在图像中的位置,最后通过argmax 取每个通道有用像素 合成一张图像,用不同颜色表示其类别位置。 语义分割任务其实也是分类任务中的一种,他不过是对每一个像素点进行细分,找到每一个像素点所述的类别。 这就是语义分割任务啦~
下面我们来复现 unet 模型
二、Unet
1.基本原理
什么是Unet,它的网络结构如下图所示:
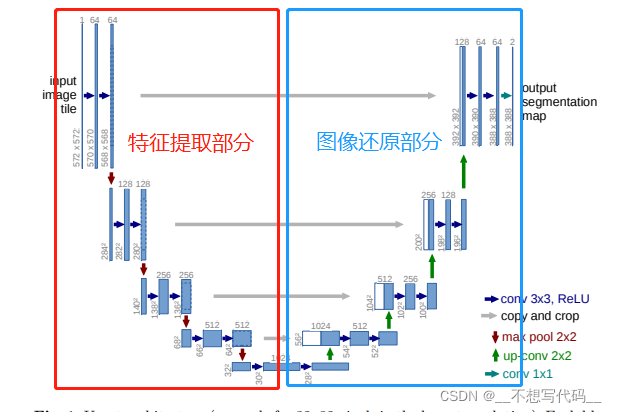
整个网络是一个“U” 的形状,Unet 网络可以分成两部分,上图红色方框中是特征提取部分,和其他卷积神经网络一样,都是通过堆叠卷积提取图像特征,通过池化来压缩特征图。蓝色方框中为图像还原部分(这样称它可能不太专业,大家理解就好),通过上采样和卷积来来将压缩的图像进行还原。特征提取部分可以使用优秀的网络,例如:Resnet50,VGG等。
注意:由于 Resnet50和VGG 网络太大。本文将使用Mobilenet 作为主干特征提取网络。为了方便理解Unet,本文将使用自己搭建的一个mini_unet 去帮祝大家理解。为了方便计算,复现过程会把压缩后的特征图上采样和输入的特征图一样大小。
代码github地址: 一直上不去
先上传到码云: https://gitee.com/Boss-Jian/unet
2.mini_unet
mini_unet 是搭建来帮助大家理解语义分割的网络流程,并不能作为一个优秀的模型完成语义分割任务,来看一下代码的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | from keras.layers import Input,Conv2D,Dropout,MaxPooling2D,Concatenate,UpSampling2Dfrom numpy import padfrom keras.models import Modeldef unet_mini(n_classes=21,input_shape=(224,224,3)): img_input = Input(shape=input_shape) #------------------------------------------------------ # #encoder 部分 #224,224,3 - > 112,112,32 conv1 = Conv2D(32,(3,3),activation='relu',padding='same')(img_input) conv1 = Dropout(0.2)(conv1) conv1 = Conv2D(32,(3,3),activation='relu',padding='same')(conv1) pool1 = MaxPooling2D((2,2),strides=2)(conv1) #112,112,32 -> 56,56,64 conv2 = Conv2D(64,(3,3),activation='relu',padding='same')(pool1) conv2 = Dropout(0.2)(conv2) conv2 = Conv2D(64,(3,3),activation='relu',padding='same')(conv2) pool2 = MaxPooling2D((2,2),strides=2)(conv2) #56,56,64 -> 56,56,128 conv3 = Conv2D(128,(3,3),activation='relu',padding='same')(pool2) conv3 = Dropout(0.2)(conv3) conv3 = Conv2D(128,(3,3),activation='relu',padding='same')(conv3) #------------------------------------------------- # decoder 部分 #56,56,128 -> 112,112,64 up1 = UpSampling2D(2)(conv3) #112,112,64 -> 112,112,64+128 up1 = Concatenate(axis=-1)([up1,conv2]) # #112,112,192 -> 112,112,64 conv4 = Conv2D(64,(3,3),activation='relu',padding='same')(up1) conv4 = Dropout(0.2)(conv4) conv4 = Conv2D(64,(3,3),activation='relu',padding='same')(conv4) #112,112,64 - >224,224,64 up2 = UpSampling2D(2)(conv4) #224,224,64 -> 224,224,64+32 up2 = Concatenate(axis=-1)([up2,conv1]) # 224,224,96 -> 224,224,32 conv5 = Conv2D(32,(3,3),activation='relu',padding='same')(up2) conv5 = Dropout(0.2)(conv5) conv5 = Conv2D(32,(3,3),activation='relu',padding='same')(conv5) o = Conv2D(n_classes,1,padding='same')(conv5) return Model(img_input,o,name="unet_mini")if __name__=="__main__": model = unet_mini() model.summary() |
mini_unet 通过encoder 部分将 224x224x3的图像 变成 112x112x64 的特征图,再通过 上采样方法将特征图放大到 224x224x32。最后通过卷积:
1 | o = Conv2D(n_classes,1,padding='same')(conv5) |
将特征图的通道数调节成和类别数一样。
3. Mobilenet_unet
