
bytebuddy基本使用(byte的用法)
为什么要生成运行时代码?
Java 语言带有相对严格的类型系统。 Java 要求所有变量和对象都属于特定类型,任何分配不兼容类型的尝试总是会导致错误。这些错误通常由 Java 编译器或至少由 Java 运行时在非法转换类型时发出。这种严格的类型通常是可取的,例如在编写业务应用程序时。业务领域通常可以用一种明确的方式来描述,其中任何领域项目都代表它自己的类型。通过这种方式,我们可以使用 Java 来构建非常易读且健壮的应用程序,其中错误在靠近其源头的地方被捕获。其中,Java 的类型系统是 Java 在企业编程中流行的原因。
但是,通过强制执行其严格的类型系统,Java 强加了限制该语言在其他领域中的范围的限制。例如,在编写供其他 Java 应用程序使用的通用库时,我们通常无法引用用户应用程序中定义的任何类型,因为在编译我们的库时,这些类型对我们来说是未知的。为了调用方法或访问用户未知代码的字段,Java 类库自带了一个反射 API。使用反射 API,我们能够内省未知类型并调用方法或访问字段。不幸的是,使用反射 API 有两个明显的缺点:
使用反射 API 比硬编码的方法调用慢:首先,需要执行相当昂贵的方法查找来获取描述特定方法的对象。当调用方法时,这需要 JVM 运行本机代码,与直接调用相比,这需要较长的运行时间。然而,现代 JVM 知道一个称为膨胀的概念,其中基于 JNI 的方法调用被注入到动态创建的类中的生成的字节码所取代。 (甚至 JVM 本身也使用代码生成!)毕竟,Java 的膨胀系统仍然存在生成非常通用的代码的缺点,例如仅适用于盒装原始类型,因此性能缺陷并未完全解决。
反射 API 破坏了类型安全性:尽管 JVM 能够通过反射调用代码,但反射 API 本身并不是类型安全的。在编写库时,只要我们不需要将反射 API 暴露给库的用户,这不是问题。毕竟,我们在编译期间不知道用户代码,也无法根据其类型验证我们的库代码。然而,有时需要通过例如让库为我们调用我们自己的方法之一来向用户公开反射 API。这就是使用反射 API 会出现问题的地方,因为 Java 编译器将拥有所有信息来验证我们程序的类型安全性。例如,在为方法级安全实现库时,该库的用户希望该库仅在强制执行安全约束后调用方法。为此,库需要在用户移交此方法所需的参数后反射性地调用该方法。这样做,但是如果这些方法参数与方法的反射调用匹配,则不再进行编译时类型检查。方法调用仍然有效,但检查延迟到运行时。这样做,我们取消了 Java 编程语言的一个重要特性。
这是运行时代码生成可以帮助我们的地方。它允许我们在不放弃 Java 的静态类型检查的情况下模拟一些通常只能在使用动态语言编程时才能访问的功能。这样,我们可以两全其美,并进一步提高运行时性能。为了更好地理解这个问题,让我们看一下实现上述方法级安全库的示例。
编写安全库
业务应用程序可能会变大,有时很难在我们的应用程序中保持调用堆栈的概览。当我们的应用程序中存在仅应在特定条件下调用的关键方法时,这可能会成为问题。想象一个业务应用程序,它实现了一个重置功能,允许从应用程序的数据库中删除所有内容。
class Service { void deleteEverything() { // delete everything ... } } 复制代码这种重置当然只能由管理员执行,而不能由我们应用程序的普通用户执行。通过分析我们的源代码,我们当然可以确保这永远不会发生。然而,我们可以期待我们的应用程序在未来增长和改变。因此,我们想要实现一个更严格的安全模型,其中方法调用由对应用程序当前用户的显式检查来保护。我们通常会使用一个安全框架来确保除了管理员之外的任何人都不会调用该方法。
为此,假设我们使用具有公共 API 的安全框架,如下所示:
@Retention(RetentionPolicy.RUNTIME) @interface Secured { String user(); } class UserHolder { static String user; } interface Framework { <T> T secure(Class<T> type); } 复制代码在这个框架中,应该使用 Secured 注释来标记只能由给定用户访问的方法。 UserHolder 用于全局定义当前登录到应用程序的用户。 Framework 接口允许通过调用给定类型的默认构造函数来创建安全实例。当然,这个框架过于简单,但原则上这就是安全框架(例如流行的 Spring Security)的工作方式。这个安全框架的一个特点是我们保留了用户的类型。根据我们框架接口的约定,我们承诺用户返回它接收到的任何类型 T 的实例。由于这一点,用户能够与他自己的类型进行交互,就好像安全框架不存在一样。在测试环境中,用户甚至可以创建他的类型的不安全实例并使用这些实例而不是安全实例。你会同意这真的很方便!众所周知,此类框架会与 POJO(普通的旧 Java 对象)交互,这个术语是为了描述不将自己的类型强加给用户的非侵入性框架而创造的。
现在想象一下,我们知道传递给框架的类型只能是 T = Service 并且 deleteEverything 方法使用 @Secured("ADMIN") 进行注释。这样,我们可以通过简单地将其子类化来轻松实现这种特定类型的安全版本:
class SecuredService extends Service { @Override void deleteEverything() { if(UserHolder.user.equals("ADMIN")) { super.deleteEverything(); } else { throw new IllegalStateException("Not authorized"); } } } 复制代码有了这个额外的类,我们可以按如下方式实现框架:
class HardcodedFrameworkImpl implements Framework { @Override public <T> T secure(Class<T> type) { if(type == Service.class) { return (T) new SecuredService(); } else { throw new IllegalArgumentException("Unknown: " + type); } } } 复制代码当然,这种实现并没有多大用处。通过安全方法的签名,我们建议该方法可以为任何类型提供安全性,但实际上,一旦遇到已知服务之外的其他内容,我们将抛出异常。此外,这将需要我们的安全库在编译库时了解此特定服务类型。显然,这不是实现框架的可行方案。那么我们如何解决这个问题呢?好吧,由于这是一个关于代码生成库的教程,您一定已经猜到了答案:当 Service 类第一次通过调用安全方法为我们的安全框架所知时,我们会根据需要在运行时创建一个子类。通过代码生成,我们可以采用任何给定的类型,在运行时对其进行子类化并覆盖我们想要保护的方法。在我们的例子中,我们覆盖了所有用 @Secured 注释的方法,并从注释的 user 属性中读取所需的用户。许多流行的 Java 框架都是使用类似的方法实现的。
一般信息
在我们全面了解代码生成和 Byte Buddy 之前,请注意您应该谨慎使用代码生成。 Java 类型对于 JVM 来说是相当特殊的,通常不会被垃圾收集。因此,永远不要过度使用代码生成,而应仅在生成代码是唯一的出路时才使用它来解决问题。但是,如果您需要像前面的示例一样增强未知类型,代码生成很可能是您唯一的选择。用于安全性、事务管理、对象关系映射或模拟的框架是代码生成库的典型用户。
当然,Byte Buddy 并不是第一个在 JVM 上生成代码的库。但是,我们相信 Byte Buddy 知道其他框架无法应用的一些技巧。 Byte Buddy 的总体目标是通过专注于其领域特定语言和注释的使用,以声明方式工作。我们所知道的 JVM 没有其他代码生成库以这种方式工作。不过,您可能希望查看其他一些代码生成框架,以找出最适合您的套件。其中,以下库在 Java 领域很流行:
Java proxies
Java 类库带有一个代理工具包,允许创建实现一组给定接口的类。这个内置的代理供应商很方便,但也很有限。例如,上面提到的安全框架不能以这种方式实现,因为我们想要扩展类而不是接口。
cglib
代码生成库是在 Java 早期实现的,遗憾的是它没有跟上 Java 平台的发展。尽管如此,cglib 仍然是一个非常强大的库,但它的积极发展变得相当模糊。出于这个原因,它的许多用户离开了 cglib。
Javassist
该库带有一个编译器,该编译器采用包含 Java 源代码的字符串,这些字符串在应用程序运行时被翻译成 Java 字节码。这是非常雄心勃勃的,原则上是一个好主意,因为 Java 源代码显然是描述 Java 类的好方法。但是,Javassist 编译器的功能无法与 javac 编译器相比,并且在动态组合字符串以实现更复杂的逻辑时容易出错。此外,Javassist 带有一个代理库,它类似于 JCL 的代理实用程序,但允许扩展类并且不限于接口。然而,Javassist 的代理工具的范围在其 API 和功能方面同样受到限制。
自己评估这些框架,但我们相信 Byte Buddy 提供了功能和便利,否则您将徒劳无功。 Byte Buddy 附带了一种富有表现力的领域特定语言,它允许通过编写纯 Java 代码和为您自己的代码使用强类型来创建非常自定义的运行时类。同时,Byte Buddy 对定制非常开放,不会限制您使用开箱即用的功能。如果需要,您甚至可以为任何已实现的方法定义自定义字节码。但即使不知道字节码是什么或它是如何工作的,您也可以在不深入研究框架的情况下做很多事情。例如,您是否看过 Hello World!例子?使用 Byte Buddy 就是这么简单。
当然,在选择代码生成库时,令人愉悦的 API 并不是唯一要考虑的特性。对于许多应用程序,生成代码的运行时特性更有可能确定最佳选择。除了生成代码本身的运行时,创建动态类的运行时也可能是一个问题。声称我们是最快的!为图书馆的速度提供有效的度量标准很容易,但也很难。尽管如此,我们还是希望提供这样一个指标作为基本方向。但是,请记住,这些结果不一定会转化为您更具体的用例,您应该在其中执行单个指标。
在讨论我们的指标之前,让我们先看看原始数据。下表显示了操作的平均运行时间(以纳秒为单位),其中标准偏差附在大括号中:
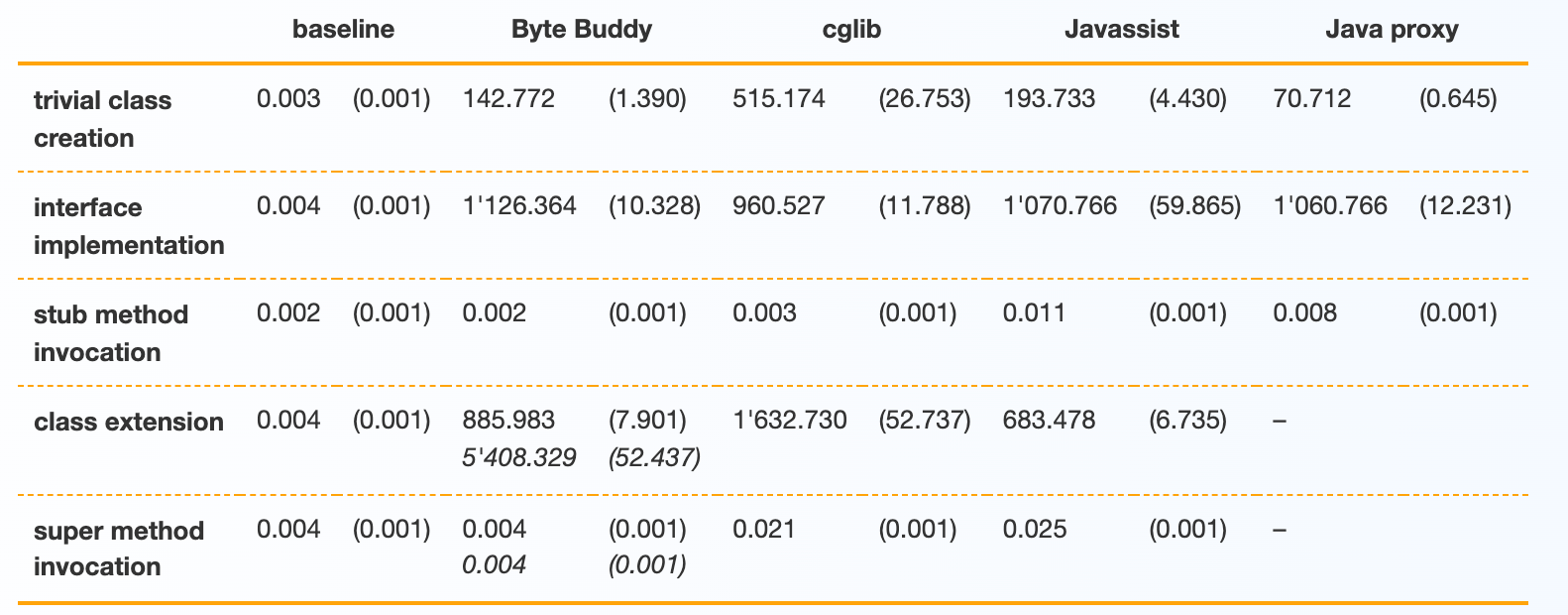
与静态编译器类似,代码生成库面临生成快速代码和快速生成代码之间的权衡。在这些相互冲突的目标之间进行选择时,Byte Buddy 的主要重点在于生成具有最少运行时间的代码。通常,类型创建或操作不是任何程序中的常见步骤,并且不会显着影响任何长时间运行的应用程序;特别是因为类加载或类检测是运行此类代码时最耗时且不可避免的步骤。
