
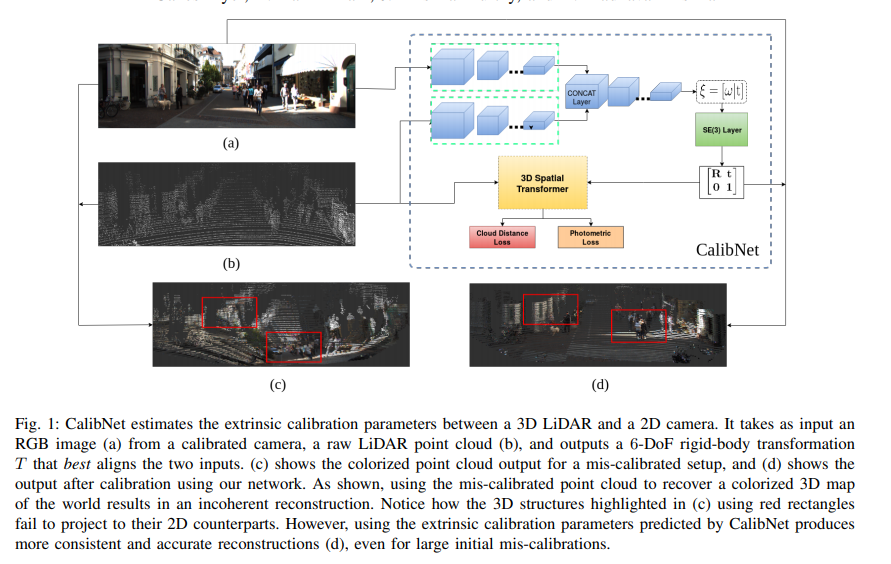
论文阅读 CalibNet
标签:从零开始 预处理 sqrt The nta work set lte training
Abstract
calibnet估计了3D LiDAR和相机的外参。我们没有引入直接的监督,我们训练网络来最大化几何和光度的一致性。
1. Introduction
我们的训练方法通过直接减少稠密的光度误差和稠密点云距离误差测量,来回归正确的外参标定参数。
calibnet是第一个几何监督的深度学习方法来解决多传感器自标定问题,在lidar-camera的rig中。
我们用基于3D Spatial transfomers[7]的架构,它学习了底层的物理问题,通过使用几何和光度的一致性来引导学习过程。这个使得calibnet agnostic to(不可知的)不是常亮的参数。
。。。
2. Related Work
贵重的标定setup有一个优势是它只需要很少的数据。
【3】提出了第一个targetless技术,但是他们的潜在假设是,深度不连续会投影到图像的edge上。【4】提出了一个类似的方法,他们尝试最大化lidar intensity和相机intensity的互信息。
另一个targetless的技术是基于独立的位姿估计,如【5】。他们不需要任何外参初始化,或者需要共视。但是他们需要很多数据。
深度神经网络在 视觉识别,定位【10】,和对应的估计【11】上获得了成功。深度网络在3D物体检测和分割【12,13】上也体现了效果。
第一个深度卷积神经网络用于LiDAR-相机标定的是【14】,他们目的在于回归准且align LiDAR点云和图像的transformation参数,通过用大量标注失准数据来训练。即使是实时的,这个训练过程没有考虑潜在的几何,所以就要对各个传感器的内参变换重新训练。
相较而言,我们的方法利用了最近的自监督网络【15,16】,通过见扫稠密光度误差和稠密点云距离误差来解决问题。
3. Our Approach
A. Network Architecture
点云先被转化为稀疏深度图作为预处理,这是通过LiDAR点云投影到图像平面做到的。
我们normalize了RGB图和稀疏深度图 to the range of ±1,稀疏深度图然后被 max-pool 来创造版稠密深度图,用5x5的max -pooling window. 结果图Fig.4(b).