Mobilenet_unet 是使用Mobinet 作为主干特征提取网络,并且加载预训练权重来提升特征提取的能力。decoder 的还原部分和上面一致,下面是Mobilenet_unet 的网络结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 | from keras.models import *from keras.layers import *import keras.backend as Kimport kerasfrom tensorflow.python.keras.backend import shapeIMAGE_ORDERING = "channels_last"# channel lastdef relu6(x): return K.relu(x, max_value=6)def _conv_block(inputs, filters, alpha, kernel=(3, 3), strides=(1, 1)): channel_axis = 1 if IMAGE_ORDERING == 'channels_first' else -1 filters = int(filters * alpha) x = ZeroPadding2D(padding=(1, 1), name='conv1_pad', data_format=IMAGE_ORDERING)(inputs) x = Conv2D(filters, kernel, data_format=IMAGE_ORDERING, padding='valid', use_bias=False, strides=strides, name='conv1')(x) x = BatchNormalization(axis=channel_axis, name='conv1_bn')(x) return Activation(relu6, name='conv1_relu')(x)def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha, depth_multiplier=1, strides=(1, 1), block_id=1): channel_axis = 1 if IMAGE_ORDERING == 'channels_first' else -1 pointwise_conv_filters = int(pointwise_conv_filters * alpha) x = ZeroPadding2D((1, 1), data_format=IMAGE_ORDERING, name='conv_pad_%d' % block_id)(inputs) x = DepthwiseConv2D((3, 3), data_format=IMAGE_ORDERING, padding='valid', depth_multiplier=depth_multiplier, strides=strides, use_bias=False, name='conv_dw_%d' % block_id)(x) x = BatchNormalization( axis=channel_axis, name='conv_dw_%d_bn' % block_id)(x) x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x) x = Conv2D(pointwise_conv_filters, (1, 1), data_format=IMAGE_ORDERING, padding='same', use_bias=False, strides=(1, 1), name='conv_pw_%d' % block_id)(x) x = BatchNormalization(axis=channel_axis, name='conv_pw_%d_bn' % block_id)(x) return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)def get_mobilnet_eocoder(input_shape=(224,224,3),weights_path=""): # 必须是32 的倍数 assert input_shape[0] % 32 == 0 assert input_shape[1] % 32 == 0 alpha = 1.0 depth_multiplier = 1 img_input = Input(shape=input_shape) #(None, 224, 224, 3) ->(None, 112, 112, 64) x = _conv_block(img_input, 32, alpha, strides=(2, 2)) x = _depthwise_conv_block(x, 64, alpha, depth_multiplier, block_id=1) f1 = x #(None, 112, 112, 64) -> (None, 56, 56, 128) x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, strides=(2, 2), block_id=2) x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, block_id=3) f2 = x #(None, 56, 56, 128) -> (None, 28, 28, 256) x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, strides=(2, 2), block_id=4) x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=5) f3 = x # (None, 28, 28, 256) -> (None, 14, 14, 512) x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, strides=(2, 2), block_id=6) x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=7) x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=8) x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=9) x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=10) x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=11) f4 = x # (None, 14, 14, 512) -> (None, 7, 7, 1024) x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier, strides=(2, 2), block_id=12) x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier, block_id=13) f5 = x # 加载预训练模型 if weights_path!