上表中的第一个基准测试用于在不实现或覆盖任何方法的情况下为 Object 子类化的库的运行时间。这给了我们一个库在代码生成中的一般开销的印象。在这个基准测试中,由于只有在假设总是扩展接口时才有可能进行优化,Java 代理的性能优于其他库。 Byte Buddy 还检查类中的泛型类型和注解是什么导致了额外的运行时。在创建类的其他基准测试中也可以看到这种性能开销。基准测试 (2a) 显示了用于创建(和加载)实现具有 18 个方法的单个接口的类的测量运行时间,(2b)显示了为此类生成的方法的执行时间。类似地,(3a) 显示了使用相同的 18 种已实现方法扩展类的基准。 Byte Buddy 提供了两个基准测试,这是由于对始终执行超级方法的拦截器可能进行的优化。在类创建期间牺牲一些时间,Byte Buddy 创建的类的执行时间通常达到基线,这意味着检测根本不会产生任何开销。应该注意的是,如果元数据处理被禁用,Byte Buddy 在类创建期间也优于任何其他代码生成库。然而,由于代码生成的运行时间与程序的总运行时间相比非常小,因此这种选择退出是不可用的,因为它会以牺牲库代码的复杂性为代价获得很少的性能。
最后,请注意,我们的指标衡量的是 Java 代码的性能,这些代码事先由 JVM 的即时编译器优化。如果你的代码只是偶尔执行,性能会比上述指标建议的要差。在这种情况下,您的代码开始时并不是性能关键。此指标的代码与 Byte Buddy 一起分发,您可以在自己的计算机上运行这些指标,其中上述数字可能会根据您机器的处理能力进行缩放。出于这个原因,不要绝对解释上述数字,而是将它们视为比较不同库的相对度量。在进一步开发 Byte Buddy 时,我们希望监控这些指标,以避免在添加新功能时造成性能损失。
在接下来的教程中,我们将逐步解释Byte Buddy的功能。我们将从大多数用户最有可能使用的更通用的功能开始。然后,我们将考虑越来越高级的主题,并简要介绍 Java 字节码和类文件格式。如果您快进到后面的材料,请不要气馁!通过使用 Byte Buddy 的标准 API,您几乎可以做任何事情,而无需了解任何 JVM 细节。要了解标准 API,请继续阅读。
创建一个类
Byte Buddy 创建的任何类型都由 ByteBuddy 类的实例发出。只需通过调用 new ByteBuddy() 创建一个新实例,您就可以开始了。希望您正在使用一个开发环境,在那里您可以获得有关可以在给定对象上调用的方法的建议。这样,您可以避免在 Byte Buddy 的 javadoc 中手动查找类的 API,而是让您的 IDE 指导您完成整个过程。如前所述,Byte Buddy 提供了一种领域特定的语言,旨在尽可能使人类可读。因此,大多数情况下,IDE 的提示会为您指明正确的方向。话虽如此,让我们在 Java 程序的运行时创建第一个类:
DynamicType.Unloaded<?> dynamicType = new ByteBuddy() .subclass(Object.class) .make(); 复制代码
很明显,上面的代码示例创建了一个扩展 Object 类型的新类。这种动态创建的类型相当于一个 Java 类,它只扩展 Object 而没有显式实现任何方法、字段或构造函数。您可能已经注意到,我们甚至没有命名动态生成的类型,这在定义 Java 类时通常是必需的。当然,您可以轻松地明确命名您的类型:
DynamicType.Unloaded<?> dynamicType = new ByteBuddy() .subclass(Object.class) .name("example.Type") .make(); 复制代码但是没有显式命名会发生什么? Byte Buddy 遵循配置的惯例,并为您提供我们认为方便的默认值。对于类型的名称,默认的 Byte Buddy 配置提供了一个 NamingStrategy,它根据动态类型的超类名称随机创建一个类名称。此外,名称被定义为与超类在同一个包中,这样直接超类的包私有方法对于动态类型总是可见的。例如,如果您子类化名为 example.Foo 的类型,则生成的名称将类似于 example.FooByteBuddyByteBuddyByteBuddy1376491271,其中数字序列是随机的。从 java.lang 包中子类化类型(例如 Object 存在的类型)时,会出现此规则的一个例外。 Java 的安全模型不允许自定义类型存在于该命名空间中。因此,默认命名策略将此类类型名称以 net.bytebuddy.renamed 为前缀。
这种默认行为可能对您不方便。并且由于约定优于配置原则,您始终可以根据需要更改默认行为。这就是 ByteBuddy 类的用武之地。通过创建一个新的 ByteBuddy() 实例,您可以创建一个默认配置。通过在此配置上调用方法,您可以根据个人需要对其进行自定义。让我们试试这个:
DynamicType.Unloaded<?> dynamicType = new ByteBuddy() .with(new NamingStrategy.AbstractBase() { @Override public String subclass(TypeDescription superClass) { return "i.love.ByteBuddy." + superClass.getSimpleName(); } }) .subclass(Object.class) .make(); 复制代码在上面的代码示例中,我们创建了一个新配置,其类型命名策略与默认配置不同。匿名类被实现为简单地连接字符串 i.love.ByteBuddy 和基类的简单名称。当继承 Object 类型时,动态类型因此命名为 i.love.ByteBuddy.Object。在创建自己的命名策略时要小心! Java 虚拟机使用名称来区分类型,这就是您要避免命名冲突的原因。如果您需要自定义命名行为,请考虑使用 Byte Buddy 的内置 NamingStrategy.SuffixingRandom,您可以自定义它以包含比我们的默认值对您的应用程序更有意义的前缀。
领域特定语言和不变性
在看到 Byte Buddy 的领域特定语言的实际应用后,我们需要简要了解一下这种语言的实现方式。关于实现,您需要了解的一个细节是该语言是围绕不可变对象构建的。事实上,几乎所有存在于 Byte Buddy 命名空间中的类都是不可变的,在少数情况下我们不能使类型不可变,我们在这个类的 javadoc 中明确提到了它。如果您为 Byte Buddy 实现自定义功能,我们建议您坚持这一原则。
作为提到的不变性的含义,例如在配置 ByteBuddy 实例时必须小心。例如,您可能会犯以下错误:
ByteBuddy byteBuddy = new ByteBuddy(); byteBuddy.withNamingStrategy(new NamingStrategy.SuffixingRandom("suffix")); DynamicType.Unloaded<?> dynamicType = byteBuddy.subclass(Object.class).make(); 复制代码您可能希望使用(据称)定义的自定义命名策略 new NamingStrategy.SuffixingRandom("suffix") 生成动态类型。而不是改变存储在 byteBuddy 变量中的实例,调用 withNamingStrategy 方法会返回一个自定义的 ByteBuddy 实例,但是该实例丢失了。因此,动态类型是使用最初创建的默认配置创建的。
重新定义和重新定义现有类
到目前为止,我们只演示了如何使用 Byte Buddy 创建现有类的子类。然而,相同的 API 可用于增强现有类。这种增强有两种不同的风格:
类型重新定义
重新定义类时,Byte Buddy 允许通过添加字段和方法或替换现有方法实现来更改现有类。然而,如果先前存在的方法实现被另一个实现替换,它们将丢失。例如,当重新定义以下类型时
class Foo { String bar() { return "bar"; } } 复制代码如果从 bar 方法返回“qux”,则该方法最初返回“bar”的信息将完全丢失。
类型变基
当重新定义一个类时,Byte Buddy 会保留重新定义的类的任何方法实现。 Byte Buddy 不会像执行类型重新定义那样丢弃被覆盖的方法,而是将所有此类方法实现复制到具有兼容签名的重命名私有方法中。这样,不会丢失任何实现,并且重新定位的方法可以通过调用这些重命名的方法继续调用原始代码。这样,上面的类 Foo 可以重新基于类似的东西
class Foo { String bar() { return "foo" + bar$original(); } private String bar$original() { return "bar"; } } 复制代码bar 方法最初返回“bar”的信息保存在另一个方法中,因此仍然可以访问。当重新定义一个类时,Byte Buddy 会处理所有的方法定义,比如如果你定义了一个子类,即如果你试图调用一个重新定位的方法的超级方法实现,它将调用重新定位的方法。但相反,它最终将这个假设的超类扁平化为上面显示的重新定位的类型。
任何变基、重新定义或子类化都是使用由 DynamicType.Builder 接口定义的相同 API 执行的。通过这种方式,例如可以将类定义为子类,然后更改定义以表示重新定位的类。这是通过仅更改 Byte Buddy 的领域特定语言的一个单词来实现的。这样,应用任何一种可能的方法
new ByteBuddy().subclass(Foo.class) new ByteBuddy().redefine(Foo.class) new ByteBuddy().rebase(Foo.class) 复制代码
在定义过程的后续阶段透明处理,本教程的其余部分对此进行了解释。由于子类定义对于 Java 开发人员来说是一个熟悉的概念,因此以下所有 Byte Buddy 领域特定语言的解释和示例都是通过创建子类来演示的。但是,请记住,所有类都可以通过重新定义或变基来类似地定义。
加载一个类
到目前为止,我们只定义并创建了一个动态类型,但我们并没有使用它。由 Byte Buddy 创建的类型由 DynamicType.Unloaded 的实例表示。顾名思义,这些类型不会加载到 Java 虚拟机中。相反,Byte Buddy 创建的类以 Java 类文件格式以二进制形式表示。这样,由您决定要对生成的类型做什么。例如,您可能希望从构建脚本运行 Byte Buddy,该脚本仅生成类以在部署之前增强 Java 应用程序。为此,DynamicType.Unloaded 类允许提取表示动态类型的字节数组。为方便起见,该类型还提供了一个 saveIn(File) 方法,允许您将类存储在给定的文件夹中。此外,它允许您将(文件)类注入现有的 jar 文件。
虽然直接访问类的二进制形式很简单,但不幸的是,加载类型要复杂得多。在 Java 中,所有类都使用 ClassLoader 加载。这种类加载器的一个例子是引导类加载器,它负责加载 Java 类库中提供的类。另一方面,系统类加载器负责在 Java 应用程序的类路径上加载类。显然,这些预先存在的类加载器都不知道我们创建的任何动态类。为了克服这个问题,我们必须找到其他可能性来加载运行时生成的类。 Byte Buddy 通过开箱即用的不同方法提供解决方案:
我们只是创建一个新的 ClassLoader,它被明确告知某个特定动态创建的类的存在。因为 Java 类加载器是按层次结构组织的,所以我们将此类加载器定义为已存在于正在运行的 Java 应用程序中的给定类加载器的子类。这样,正在运行的 Java 程序的所有类型对于使用 new ClassLoader 加载的动态类型都是可见的。
通常,Java 类加载器会在尝试直接加载给定名称的类型之前查询其父类加载器。这意味着类加载器通常从不加载类型,以防其父类加载器知道具有相同名称的类型。为此,Byte Buddy 提供了一个子级优先类加载器的创建,它尝试在查询其父级之前自行加载类型。除此之外,这种方法类似于上面刚刚提到的方法。请注意,此方法不会覆盖父类加载器的类型,而是隐藏其他类型。
最后,我们可以使用反射将类型注入到现有的 ClassLoader 中。通常,要求类加载器通过其名称提供给定类型。使用反射,我们可以扭转这个原则,调用一个受保护的方法将一个新类注入到类加载器中,而类加载器实际上不知道如何定位这个动态类。
不幸的是,上述方法都有其缺点:
如果我们创建一个新的 ClassLoader,这个类加载器定义了一个新的命名空间。这意味着,只要这些类是由两个不同的类加载器加载的,就可以加载两个具有相同名称的类。这两个类永远不会被 Java 虚拟机视为相等,即使这两个类表示相同的类实现。然而,这条相等规则也适用于 Java 包。这意味着如果两个类没有使用相同的类加载器加载,则类 example.Foo 无法访问另一个类 example.Bar 的包私有方法。此外,如果 example.Bar 扩展了 example.Foo,则任何覆盖的包私有方法都将无效,但会委托给原始实现。
每当加载一个类时,一旦解析了引用另一种类型的代码段,它的类加载器就会查找该类中引用的任何类型。此查找委托给同一个类加载器。想象一个场景,我们动态创建了两个类 example.Foo 和 example.Bar。如果我们将 example.Foo 注入现有的类加载器,这个类加载器可能会尝试定位 example.Bar。然而,这个查找会失败,因为后一个类是动态创建的,对于我们刚刚注入 example.Foo 类的类加载器是不可访问的。因此,反射方法不能用于在类加载期间生效的具有循环依赖关系的类。幸运的是,大多数 JVM 实现在第一次主动使用时懒惰地解析引用的类,这就是为什么类注入通常可以在没有这些限制的情况下工作。此外,在实践中,由 Byte Buddy 创建的类通常不会受到这种循环的影响。
您可能认为遇到循环依赖的可能性不大,因为您一次创建一种动态类型。但是,类型的动态创建可能会触发所谓的辅助类型的创建。这些类型由 Byte Buddy 自动创建,以提供对您正在创建的动态类型的访问。我们将在下一节中了解有关辅助类型的更多信息,现在不要担心它们。但是,因此,我们建议您尽可能通过创建特定的 ClassLoader 而不是将它们注入现有的类加载器来加载动态创建的类。
创建 DynamicType.Unloaded 后,可以使用 ClassLoadingStrategy 加载此类型。如果没有提供这样的策略,Byte Buddy 会根据提供的类加载器推断出这样的策略,并仅为引导类加载器创建一个新的类加载器,其中不能使用反射注入类型,否则为默认值。 Byte Buddy 提供了几种开箱即用的类加载策略,其中每种策略都遵循上述概念之一。这些策略在 ClassLoadingStrategy.Default 中定义,其中 WRAPPER 策略创建一个新的包装类加载器,其中 CHILD_FIRST 策略创建一个具有 child-first 语义的类似类加载器,而 INJECTION 策略使用反射注入动态类型。 WRAPPER 和 CHILD_FIRST 策略也可用于所谓的清单版本,其中即使在加载类之后仍保留类型的二进制格式。这些替代版本使类加载器的类的二进制表示可以通过 ClassLoader::getResourceAsStream 方法访问。但是,请注意,这需要这些类加载器维护对消耗 JVM 堆空间的类的完整二进制表示的引用。因此,如果您计划实际访问二进制格式,则应仅使用清单版本。由于 INJECTION 策略通过反射工作,并且无法更改 ClassLoader::getResourceAsStream 方法的语义,因此它在清单版本中自然不可用。
让我们看看这样的类加载:
Class<?> type = new ByteBuddy() .subclass(Object.class) .make() .load(getClass().getClassLoader(), ClassLoadingStrategy.Default.WRAPPER) .getLoaded(); 复制代码
在上面的例子中,我们创建并加载了一个类。我们使用了 WRAPPER 策略来加载适合大多数情况的类,正如我们之前提到的。最后,getLoaded 方法返回一个 Java 类的实例,该实例代表现在加载的动态类。
注意在加载类时,通过应用当前执行上下文的ProtectionDomain来执行预定义的类加载策略。或者,所有默认策略都通过调用 withProtectionDomain 方法提供显式保护域的规范。使用安全管理器或使用已签名 jar 中定义的类时,定义明确的保护域很重要。
重新加载一个类
在上一节中,我们学习了如何使用 Byte Buddy 来重新定义或重新定义现有类。然而,在 Java 程序的执行过程中,通常不可能保证特定的类尚未加载。 (此外,Byte Buddy 目前仅将加载的类作为其参数,这将在未来版本中改变,现有 API 可用于同样处理未加载的类。)感谢 Java 虚拟机的 HotSwap 功能,但是可以重新定义现有类即使在它们加载之后。此功能可通过 Byte Buddy 的 ClassReloadingStrategy 访问。让我们通过重新定义一个类 Foo 来演示这个策略:
class Foo { String m() { return "foo"; } } class Bar { String m() { return "bar"; } } 复制代码使用 Byte Buddy,我们现在可以轻松地将 Foo 类重新定义为 Bar。使用 HotSwap,这种重新定义甚至适用于预先存在的实例:
ByteBuddyAgent.install(); Foo foo = new Foo(); new ByteBuddy() .redefine(Bar.class) .name(Foo.class.getName()) .make() .load(Foo.class.getClassLoader(), ClassReloadingStrategy.fromInstalledAgent()); assertThat(foo.m(), is("bar")); 复制代码HotSwap 只能使用所谓的 Java 代理访问。这样的代理可以通过在 Java 虚拟机启动时使用 -javaagent 参数指定它来安装,其中参数的参数需要是 Byte Buddy 的代理 jar,可以从 Maven Central 下载。但是,当 Java 应用程序从 Java 虚拟机的 JDK 安装运行时,即使在通过 ByteBuddyAgent.installOnOpenJDK() 启动应用程序之后,Byte Buddy 也可以加载 Java 代理。因为类重定义主要用于实现工具或测试,所以这是一个非常方便的替代方法。从 Java 9 开始,无需安装 JDK,也可以在运行时安装代理。
关于上述示例,首先可能会出现违反直觉的一件事是,指示 Byte Buddy 重新定义 Bar 类型,而 Foo 类型最终被重新定义。 Java 虚拟机通过名称和类加载器来识别类型。因此,通过将 Bar 重命名为 Foo 并应用此定义,我们最终重新定义了将 Bar 重命名为的类型。当然也可以直接重新定义 Foo 而无需重命名不同的类型。
然而,使用 Java 的 HotSwap 特性有一个巨大的缺点。 HotSwap 的当前实现要求重新定义的类在类重新定义之前和之后都应用相同的类模式。这意味着在重新加载类时不允许添加方法或字段。我们已经讨论过,Byte Buddy 为任何重新定位的类定义了原始方法的副本,因此类重新定位不适用于 ClassReloadingStrategy。此外,类重定义不适用于具有显式类初始值设定项方法(类中的静态块)的类,因为该初始值设定项也需要复制到额外的方法中。不幸的是,OpenJDK 已退出扩展 HotSwap 功能,因此无法使用 HotSwap 功能解决此限制。同时,Byte Buddy 的 HotSwap 支持可用于看起来有用的极端情况。否则,在从构建脚本等增强现有类时,类变基和重新定义可能是一个方便的功能。
使用卸载的类
意识到 Java 的 HotSwap 功能的局限性后,人们可能会认为 rebase 和重新定义指令的唯一有意义的应用是在构建期间。通过应用构建时操作,人们可以断言在其初始类加载之前未加载已处理的类,这仅仅是因为此类加载是在 JVM 的不同实例中完成的。然而,Byte Buddy 同样能够处理尚未加载的类。为此,Byte Buddy 对 Java 的反射 API 进行了抽象,例如 Class 实例在内部由 TypeDescription 的实例表示。实际上,Byte Buddy 只知道如何通过实现了 TypeDescription 接口的适配器来处理提供的 Class。与这种抽象相比,最大的优势在于类的信息不需要由 ClassLoader 提供,但可以由任何其他来源提供。
Byte Buddy 提供了一种使用 TypePool 获取类的 TypeDescription 的规范方式。当然也提供了这种池的默认实现。此 TypePool.Default 实现解析类的二进制格式并将其表示为所需的 TypeDescription。与 ClassLoader 类似,它为所表示的类维护一个缓存,该缓存也是可定制的。此外,它通常从 ClassLoader 检索类的二进制格式,但不指示它加载此类。
Java 虚拟机仅在第一次使用时加载类。因此,我们可以安全地重新定义一个类,例如
package foo; class Bar { } 复制代码在运行任何其他代码之前的程序启动时:
class MyApplication { public static void main(String[] args) { TypePool typePool = TypePool.Default.ofSystemLoader(); Class bar = new ByteBuddy() .redefine(typePool.describe("foo.Bar").resolve(), // do not use 'Bar.class' ClassFileLocator.ForClassLoader.ofSystemLoader()) .defineField("qux", String.class) // we learn more about defining fields later .make() .load(ClassLoader.getSystemClassLoader()); assertThat(bar.getDeclaredField("qux"), notNullValue()); } } 复制代码通过在断言语句中首次使用之前显式加载重新定义的类,我们可以阻止 JVM 的内置类加载。这样,重新定义的 foo.Bar 定义就会在我们的应用程序运行时加载和使用。但是请注意,当我们使用 TypePool 提供描述时,我们不会通过类文字引用类。如果我们确实为 foo.Bar 使用了类文字,JVM 就会在我们有机会重新定义它之前加载这个类,我们的重新定义尝试将无效。另外,请注意,在处理未加载的类时,我们还需要指定一个 ClassFileLocator,它允许定位类的类文件。在上面的示例中,我们只是创建了一个类文件定位器,它会扫描正在运行的应用程序的类路径以查找此类文件。