Architectural Details:
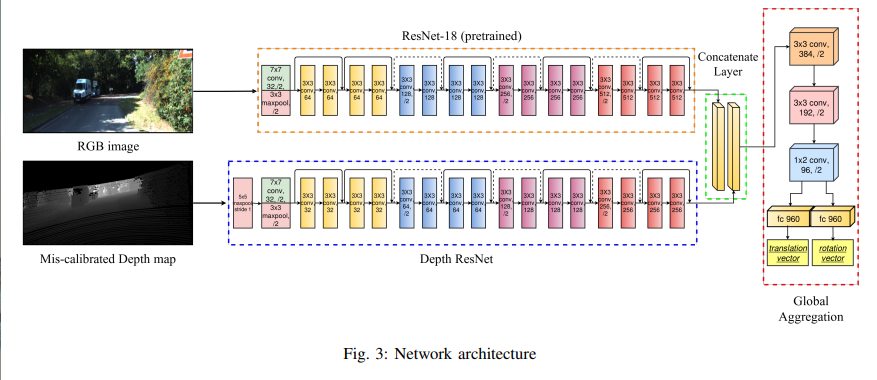
网络初步由两个不对称的分支组成,每个做了一系列的卷积。如图3,RGB branch,我们用卷积层 of 要给预见训练的ResNet-18网络【17】。对深度图branch,我们用类似的框架,但是每一个stage由一半刷零的filter。如【14】,这个框架由几个特征提取的优势。
利用预先寻来你的RBG的权重方式从0开始学。但是,因为depth stream是从零开始的,depth stream的filters在每个stage会减少。
两个branch的输出会级联,然后通过一系列额外的全卷积层,做全局特征几何。
BatchNorm【18】在整个网络中被使用,我们解耦了旋转和平移的输出 to capture differences in modalities。
SO(3) layer
exponential map是 group generators的线性组合,用taylor series expansion。
3D Spatial Transformer Layer
一旦变成\(T\in SE(3)\)后,我们用3D Spatial Transformer Layer把深度图变换。
知道相机内参\((f_x, f_y, f_x, f_y)\)可以做max-pooled深度图到稀疏点云的反投影。
Loss Functions
我们有两类loss terms
光度误差:在用预测的\(T\)变换深度图之后,我们检查稠密 pixel-wise误差(每个像素用深度intensity来encoded)在预测深度图和修正深度图之间。
\[\mathcal{L}_{\text {photo }}=\frac{1}{2} \sum_{1}^{N}\left(D_{g t}-K T \pi^{-1}\left[D_{\text {miscalib }}\right]\right)^{2} \]
这里\(D_{gt}\)是target深度图,\(D_{miscalib}\)是初始的有误差的深度图。
点云距离误差:3D Spatial Transformer层允许点云在反投影后变换。我们利用unregistered变换和目标定啊晕来尝试最小化3D-3D点距离。注意我们不知道匹配,所以这个任务更难。跟随着最近的【19】,我们考虑如下距离:
Chamfer Distance: 两片点云\(S_1, S_2 \in R^3\)的距离,最近两个点的距离平方和:
\[d_{C D}\left(S_{1}, S_{2}\right)=\sum_{x \in S_{1}} \min _{y \in S_{2}}\|x-y\|_{2}^{2}+\sum_{y \in S_{2}} \min _{x \in S_{1}}\|x-y\|_{2}^{2} \]
Earth Mover‘s Distance: 如果\(\phi\)是两个点云集的映射,我们如下最小化距离:
\[d_{E M D}\left(S_{1}, S_{2}\right)=\min _{\phi: S_{1} \rightarrow S_{2}} \sum_{x \in S 1}\|x-\phi(x)\|_{2} \]
where \(\phi: S_{1} \rightarrow S_{2}\) is a bijection.
Centroid ICP Distance:
\[d_{i c p}\left(S_{1}, S_{2}\right)=\frac{1}{2} \sum_{1}^{N} \sum_{1}^{i}\left\|X_{e x p}^{i}-\left(R X_{\text {miscalib }}^{i}+t\right)\right\|^{2} \]
我们最终的loss是光度loss和点云距离loss的合。
B. Layer Implementation Details
输入的图有很多是0,这样就需要用layers来应用数学操作,也有要给前提是这些layers是可微分的in a end-to-end fashion。
我们用Tensorflow library【20】来应用我们pipeline的多种子模块。我们频繁的应用scatter_nd 操作符,基于【21】提到的优势,因为它允许稀疏更新。我们用在Bilinear Sampling Layer。
我们也用一个操作符来方式重复的更新,我们用Cantor Pairing function.