="": Model(img_input, x).load_weights(weights_path, by_name=True, skip_mismatch=True) # f1: (None, 112, 112, 64) # f2: (None, 56, 56, 128) # f3: (None, 28, 28, 256) # f4: (None, 14, 14, 512) # f5: (None, 7, 7, 1024) return img_input, [f1, f2, f3, f4, f5]def mobilenet_unet(num_classes=2,input_shape=(224,224,3)): #encoder img_input,levels = get_mobilnet_eocoder(input_shape=input_shape,weights_path="model_data\mobilenet_1_0_224_tf_no_top.h5") [f1, f2, f3, f4, f5] = levels # f1: (None, 112, 112, 64) # f2: (None, 56, 56, 128) # f3: (None, 28, 28, 256) # f4: (None, 14, 14, 512) # f5: (None, 7, 7, 1024) #decoder #(None, 14, 14, 512) - > (None, 14, 14, 512) o = f4 o = ZeroPadding2D()(o) o = Conv2D(512, (3, 3), padding='valid' , activation='relu' , data_format=IMAGE_ORDERING)(o) o = BatchNormalization()(o) #(None, 14, 14, 512) ->(None,28,28,256) o = UpSampling2D(2)(o) o = Concatenate(axis=-1)([o,f3]) o = ZeroPadding2D()(o) o = Conv2D(256, (3, 3), padding='valid' , activation='relu' , data_format=IMAGE_ORDERING)(o) o = BatchNormalization()(o) # None,28,28,256)->(None,56,56,128) o = UpSampling2D(2)(o) o = Concatenate(axis=-1)([o,f2]) o = ZeroPadding2D()(o) o = Conv2D(128, (3, 3), padding='valid' , activation='relu' , data_format=IMAGE_ORDERING)(o) o = BatchNormalization()(o) #(None,56,56,128) ->(None,112,112,64) o = UpSampling2D(2)(o) o = Concatenate(axis=-1)([o,f1]) o = ZeroPadding2D()(o) o = Conv2D(128, (3, 3), padding='valid' , activation='relu' , data_format=IMAGE_ORDERING)(o) o = BatchNormalization()(o) #(None,112,112,64) -> (None,112,112,num_classes) # 再上采样 让输入和出处图片大小一致 o = UpSampling2D(2)(o) o = ZeroPadding2D()(o) o = Conv2D(64, (3, 3), padding='valid' , activation='relu' , data_format=IMAGE_ORDERING)(o) o = BatchNormalization()(o) o = Conv2D(num_classes, (3, 3), padding='same', data_format=IMAGE_ORDERING)(o) return Model(img_input,o)if __name__=="__main__": mobilenet_unet(input_shape=(512,512,3)).summary() |
特征图的大小变化,以及代码含义都已经注释在代码里了。大家仔细阅读吧
4.数据加载部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 | import mathimport osfrom random import shuffleimport cv2import kerasimport numpy as npfrom PIL import Image#-------------------------------# 将图片转换为 rgb#------------------------------def cvtColor(image): if len(np.shape(image)) == 3 and np.shape(image)[2] == 3: return image else: image = image.convert('RGB') return image #-------------------------------# 图片归一化 0~1#------------------------------def preprocess_input(image): image = image / 127.5 - 1 return image#---------------------------------------------------# 对输入图像进行resize#---------------------------------------------------def resize_image(image, size): iw, ih = image.size w, h = size scale = min(w/iw, h/ih) nw = int(iw*scale) nh = int(ih*scale) image = image.resize((nw,nh), Image.BICUBIC) new_image = Image.new('RGB', size, (128,128,128)) new_image.paste(image, ((w-nw)//2, (h-nh)//2)) return new_image, nw, nhclass UnetDataset(keras.utils.Sequence): def __init__(self, annotation_lines, input_shape, batch_size, num_classes, train, dataset_path): self.annotation_lines = annotation_lines self.length = len(self.annotation_lines) self.input_shape = input_shape self.batch_size = batch_size self.num_classes = num_classes self.train = train self.dataset_path = dataset_path def __len__(self): return math.ceil(len(self.annotation_lines) / float(self.batch_size)) def __getitem__(self, index): #图片和标签、 images = [] targets = [] # 读取一个batchsize for i in range(index*self.batch_size,(index+1)*self.batch_size): #判断 i 越界情况 i = i%self.length name = self.annotation_lines[i].split()[0] # 从路径中读取图像 jpg 表示图片,png 表示标签 jpg = Image.open(os.path.join(os.path.join(self.dataset_path,'Images'),name+'.png')) png = Image.open(os.path.join(os.path.join(self.dataset_path,'Labels'),name+'.png')) #------------------- # 数据增强 和 归一化 #------------------- jpg,png = self.get_random_data(jpg,png,self.input_shape,random=self.train) jpg = preprocess_input(np.array(jpg,np.float64)) png = np.array(png) #----------------------------------- # 医学图像中 描绘出的是细胞边缘 # 将小于 127.5的像素点 作为目标 像素点 #------------------------------------ seg_labels = np.zeros_like(png) seg_labels[png<=127.5] = 1 #-------------------------------- # 转化为 one hot 标签 # ------------------------- seg_labels = np.eye(self.num_classes + 1)[seg_labels.reshape([-1])] seg_labels = seg_labels.reshape((int(self.input_shape[0]), int(self.input_shape[1]), self.num_classes + 1)) images.append(jpg) targets.append(seg_labels) images = np.array(images) targets = np.array(targets) return images, targets def rand(self, a=0, b=1): return np.random.rand() * (b - a) + a def get_random_data(self, image, label, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5, random=True): image = cvtColor(image) label = Image.fromarray(np.array(label)) h, w = input_shape if not random: iw, ih = image.size scale = min(w/iw, h/ih) nw = int(iw*scale) nh = int(ih*scale) image = image.resize((nw,nh), Image.BICUBIC) new_image = Image.new('RGB', [w, h], (128,128,128)) new_image.paste(image, ((w-nw)//2, (h-nh)//2)) label = label.resize((nw,nh), Image.NEAREST) new_label = Image.new('L', [w, h], (0)) new_label.paste(label, ((w-nw)//2, (h-nh)//2)) return new_image, new_label # resize image rand_jit1 = self.rand(1-jitter,1+jitter) rand_jit2 = self.rand(1-jitter,1+jitter) new_ar = w/h * rand_jit1/rand_jit2 scale = self.rand(0.25, 2) if new_ar < 1: nh = int(scale*h) nw = int(nh*new_ar) else: nw = int(scale*w) nh = int(nw/new_ar) image = image.resize((nw,nh), Image.BICUBIC) label = label.resize((nw,nh), Image.NEAREST) flip = self.rand()<.5 if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT) label = label.transpose(Image.FLIP_LEFT_RIGHT) # place image dx = int(self.rand(0, w-nw)) dy = int(self.rand(0, h-nh)) new_image = Image.new('RGB', (w,h), (128,128,128)) new_label = Image.new('L', (w,h), (0)) new_image.paste(image, (dx, dy)) new_label.paste(label, (dx, dy)) image = new_image label = new_label # distort image hue = self.rand(-hue, hue) sat = self.rand(1, sat) if self.rand()<.5 else 1/self.rand(1, sat) val = self.rand(1, val) if self.rand()<.5 else 1/self.rand(1, val) x = cv2.cvtColor(np.array(image,np.float32)/255, cv2.COLOR_RGB2HSV) x[..., 0] += hue*360 x[..., 0][x[..., 0]>1] -= 1 x[..., 0][x[..., 0]<0] += 1 x[..., 1] *= sat x[..., 2] *= val x[x[:,:, 0]>360, 0] = 360 x[:, :, 1:][x[:, :, 1:]>1] = 1 x[x<0] = 0 image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB)*255 return image_data,label def on_epoch_begin(self): shuffle(self.annotation_lines) |