创建 Java 代理
当应用程序变得更大并变得更加模块化时,在特定程序点应用这样的转换当然是一个需要强制执行的繁琐约束。并且确实有更好的方法来按需应用此类重新定义。使用 Java 代理,可以直接拦截在 Java 应用程序中进行的任何类加载活动。 Java 代理是作为一个简单的 jar 文件实现的,它具有一个入口点,该入口点在此 jar 文件的清单文件中指定,如链接资源下所述。使用 Byte Buddy,通过使用 AgentBuilder 可以直接实现此类代理。假设我们之前定义了一个名为 ToString 的简单注解,那么通过实现 Agent 的 premain 方法来为所有注解类实现 toString 方法将是微不足道的,如下所示:
class ToStringAgent { public static void premain(String arguments, Instrumentation instrumentation) { new AgentBuilder.Default() .type(isAnnotatedWith(ToString.class)) .transform(new AgentBuilder.Transformer() { @Override public DynamicType.Builder transform(DynamicType.Builder builder, TypeDescription typeDescription, ClassLoader classloader) { return builder.method(named("toString")) .intercept(FixedValue.value("transformed")); } }).installOn(instrumentation); } } 复制代码作为应用上述 AgentBuilder.Transformer 的结果,注释类的所有 toString 方法现在将返回已转换。我们将在接下来的部分中了解有关 Byte Buddy 的 DynamicType.Builder 的所有信息,现在不要担心这个类。上面的代码当然会导致一个微不足道且毫无意义的应用程序。正确使用这个概念,渲染是一个强大的工具,可以轻松实现面向方面的编程。
请注意,也可以在使用代理时检测由引导类加载器加载的类。然而,这需要一些准备。首先,引导类加载器由空值表示,这使得无法使用反射在该类加载器中加载类。然而,有时需要将辅助类加载到检测类的类加载器中以支持类的实现。为了将类加载到引导类加载器中,Byte Buddy 可以创建 jar 文件并将这些文件添加到引导类加载器的加载路径中。然而,为了实现这一点,需要将这些类保存到磁盘。可以使用 enableBootstrapInjection 命令指定这些类的文件夹,该命令还采用 Instrumentation 接口的实例以附加类。请注意,检测类使用的所有用户类也需要放在引导程序搜索路径上,这可以使用检测接口。
在 Android 应用程序中加载类
Android 使用不同的类文件格式,使用 dex 文件,这些文件不在 Java 类文件格式的布局中。此外,通过继承 Dalvik 虚拟机的 ART 运行时,Android 应用程序在安装到 Android 设备之前被编译为本机代码。因此,只要应用程序未与其 Java 源代码显式部署在一起,Byte Buddy 就不能再重新定义或重新定义类,否则没有中间代码表示可以解释。然而,Byte Buddy 仍然能够使用 DexClassLoader 和内置的 dex 编译器来定义新类。为此,Byte Buddy 提供了包含 AndroidClassLoadingStrategy 的 byte-buddy-android 模块,该模块允许从 Android 应用程序中加载动态创建的类。为了发挥作用,它需要一个用于写入临时文件和已编译类文件的文件夹。此文件夹不得在不同的应用程序之间共享,因为 Android 的安全管理器禁止这样做。
使用泛型类型
Byte Buddy 正在处理由 Java 编程语言定义的泛型类型。 Java 运行时不考虑泛型类型,它只处理泛型类型的擦除。但是,泛型类型仍然嵌入到任何 Java 类文件中,并由 Java 反射 API 公开。因此,有时将泛型信息包含到生成的类中是有意义的,因为泛型类型信息会影响其他库和框架的行为。当 Java 编译器将类作为库进行持久化和处理时,嵌入泛型类型信息也很重要。
在对类进行子类化、实现接口或声明字段或方法时,由于上述原因,Byte Buddy 接受 Java 类型而不是已擦除的类。还可以使用 TypeDescription.Generic.Builder 显式定义泛型类型。 Java 泛型类型与类型擦除的一个重要区别是类型变量的上下文含义。由某种类型定义的某个名称的类型变量,当另一种类型以相同的名称声明相同的类型变量时,并不一定表示相同的类型。因此,当将 Type 实例传递给库时,Byte Buddy 会在生成的类型或方法的上下文中重新绑定所有表示类型变量的泛型类型。
Byte Buddy 还会在创建类型时透明地插入桥接方法。桥接方法由 MethodGraph.Compiler 解析,它是任何 ByteBuddy 实例的属性。默认方法图编译器的行为类似于 Java 编译器并处理任何类文件的泛型类型信息。然而,对于 Java 以外的其他语言,不同的方法图编译器可能是合适的。
字段和方法
我们在上一节中创建的大多数类型都没有定义任何字段或方法。但是,通过对 Object 进行子类化,创建的类将继承其超类定义的方法。让我们验证这个 Java 琐事并在动态类型的实例上调用 toString 方法。我们可以通过反射调用创建的类的构造函数来获取实例。
String toString = new ByteBuddy() .subclass(Object.class) .name("example.Type") .make() .load(getClass().getClassLoader()) .getLoaded() .newInstance() // Java reflection API .toString(); 复制代码Object#toString 方法的实现返回实例的完全限定类名和实例哈希码的十六进制表示的串联。事实上,在创建的实例上调用 toString 方法会返回类似 example.Type@340d1fa5 的内容。
当然,到这里我们还没有完成。创建动态类的主要动机是定义新逻辑的能力。为了演示这是如何完成的,让我们从一些简单的事情开始。我们要覆盖 toString 方法并返回 Hello World!而不是以前的默认值:
String toString = new ByteBuddy() .subclass(Object.class) .name("example.Type") .method(named("toString")).intercept(FixedValue.value("Hello World!")) .make() .load(getClass().getClassLoader()) .getLoaded() .newInstance() .toString(); 复制代码我们添加到代码中的行包含 Byte Buddy 的领域特定语言中的两条指令。第一条指令是方法,它允许我们选择要覆盖的任意数量的方法。这个选择是通过移交一个 ElementMatcher 来应用的,它作为一个谓词来决定每个可覆盖的方法是否应该被覆盖。 Byte Buddy 带有许多预定义的方法匹配器,这些匹配器收集在 ElementMatchers 类中。通常,您会静态导入此类,以便生成的代码更自然地阅读。上面的例子也假设了这样的静态导入,其中我们使用了命名方法匹配器,它通过它们的确切名称来选择方法。请注意,预定义的方法匹配器是可组合的。这样,我们可以更详细地描述方法选择,例如:
named("toString").and(returns(String.class)).and(takesArguments(0)) 复制代码后一种方法匹配器通过其完整的 Java 签名描述 toString 方法,因此只匹配此特定方法。然而,在给定的上下文中,我们知道没有其他名为 toString 的方法具有不同的签名,这样我们的原始方法匹配器就足够了。
选择 toString 方法后,第二条指令拦截确定应该覆盖给定选择的所有方法的实现。为了知道如何实现一个方法,该指令需要一个类型为 Implementation 的参数。在上面的示例中,我们使用了 Byte Buddy 附带的 FixedValue 实现。正如该类的名称所暗示的那样,该实现实现了一个始终返回给定值的方法。在本节稍后部分,我们将更详细地了解 FixedValue 实现。现在,让我们更仔细地看看方法选择。
到目前为止,我们只拦截了一个方法。然而,在实际应用中,事情可能会更复杂,我们可能希望应用不同的规则来覆盖不同的方法。让我们看一个这样的场景的例子:
class Foo { public String bar() { return null; } public String foo() { return null; } public String foo(Object o) { return null; } } Foo dynamicFoo = new ByteBuddy() .subclass(Foo.class) .method(isDeclaredBy(Foo.class)).intercept(FixedValue.value("One!")) .method(named("foo")).intercept(FixedValue.value("Two!")) .method(named("foo").and(takesArguments(1))).intercept(FixedValue.value("Three!")) .make() .load(getClass().getClassLoader()) .getLoaded() .newInstance(); 复制代码在上面的例子中,我们为覆盖方法定义了三种不同的规则。在研究代码时,您会注意到第一条规则涉及由 Foo 定义的任何方法,即示例类中的所有三个方法。第二条规则匹配名为 foo 的两个方法,它是前一个选择的子集。而最后一条规则只匹配 foo(Object) 方法,这是对前一个选择的进一步减少。但是考虑到这个选择重叠,Byte Buddy 如何决定哪个规则应用于哪个方法?