C. Iterative Re-alignment
迭代的,每次我们的网络预测了一个\(T\),我们会把它再赛进入,结果就如下:
\[\widehat{T}=(T)\left(T^{\prime}\right)\left(T^{\prime \prime}\right)\left(T^{\prime \prime \prime}\right) \ldots \]
4. Experiments and Discussion
A. Dataset Preparation
。。
B. Evaluation Metrics
因为我们不是以一个supervised manner训练, i.e. 。。
我们只用了点云距离来训练平移。
我们用 geodesic distance over SO(3)来衡量总体的旋转误差:
\[d_{g}\left(R_{i}, R_{j}\right)=\frac{1}{\sqrt{2}}\left\|\log \left(R_{i}^{T} R_{j}\right)\right\|_{F} \]
这里\(R_i\) 是预测旋转,\(R_j\)是gt旋转。
C. Training Details
我们用Adam Optimizer[24],初始learning rate是\(1e^{-4}\),momentum = 0.9。我们用一个0.5因子在每过一些 epochs来减少learning rate. 一共训练了28个epochs。
用Earth Mover Distance在cost function中,\(\alpha_{ph} = 1.0, \beta_{dist}=0.15\),逐渐增加到1.75.
D. Result
1. Rotation Estimation
平均绝对误差(MAE)在测试集上:yaw 0.15°,pitch 0.9°,roll 0.18°。
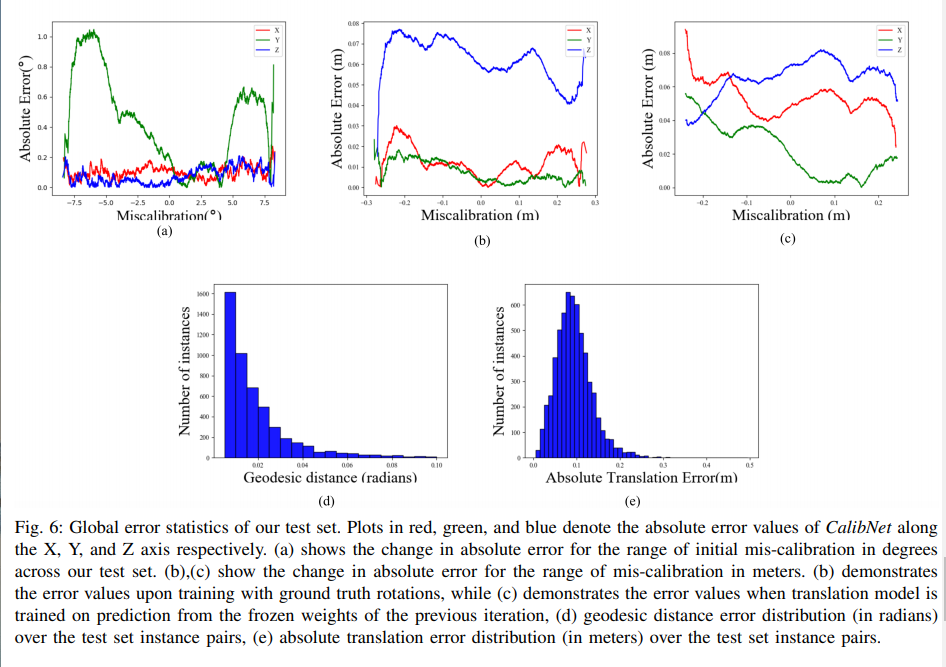
2. Translatons given gt
MAE in 平移:X: 4.2cm, Y: 1.6cm, Z: 7.22cm
3. Translations given CalibNet rotation estimates
在CalibNet回归了旋转的初始估计,我们用spatial transformer来应用估计旋转在mis-calibrated depth map,用earth movers distance作为loss function来训练平移。。。
4. Qualitative Results
。。
5. Conclusion
我们展现了要给novel自监督的深度网络用于估计6DoF。
网络的估计在有好的初始化的时候可以。
未来,我们虚妄能利用其他先验来解决registration问题,例如深度图和图像的皮皮额,地平面的约束等。
标签:从零开始 预处理 sqrt The nta work set lte training
原文地址:https://www.cnblogs.com/tweed/p/14497581.html