训练过程代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 | import numpy as npfrom tensorflow.python.keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoardfrom keras.optimizers import Adamimport osfrom unet_mini import unet_minifrom mobilnet_unet import mobilenet_unetfrom callbacks import ExponentDecayScheduler,LossHistoryfrom keras import backend as Kfrom keras import backend from data_loader import UnetDataset#--------------------------------------# 交叉熵损失函数 cls_weights 类别的权重#-------------------------------------def CE(cls_weights): cls_weights = np.reshape(cls_weights, [1, 1, 1, -1]) def _CE(y_true, y_pred): y_pred = K.clip(y_pred, K.epsilon(), 1.0 - K.epsilon()) CE_loss = - y_true[...,:-1] * K.log(y_pred) * cls_weights CE_loss = K.mean(K.sum(CE_loss, axis = -1)) # dice_loss = tf.Print(CE_loss, [CE_loss]) return CE_loss return _CEdef f_score(beta=1, smooth = 1e-5, threhold = 0.5): def _f_score(y_true, y_pred): y_pred = backend.greater(y_pred, threhold) y_pred = backend.cast(y_pred, backend.floatx()) tp = backend.sum(y_true[...,:-1] * y_pred, axis=[0,1,2]) fp = backend.sum(y_pred , axis=[0,1,2]) - tp fn = backend.sum(y_true[...,:-1], axis=[0,1,2]) - tp score = ((1 + beta ** 2) * tp + smooth) \ / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth) return score return _f_scoredef train(): #------------------------- # 细胞图像 分为细胞壁 和其他 # 初始化 参数 #------------------------- num_classes = 2 input_shape = (512,512,3) # 从第几个epoch 继续训练 batch_size = 4 learn_rate = 1e-4 start_epoch = 0 end_epoch = 100 num_workers = 4 dataset_path = 'Medical_Datasets' model = mobilenet_unet(num_classes,input_shape=input_shape) model.summary() # 读取数据图片的路劲 with open(os.path.join(dataset_path, "ImageSets/Segmentation/train.txt"),"r") as f: train_lines = f.readlines() logging = TensorBoard(log_dir = 'logs/') checkpoint = ModelCheckpoint('logs/ep{epoch:03d}-loss{loss:.3f}.h5', monitor = 'loss', save_weights_only = True, save_best_only = False, period = 1) reduce_lr = ExponentDecayScheduler(decay_rate = 0.96, verbose = 1) early_stopping = EarlyStopping(monitor='loss', min_delta=0, patience=10, verbose=1) loss_history = LossHistory('logs/', val_loss_flag = False) epoch_step = len(train_lines) // batch_size cls_weights = np.ones([num_classes], np.float32) loss = CE(cls_weights) model.compile(loss = loss, optimizer = Adam(lr=learn_rate), metrics = [f_score()]) train_dataloader = UnetDataset(train_lines, input_shape[:2], batch_size, num_classes, True, dataset_path) print('Train on {} samples, with batch size {}.'.format(len(train_lines), batch_size)) model.fit_generator( generator = train_dataloader, steps_per_epoch = epoch_step, epochs = end_epoch, initial_epoch = start_epoch, # use_multiprocessing = True if num_workers > 1 else False, workers = num_workers, callbacks = [logging, checkpoint, early_stopping,reduce_lr,loss_history] )if __name__=="__main__": train() |
最后的预测结果:

完整的代大家感兴趣可以去github下载下来再看,代码比较多,全部贴出来博客显得太长了。
这就是简单的语义分割任务啦。
参考
以上就是Python深度学习之Unet 语义分割模型(Keras)的详细内容
原文链接:https://blog.csdn.net/qq_38676487/article/details/121903186
伪原创工具 SEO网站优化 https://www.237it.com/