Byte Buddy 以堆栈形式组织覆盖方法的规则。这意味着每当你注册一个新规则来覆盖一个方法时,它会被推到这个堆栈的顶部,并且总是首先应用,直到添加一个新规则,然后该规则将具有更高的优先级。对于上面的例子,这意味着:
bar() 方法首先与 named("foo").and(takesArguments(1)) 匹配,然后与 named("foo") 匹配,其中两次匹配尝试都为否定。最后,isDeclaredBy(Foo.class) 匹配器允许覆盖 bar() 方法以返回 One!。
类似地,首先将 foo() 方法与 named("foo").and(takesArguments(1)) 匹配,其中缺少的参数导致匹配失败。在此之后,named("foo") 匹配器确定一个正匹配,从而覆盖 foo() 方法以返回 Two!。
foo(Object) 立即被 named("foo").and(takesArguments(1)) 匹配器匹配,这样重写的实现就返回 Three!。
由于这种组织,您应该始终最后注册更具体的方法匹配器。否则,之后注册的任何不太具体的方法匹配器可能会阻止应用您之前定义的规则。请注意,ByteBuddy 配置允许定义 ignoreMethod 属性。与此方法匹配器成功匹配的方法永远不会被覆盖。默认情况下,Byte Buddy 不会覆盖任何合成方法。
在某些情况下,您可能希望定义一个不覆盖超类型或接口的方法的新方法。这也可以使用 Byte Buddy。为此,您可以调用可以定义签名的defineMethod。定义方法后,您需要提供一个实现,就像方法匹配器识别的方法一样。请注意,在方法定义之后注册的方法匹配器可能会通过我们之前讨论的堆叠原则来取代此实现。
使用defineField,Byte Buddy 允许为给定类型定义字段。在 Java 中,字段永远不会被覆盖,而只能被隐藏。为此,没有可用的字段匹配等。
有了关于如何选择方法的这些知识,我们就可以学习如何实现这些方法了。为此,我们现在查看 Byte Buddy 附带的预定义实现。定义自定义实现在其自己的部分中进行了讨论,并且仅适用于需要非常自定义方法实现的用户。
仔细看看固定值
我们已经看到了 FixedValue 实现。顾名思义,FixedValue 实现的方法只是返回一个提供的对象。一个类能够以两种不同的方式记住这样一个对象:
固定值被写入类的常量池。常量池是 Java 类文件格式中的一个部分,包含许多描述任何类的属性的无状态值。常量池主要用于记住类的属性,例如类的名称或方法的名称。除了这些反射属性之外,常量池还有用于存储在方法或类的字段中使用的任何字符串或原始值的空间。除了字符串和原始值,类池还可以存储对其他类型的引用。
该值存储在类的静态字段中。为此,一旦类加载到 Java 虚拟机中,就必须为该字段分配给定的值。为此,每个动态创建的类都附带一个 TypeInitializer,它可以配置为执行此类显式初始化。当您指示加载 DynamicType.Unloaded 时,Byte Buddy 会自动触发其类型初始值设定项,以便该类可以使用。因此,您通常不需要担心类型初始值设定项。但是,如果您想加载要在 Byte Buddy 之外加载的动态类,那么在加载这些类之后手动运行它们的类型初始值设定项是很重要的。否则,例如,FixedValue 实现将返回 null 而不是所需的值,因为静态字段从未分配过此值。然而,许多动态类型可能不需要显式初始化。因此,可以通过调用其 isAlive 方法来查询类的类型初始值设定项的活跃度。如果您需要手动触发 TypeInitializer,您会发现它由 DynamicType 接口公开。
当你通过 FixedValue#value(Object) 实现一个方法时,Byte Buddy 会分析参数的类型并定义它尽可能存储在动态类型的类池中,否则将值存储在静态字段中。但是请注意,如果值存储在类池中,则所选方法返回的实例可能具有不同的对象标识。因此,您可以通过使用 FixedValue#reference(Object) 来指示 Byte Buddy 始终将对象存储在静态字段中。后一种方法被重载,因此您可以提供字段名称作为第二个参数。否则,字段名称会自动从对象的哈希码中派生出来。这种行为的一个例外是空值。空值永远不会存储在字段中,而是简单地由其文字表达式表示。
在这种情况下,您可能想知道类型安全。显然,您可以定义一个方法来返回无效值:
new ByteBuddy() .subclass(Foo.class) .method(isDeclaredBy(Foo.class)).intercept(FixedValue.value(0)) .make(); 复制代码
很难在 Java 的类型系统中防止编译器进行这种无效的实现。相反,Byte Buddy 将在创建类型时抛出 IllegalArgumentException 并且将整数非法分配给返回 String 的方法生效。 Byte Buddy 尽最大努力确保其创建的所有类型都是合法的 Java 类型,并通过在创建非法类型期间抛出异常来快速失败。
Byte Buddy 的分配行为是可定制的。同样,Byte Buddy 只提供了一个模拟 Java 编译器赋值行为的合理默认值。因此,Byte Buddy 允许将类型分配给它的任何超类型,并且它还会考虑装箱原始值或拆箱它们的包装表示。但是请注意,Byte Buddy 目前不完全支持泛型类型,只会考虑类型擦除。因此,有可能是 Byte Buddy 造成堆污染。除了使用预定义的分配器,您始终可以实现自己的分配器,它能够进行 Java 编程语言中不隐含的类型转换。我们将在本教程的最后一节研究此类自定义实现。现在,我们只需要提及您可以通过在任何 FixedValue 实现上调用 withAssigner 来定义此类自定义分配器。
委托方法调用
在很多场景下,从一个方法中返回一个固定值当然是不够的。为了获得更大的灵活性,Byte Buddy 提供了 MethodDelegation 实现,它在响应方法调用时提供了最大的自由度。方法委托定义了动态创建类型的方法,以将任何调用转发到可能存在于动态类型之外的另一个方法。这样,动态类的逻辑可以使用普通的 Java 来表示,而只能通过代码生成来实现与另一个方法的绑定。在讨论细节之前,让我们看一个使用 MethodDelegation 的例子:
class Source { public String hello(String name) { return null; } } class Target { public static String hello(String name) { return "Hello " + name + "!"; } } String helloWorld = new ByteBuddy() .subclass(Source.class) .method(named("hello")).intercept(MethodDelegation.to(Target.class)) .make() .load(getClass().getClassLoader()) .getLoaded() .newInstance() .hello("World"); 复制代码在示例中,我们将 Source#hello(String) 方法的调用委托给 Target 类型,以便该方法返回 Hello World!而不是空。为此,MethodDelegation 实现标识了 Target 类型的任何可调用方法,并标识了这些方法之间的最佳匹配。在上面的例子中,这是微不足道的,因为 Target 类型只定义了一个静态方法,其中方法的参数、返回类型和名称与 Source#name(String) 的参数、返回类型和名称方便地相同。
实际上,委托目标方法的决定很可能会更复杂。那么如果有实际的选择,Byte Buddy 如何在方法之间做出决定呢?为此,让我们假设 Target 类定义如下:
class Target { public static String intercept(String name) { return "Hello " + name + "!"; } public static String intercept(int i) { return Integer.toString(i); } public static String intercept(Object o) { return o.toString(); } } 复制代码您可能已经注意到,上述方法现在都称为拦截。 Byte Buddy 不要求目标方法与源方法的命名相同。我们很快就会仔细研究这个问题。更重要的是,如果您使用更改后的 Target 定义运行前一个示例,您会观察到 named(String) 方法绑定到了intercept(String)。但这是为什么呢?显然,intercept(int) 方法无法接收源方法的 String 参数,因此甚至不被视为可能的匹配项。但是,对于可以绑定的intercept(Object) 方法,情况并非如此。为了解决这个歧义,Byte Buddy 再次模仿 Java 编译器,选择绑定最具体参数类型的方法。请记住 Java 编译器如何为重载方法选择绑定!由于 String 比 Object 更具体,因此intercept(String) 类最终在三个备选方案中选择。
根据目前的信息,您可能认为方法绑定算法具有相当严格的性质。然而,我们还没有讲述完整的故事。到目前为止,我们只观察到约定优于配置原则的另一个示例,如果默认值不符合实际要求,则可以更改。实际上,MethodDelegation 实现与注释一起工作,其中参数的注释决定应该为其分配什么值。但是,如果未找到注释,Byte Buddy 会将参数视为使用 @Argument 进行注释。后一个注释导致 Byte Buddy 将源方法的第 n 个参数分配给带注释的目标。当没有显式添加注释时,n 的值设置为注释参数的索引。根据这个规则,Byte Buddy 对待
void foo(Object o1, Object o2) 复制代码
好像所有参数都被注释为:
void foo(@Argument(0) Object o1, @Argument(1) Object o2) 复制代码
结果,检测方法的第一个和第二个参数被分配给拦截器。如果被拦截的方法没有声明至少两个参数,或者如果注释的参数类型不能从被检测方法的参数类型中分配,则相关的拦截器方法将被丢弃。
除了@Argument 注释,还有其他几个预定义的注释可以与 MethodDelegation 一起使用:
带有@AllArguments 注释的参数必须是数组类型,并被分配一个包含所有源方法参数的数组。为此,所有源方法参数必须可分配给数组的组件类型。如果不是这种情况,则不会将当前目标方法视为绑定到源方法的候选方法。
@This 注释诱导动态类型的实例的分配,在该实例上当前调用了被拦截的方法。如果带注释的参数不可分配给动态类型的实例,则当前方法不被视为绑定到源方法的候选方法。请注意,调用此实例上的任何方法都将导致调用潜在的检测方法实现。要调用覆盖的实现,您需要使用下面讨论的 @Super 注释。使用 @This 批注访问实例字段的典型原因。
使用@Origin 注释的参数必须用于任何类型 Method、Constructor、Executable、Class、MethodHandle、MethodType、String 或 int。根据参数的类型,它被分配了对现在检测的原始方法或构造函数的方法或构造函数引用,或对动态创建的类的引用。使用 Java 8 时,还可以通过在拦截器中使用 Executable 类型来接收方法或构造函数引用。如果带注释的参数是字符串,则为该参数分配方法的 toString 方法将返回的值。通常,我们建议尽可能使用这些 String 值作为方法标识符,并且不鼓励使用 Method 对象,因为它们的查找会引入显着的运行时开销。为了避免这种开销,@Origin 注释还提供了一个用于缓存此类实例以供重用的属性。请注意,MethodHandle 和 MethodType 存储在类的常量池中,因此使用这些常量的类必须至少是 Java 版本 7。而不是使用反射来反射调用另一个对象上的拦截方法,我们还建议使用 @本节稍后将讨论的管道注释。在 int 类型的参数上使用 @Origin 注释时,它被分配了检测方法的修饰符。
除了使用预定义的注解之外,Byte Buddy 还允许您通过注册一个或多个 ParameterBinders 来定义自己的注解。我们将在本教程的最后一部分研究此类自定义。
除了我们目前讨论的四个注解之外,还有另外两个预定义注解授予对动态类型方法的超级实现的访问权限。这样,动态类型可以例如向类添加方面,例如方法调用的日志记录。使用@SuperCall 注释,甚至可以从动态类外部执行对方法的超级实现的调用,如以下示例所示:
class MemoryDatabase { public List<String> load(String info) { return Arrays.asList(info + ": foo", info + ": bar"); } } class LoggerInterceptor { public static List<String> log(@SuperCall Callable<List<String>> zuper) throws Exception { System.out.println("Calling database"); try { return zuper.call(); } finally { System.out.println("Returned from database"); } } } MemoryDatabase loggingDatabase = new ByteBuddy() .subclass(MemoryDatabase.class) .method(named("load")).intercept(MethodDelegation.to(LoggerInterceptor.class)) .make() .load(getClass().getClassLoader()) .getLoaded() .newInstance(); 复制代码从上面的例子中可以明显看出,super 方法是通过将 Callable 的一些实例注入到 LoggerInterceptor 中来调用的,LoggerInterceptor 会从它的 call 方法中调用 MemoryDatabase#load(String) 的原始、非覆盖实现。这个辅助类在 Byte Buddy 的术语中称为 AuxiliaryType。辅助类型由 Byte Buddy 按需创建,并且在创建类后可以从 DynamicType 接口直接访问。由于此类辅助类型,手动创建一种动态类型可能会导致创建多个有助于实现原始类的附加类型。最后,请注意 @SuperCall 注释也可以用于 Runnable 类型,但原始方法的返回值被删除。
您可能仍然想知道这个辅助类型如何能够调用另一种类型的超级方法,而这在 Java 中通常是禁止的。然而,仔细检查后,这种行为很常见,类似于编译以下 Java 源代码片段时生成的已编译代码:
class LoggingMemoryDatabase extends MemoryDatabase { private class LoadMethodSuperCall implements Callable { private final String info; private LoadMethodSuperCall(String info) { this.info = info; } @Override public Object call() throws Exception { return LoggingMemoryDatabase.super.load(info); } } @Override public List<String> load(String info) { return LoggerInterceptor.log(new LoadMethodSuperCall(info)); } } 复制代码然而,有时,您可能希望使用与在方法的原始调用中分配的参数不同的参数来调用超级方法。这在 Byte Buddy 中也可以通过使用 @Super 注释来实现。这个注解触发了另一个 AuxiliaryType 的创建,它现在扩展了一个超类或一个有问题的动态类型的接口。与之前类似,辅助类型覆盖所有方法以在动态类型上调用它们的超级实现。这样,可以实现上一个示例中的示例记录器拦截器来更改实际调用:
class ChangingLoggerInterceptor { public static List<String> log(String info, @Super MemoryDatabase zuper) { System.out.println("Calling database"); try { return zuper.load(info + " (logged access)"); } finally { System.out.println("Returned from database"); } } } 复制代码请注意,分配给用@Super 注释的参数的实例与动态类型的实际实例具有不同的身份!因此,通过该参数可访问的任何实例字段都不能反映实际实例的字段。此外,辅助实例的不可覆盖方法不会委托它们的调用,而是保留原始实现,这在调用它们时会导致荒谬的行为。最后,如果用@Super 注释的参数不代表相关动态类型的超类型,则该方法不被视为其任何方法的绑定目标。
因为@Super 注释允许使用任何类型,所以我们可能需要提供有关如何构造此类型的信息。默认情况下,Byte Buddy 尝试使用类的默认构造函数。这始终适用于隐式扩展 Object 类型的接口。但是,当扩展动态类型的超类时,该类甚至可能不提供默认构造函数。如果是这种情况,或者如果应该使用特定的构造函数来创建这样的辅助类型,@Super 注释允许通过将其参数类型设置为注释的 constructorParameters 属性来识别不同的构造函数。然后将通过为每个参数分配相应的默认值来调用此构造函数。或者,也可以使用 Super.Instantiation.UNSAFE 策略来创建类,该策略利用 Java 内部类来创建辅助类型,而无需调用任何构造函数。但是,请注意,此策略不一定可移植到非 Oracle JVM,并且在未来的 JVM 版本中可能不再可用。直到今天,这种不安全的实例化策略所使用的内部类几乎可以在任何 JVM 实现中找到。
此外,您可能已经注意到上面的 LoggerInterceptor 声明了一个已检查的异常。另一方面,调用此方法的检测源方法不声明任何已检查的异常。通常,Java 编译器会拒绝编译这样的调用。但是,与编译器相反,Java 运行时不会将已检查异常与未检查异常区别对待,并允许此调用。出于这个原因,我们决定忽略已检查的异常并在其使用中给予充分的灵活性。但是,从动态创建的方法抛出未声明的检查异常时要小心,因为遇到此类异常可能会使应用程序的用户感到困惑。
您可能已经注意到方法委托模型中的另一个警告。虽然静态类型非常适合实现方法,但严格类型会限制代码的重用。要了解原因,请考虑以下示例:
class Loop { public String loop(String value) { return value; } public int loop(int value) { return value; } } 复制代码由于上述类的方法描述了两个具有不兼容类型的相似签名,因此您通常无法使用单个拦截器方法检测这两个方法。相反,您必须提供两个具有不同签名的不同目标方法才能满足静态类型检查。为了克服这个限制,Byte Buddy 允许使用 @RuntimeType 注释方法和方法参数,它指示 Byte Buddy 暂停严格类型检查以支持运行时类型转换:
class Interceptor { @RuntimeType public static Object intercept(@RuntimeType Object value) { System.out.println("Invoked method with: " + value); return value; } } 复制代码使用上述目标方法,我们现在可以为两种源方法提供单一的拦截方法。请注意,Byte Buddy 还能够装箱和拆箱原始值。但是,请注意,@RuntimeType 的使用是以放弃类型安全为代价的,如果您混淆了不兼容的类型,您可能最终会遇到 ClassCastException。
与@SuperCall 等效,Byte Buddy 带有@DefaultCall 注释,它允许调用默认方法而不是调用方法的超级方法。仅当被拦截的方法实际上被检测类型直接实现的接口声明为默认方法时,才考虑将带有此参数注释的方法用于绑定。类似地,如果被检测的方法没有定义非抽象超级方法,则 @SuperCall 注释会阻止方法的绑定。但是,如果您想对特定类型调用默认方法,则可以使用特定接口指定 @DefaultCall 的 targetType 属性。根据此规范,Byte Buddy 注入一个代理实例,该实例调用给定接口类型的默认方法(如果存在此类方法)。否则,带有参数注解的目标方法不被视为委托目标。显然,默认方法调用仅适用于在 Java 8 或更新版本的类文件中定义的类。类似地,除了@Super 注解之外,还有一个@Default 注解,它注入了一个代理以显式调用特定的默认方法。
我们已经提到您可以使用任何 MethodDelegation 定义和注册自定义注释。 Byte Buddy 带有一个可以使用但仍需要明确安装和注册的注释。通过使用@Pipe 批注,您可以将拦截的方法调用转发到另一个实例。 @Pipe 注释没有预先注册到 MethodDelegation 中,因为 Java 类库在定义 Function 类型的 Java 8 之前没有提供合适的接口类型。因此,您需要显式地提供具有单个非静态方法的类型,该方法将对象作为其参数并返回另一个对象作为结果。请注意,只要方法类型受 Object 类型的约束,您仍然可以使用泛型类型。当然,如果您使用的是 Java 8,Function 类型是一个可行的选择。当对参数的参数调用方法时,Byte Buddy 将参数转换为方法的声明类型,并使用与原始方法调用相同的参数调用被拦截的方法。在我们看一个例子之前,让我们定义一个可以在 Java 5 及更高版本中使用的自定义类型:
interface Forwarder<T, S> { T to(S target); } 复制代码使用这种类型,我们现在可以通过将方法调用转发到现有实例来实现记录上述 MemoryDatabase 访问的新解决方案:
class ForwardingLoggerInterceptor { private final MemoryDatabase memoryDatabase; // constructor omitted public List<String> log(@Pipe Forwarder<List<String>, MemoryDatabase> pipe) { System.out.println("Calling database"); try { return pipe.to(memoryDatabase); } finally { System.out.println("Returned from database"); } } } MemoryDatabase loggingDatabase = new ByteBuddy() .subclass(MemoryDatabase.class) .method(named("load")).intercept(MethodDelegation.withDefaultConfiguration() .withBinders(Pipe.Binder.install(Forwarder.class))) .to(new ForwardingLoggerInterceptor(new MemoryDatabase())) .make() .load(getClass().getClassLoader()) .getLoaded() .newInstance(); 复制代码在上面的示例中,我们仅将调用转发到我们在本地创建的另一个实例。然而,与通过子类化类型来拦截方法相比,这种方法允许增强已经存在的实例。此外,您通常会在实例级别注册拦截器,而不是在类级别注册静态拦截器。
到目前为止,我们已经看到了大量的 MethodDelegation 实现。但在我们继续之前,我们想更详细地了解 Byte Buddy 如何选择目标方法。我们已经描述了 Byte Buddy 如何通过比较参数类型来解析最具体的方法,但还有更多内容。在 Byte Buddy 确定有资格绑定到给定源方法的候选方法后,它将解析委托给一个 AmbiguityResolvers 链。同样,您可以自由实现自己的歧义解析器,它可以补充甚至替换 Byte Buddy 的默认值。如果没有这样的改变,歧义解析器链会尝试通过以如下相同的顺序应用以下规则来识别唯一的目标方法:
可以通过使用@BindingPriority 对方法进行注释来为其分配显式优先级。如果一种方法的优先级高于另一种方法,则优先级高的方法总是优先于优先级较低的方法。此外,@IgnoreForBinding 注释的方法永远不会被视为目标方法。
如果源方法和目标方法具有相同的名称,则该目标方法优先于具有不同名称的其他目标方法。
如果两个方法使用@Argument 绑定了一个源方法的相同参数,则考虑具有最具体参数类型的方法。在这种情况下,通过不注释参数来显式或隐式提供注释并不重要。解析算法的工作原理类似于 Java 编译器的算法,用于解析对重载方法的调用。如果两种类型同样具体,则绑定更多参数的方法被视为目标。如果在此解析阶段应为参数分配参数而不考虑参数类型,则可以通过将注释的 bindingMechanic 属性设置为 BindingMechanic.ANONYMOUS 来实现。此外,请注意,每个目标方法上的每个索引值的非匿名参数都必须是唯一的,这样解析算法才能正常工作。
如果一个目标方法的参数比另一个目标方法多,则前一种方法优于后者。
到目前为止,我们只是通过在 MethodDelegation.to(Target.class) 中命名特定类来将方法调用委托给静态方法。然而,也可以委托给实例方法或构造函数:
通过调用 MethodDelegation.to(new Target()),可以将方法调用委托给 Target 类的任何实例方法。请注意,这包括在实例类层次结构中任何位置定义的方法,包括在 Object 类中定义的方法。您可能希望通过在任何 MethodDelegation 上调用 filter(ElementMatcher) 将过滤器应用于方法委托来限制候选方法的范围。 ElementMatcher 类型与之前用于在 Byte Buddy 的域特定语言中选择源方法的类型相同。作为方法委托目标的实例存储在静态字段中。与固定值的定义类似,这需要 TypeInitializer 的定义。除了将委托存储在静态字段中,您还可以通过 MethodDelegation.toField(String) 定义任何字段的使用,其中参数指定所有方法委托转发到的字段名称。在对此类动态类的实例调用方法之前,请始终记住为此字段赋值。否则,方法委托将导致 NullPointerException。
方法委托可用于构造给定类型的实例。通过使用 MethodDelegation.toConstructor(Class),对被拦截方法的任何调用都会返回给定目标类型的新实例。
正如您刚刚了解到的,MethodDelegation 检查注解以调整其绑定逻辑。这些注释是特定于 Byte Buddy 的,但这并不意味着被注释的类以任何方式依赖于 Byte Buddy。相反,Java 运行时只是忽略在加载类时在类路径上找不到的注释类型。这意味着在创建动态类后不再需要 Byte Buddy。这意味着即使类路径上没有 Byte Buddy,您也可以在另一个 JVM 进程中加载动态类及其委托方法调用的类型。
还有几个预定义的注释可以与我们只想简要命名的 MethodDelegation 一起使用。如果您想阅读有关这些注释的更多信息,可以在代码文档中找到更多信息。这些注释是:
@Empty:应用这个注解,Byte Buddy 注入了参数类型的默认值。对于原始类型,这相当于数字零,对于引用类型,这是空值。使用此注释是为了使拦截器的参数无效。
@StubValue:通过这个注解,被注解的参数被注入被拦截方法的存根值。对于引用返回类型和 void 方法,注入 null 值。对于返回原始值的方法,注入了等效的装箱类型 0。这在定义通用拦截器时会很有帮助,该拦截器在使用 @RuntimeType 注释时返回 Object 类型。通过返回注入的值,该方法表现为一个存根,同时正确考虑原始返回类型。
@FieldValue:此注释在检测类型的类层次结构中定位一个字段,并将该字段的值注入带注释的参数中。如果无法为带注释的参数找到兼容类型的可见字段,则目标方法未绑定。
@FieldProxy:使用此注释,Byte Buddy 为给定字段注入访问器。访问的字段可以通过其名称显式指定,也可以从 getter 或 setter 方法名称派生,以防被拦截的方法表示这样的方法。在使用这个注解之前,它需要被显式安装和注册,类似于@Pipe注解。
@Morph:此注释的工作方式与 @SuperCall 注释非常相似。但是,使用此注释允许指定用于调用 super 方法的参数。请注意,仅当您需要使用与原始调用不同的参数调用超级方法时,才应使用此注释,因为使用 @Morph 注释需要对所有参数进行装箱和拆箱。如果要调用特定的超级方法,请考虑使用 @Super 注释来创建类型安全代理。在使用这个注解之前,它需要被显式安装和注册,类似于@Pipe注解。
@SuperMethod:此注解只能用于可从 Method 分配的参数类型。分配的方法设置为允许调用原始代码的合成访问器方法。请注意,使用此注释会导致为代理类创建一个公共访问器,该访问器允许在不传递安全管理器的情况下外部调用 super 方法。
@DefaultMethod:类似于@SuperMethod,但用于默认方法调用。如果默认方法调用只有一种可能性,则在唯一类型上调用默认方法。否则,可以将类型显式指定为注释属性。
调用超级方法
顾名思义,SuperMethodCall 实现可用于调用方法的超级实现。乍一看,超级实现的唯一调用似乎不是很有用,因为这不会改变实现,而只会复制现有的逻辑。但是,通过覆盖一个方法,您可以更改一个方法及其参数的注释,我们将在下一节中讨论这一点。然而,在 Java 中调用 super 方法的另一个基本原理是构造函数的定义,该构造函数必须始终调用其超类型或其自身类型的另一个构造函数。
到目前为止,我们只是假设动态类型的构造函数将始终类似于其直接超类型的构造函数。例如,我们可以调用
new ByteBuddy() .subclass(Object.class) .make() 复制代码
使用单个默认构造函数创建 Object 的子类,该构造函数定义为简单地调用其直接超构造函数,即 Object 的默认构造函数。但是,这种行为不是字节好友规定的。相反,上面的代码是调用的快捷方式
new ByteBuddy() .subclass(Object.class, ConstructorStrategy.Default.IMITATE_SUPER_TYPE) .make() 复制代码
其中 ConstructorStrategy 负责为任何给定的类创建一组预定义的构造函数。除了上述复制动态类型的直接超类的每个可见构造函数的策略外,还有其他三种预定义策略:一种根本不创建任何构造函数,一种创建调用直接超类的默认构造函数的默认构造函数,以及如果不存在这样的构造函数并且仅模仿超类型的公共构造函数,则抛出异常。
在 Java 类文件格式中,构造函数通常与方法没有区别,因此 Byte Buddy 允许像这样对待它们。但是,构造函数需要包含对另一个构造函数的硬编码调用,以供 Java 运行时接受。出于这个原因,除了 SuperMethodCall 之外的大多数预定义实现在应用于构造函数时都将无法创建有效的 Java 类。
但是,通过使用自定义实现,您可以通过实现自定义 ConstructorStrategy 或使用 defineConstructor 方法在 Byte Buddy 的领域特定语言中定义单个构造函数来定义自己的构造函数。此外,我们计划向 Byte Buddy 添加新功能,以便定义更复杂的现成构造函数。
对于类变基和类重新定义,构造函数当然只是简单地保留了,这使得 ConstructorStrategy 的规范过时了。相反,为了复制这些保留的构造函数(和方法)实现,需要指定一个 ClassFileLocator,它允许查找包含这些构造函数定义的原始类文件。 Byte Buddy 会尽力自行识别原始类文件的位置,例如通过查询相应的 ClassLoader 或查看应用程序的类路径。然而,在处理习惯类加载器时,查找可能仍然不成功。然后,可以提供自定义 ClassFileLocator。
调用默认方法
在版本 8 中,Java 编程语言引入了接口的默认方法。在 Java 中,默认方法调用由类似于调用超级方法的语法表示。作为唯一的差异,默认方法调用命名了定义该方法的接口。这是必要的,因为如果两个接口定义了具有相同签名的方法,则默认方法调用可能不明确。因此,Byte Buddy 的 DefaultMethodCall 实现采用优先级接口列表。当拦截一个方法时, DefaultMethodCall 调用第一个提到的接口上的默认方法。例如,假设我们要实现以下两个接口:
interface First { default String qux() { return "FOO"; } } interface Second { default String qux() { return "BAR"; } } 复制代码如果我们现在创建了一个实现两个接口的类并实现了 qux 方法来调用默认方法,则此调用可以表达对 First 或 Second 接口上定义的默认方法的调用。但是,通过指定 DefaultMethodCall 来优先考虑 First 接口,Byte Buddy 会知道它应该调用后一个接口的方法而不是替代方法。
new ByteBuddy(ClassFileVersion.JAVA_V8) .subclass(Object.class) .implement(First.class) .implement(Second.class) .method(named("qux")).intercept(DefaultMethodCall.prioritize(First.class)) .make() 复制代码请注意,在 Java 8 之前的类文件版本中定义的任何 Java 类都不支持默认方法。此外,您应该知道,与 Java 编程语言相比,Byte Buddy 对默认方法的可调用性提出了较弱的要求。 Byte Buddy 只需要由类型层次结构中最具体的类来实现默认方法的接口。除了 Java 编程语言之外,它不要求此接口是任何超类实现的最具体的接口。最后,如果您不希望有歧义的默认方法定义,您总是可以使用 DefaultMethodCall.unambiguousOnly() 来接收一个实现,该实现在发现歧义的默认方法调用时抛出异常。同样的行为由优先 DefaultMethodCall 显示,其中默认方法调用在非优先接口之间不明确,并且没有发现优先接口来定义具有兼容签名的方法。
调用特定方法
在某些情况下,上述实现不足以实现更多自定义行为。例如,人们可能想要实现一个具有显式行为的自定义类。例如,我们可能希望使用没有具有相同参数的超级构造函数的构造函数来实现以下 Java 类:
public class SampleClass { public SampleClass(int unusedValue) { super(); } } 复制代码之前的 SuperMethodCall 实现不能用于实现此类,因为 Object 类没有定义将 int 作为其参数的构造函数。相反,我们可以显式调用 Object 超级构造函数:
new ByteBuddy() .subclass(Object.class, ConstructorStrategy.Default.NO_CONSTRUCTORS) .defineConstructor(Arrays.<Class<?>>asList(int.class), Visibility.PUBLIC) .intercept(MethodCall.invoke(Object.class.getDeclaredConstructor())) .make() 复制代码
使用上面的代码,我们创建了一个简单的 Object 子类,它定义了一个构造函数,该构造函数接受一个未使用的 int 参数。然后通过对 Object 超级构造函数的显式方法调用来实现后一个构造函数。
MethodCall 实现也可以在传递参数时使用。这些参数要么作为值显式传递,要么作为需要手动设置的实例字段的值或作为给定的参数值传递。此外,该实现允许调用其他实例上的方法,而不是被检测的实例。此外,它允许构造从拦截的方法返回的新实例。 MethodCall 类的文档提供了有关这些功能的详细信息。
访问字段
使用 FieldAccessor,可以实现读取或写入字段值的方法。为了与此实现兼容,方法必须:
有一个类似于 void setBar(Foo f) 的签名来定义一个字段设置器。 setter 通常会访问名为 bar 的字段,因为它在 Java bean 规范中是约定俗成的。在这种情况下,参数类型 Foo 必须是该字段类型的子类型。
有一个类似于 Foo getBar() 的签名来定义一个字段 getter。 setter 通常会访问名为 bar 的字段,因为它在 Java bean 规范中是约定俗成的。为此,该方法的返回类型 Foo 必须是该字段类型的超类型。
创建这样的实现很简单:只需调用 FieldAccessor.ofBeanProperty()。但是,如果您不想从方法名称派生字段名称,您仍然可以使用 FieldAccessor.ofField(String) 显式指定字段名称。使用此方法,唯一的参数定义应访问的字段名称。如果需要,这甚至允许您定义一个新字段,如果这样的字段尚不存在。访问现有字段时,您可以通过调用 in 方法指定定义字段的类型。在 Java 中,在层次结构的多个类中定义一个字段是合法的。在此过程中,类的字段被其子类中的字段定义所掩盖。如果没有字段类的明确位置,Byte Buddy 将通过遍历类层次结构来访问它遇到的第一个字段,从最具体的类开始。
让我们看一下 FieldAccessor 的示例应用程序。对于这个例子,我们假设我们收到了一些我们想要在运行时子类化的 UserType。为此,我们要为每个由接口表示的实例注册一个拦截器。这样,我们就可以根据我们的实际需求提供不同的实现。后一个实现应该可以通过调用相应实例上的 InterceptionAccessor 接口的方法来交换。为了创建这种动态类型的实例,我们进一步不想使用反射,而是调用用作对象工厂的 InstanceCreator 的方法。以下类型类似于此设置:
class UserType { public String doSomething() { return null; } } interface Interceptor { String doSomethingElse(); } interface InterceptionAccessor { Interceptor getInterceptor(); void setInterceptor(Interceptor interceptor); } interface InstanceCreator { Object makeInstance(); } 复制代码我们已经学习了如何使用 MethodDelegation 拦截类的方法。使用后一种实现,我们可以定义对实例字段的委托,并将该字段命名为拦截器。此外,我们正在实现 InterceptionAccessor 接口并拦截该接口的所有方法以实现该字段的访问器。通过定义一个 bean 属性访问器,我们实现了 getInterceptor 的 getter 和 setInterceptor 的 setter:
Class<? extends UserType> dynamicUserType = new ByteBuddy() .subclass(UserType.class) .method(not(isDeclaredBy(Object.class))) .intercept(MethodDelegation.toField("interceptor")) .defineField("interceptor", Interceptor.class, Visibility.PRIVATE) .implement(InterceptionAccessor.class).intercept(FieldAccessor.ofBeanProperty()) .make() .load(getClass().getClassLoader()) .getLoaded(); 复制代码有了新的dynamicUserType,我们就可以实现InstanceCreator接口,成为这个动态类型的工厂。同样,我们使用已知的 MethodDelegation 来调用动态类型的默认构造函数:
InstanceCreator factory = new ByteBuddy() .subclass(InstanceCreator.class) .method(not(isDeclaredBy(Object.class))) .intercept(MethodDelegation.construct(dynamicUserType)) .make() .load(dynamicUserType.getClassLoader()) .getLoaded().newInstance(); 复制代码
请注意,我们需要使用 dynamicUserType 的类加载器来加载工厂。否则,这种类型在加载时工厂将不可见。
有了这两个动态类型,我们终于可以创建动态增强的 UserType 的新实例,并为其实例定义自定义拦截器。让我们通过将一些 HelloWorldInterceptor 应用到一个新创建的实例来结束这个例子。请注意,由于字段访问器接口和工厂,我们现在可以在不使用任何反射的情况下做到这一点。
class HelloWorldInterceptor implements Interceptor { @Override public String doSomethingElse() { return "Hello World!"; } } UserType userType = (UserType) factory.makeInstance(); ((InterceptionAccessor) userType).setInterceptor(new HelloWorldInterceptor()); 复制代码各种各样的
除了我们目前讨论的实现之外,Byte Buddy 还包括其他几个实现:
StubMethod 实现了一个方法来简单地返回方法返回类型的默认值,而无需任何进一步的操作。这样,方法调用可以被静默抑制。例如,这种方法可用于实现模拟类型。任何原始类型的默认值分别为零或零字符。返回引用类型的方法返回 null 作为它们的默认值。
ExceptionMethod 可用于实现仅抛出异常的方法。如前所述,即使方法未声明此异常,也可以从任何方法抛出已检查的异常。
转发实现允许简单地将方法调用转发到与被拦截方法的声明类型相同类型的另一个实例。使用 MethodDelegation 可以获得相同的结果。然而,通过转发应用了一个更简单的委托模型,它可以覆盖不需要目标方法发现的用例。
InvocationHandlerAdapter 允许使用 Java 类库附带的代理类中的现有 InvocationHandlers。
InvokeDynamic 实现允许在运行时使用可从 Java 7 访问的引导方法动态绑定方法。
注释
我们刚刚了解了 Byte Buddy 如何依赖注释来提供其某些功能。到目前为止,Byte Buddy 并不是唯一具有基于注释的 API 的 Java 应用程序。为了将动态创建的类型与此类应用程序集成,Byte Buddy 允许为其创建的类型及其成员定义注释。在研究为动态创建的类型分配注解的细节之前,让我们看一个注解运行时类的例子:
@Retention(RetentionPolicy.RUNTIME) @interface RuntimeDefinition { } class RuntimeDefinitionImpl implements RuntimeDefinition { @Override public Class<? extends Annotation> annotationType() { return RuntimeDefinition.class; } } new ByteBuddy() .subclass(Object.class) .annotateType(new RuntimeDefinitionImpl()) .make(); 复制代码正如 Java 的 @interface 关键字所暗示的那样,注释在内部表示为接口类型。因此,注解可以像普通接口一样由 Java 类实现。实现接口的唯一区别是注解的隐式 annotationType 方法,该方法确定类表示的注解类型。后一种方法通常返回实现的注释类型的类文字。除此之外,任何注解属性都被实现为一个接口方法。但是,请注意,注释方法的实现需要重复注释的默认值。
当一个类应该作为另一个类的子类代理时,为动态创建的类定义注解就显得尤为重要。子类代理通常用于实现横切关注点,其中子类应尽可能透明地模仿原始类。但是,只要通过将注释定义为 @Inherited 来明确要求此行为,则不会为其子类保留类上的注释。使用 Byte Buddy,通过调用 Byte Buddy 的领域特定语言的属性方法,可以轻松创建保留其基类注释的子类代理。这个方法需要一个 TypeAttributeAppender 作为它的参数。类型属性 appender 提供了一种灵活的方式来定义动态创建的类的注解,基于其基类。例如,通过传递一个 TypeAttributeAppender.ForSuperType,一个类的注解被复制到它动态创建的子类中。请注意,注释和类型属性附加器是附加的,并且对于任何类,注释类型都不能被定义多次。
方法和字段注释的定义类似于我们刚刚讨论的类型注释。方法注释可以定义为 Byte Buddy 的领域特定语言中用于实现方法的结论性语句。同样,一个字段可以在其定义之后进行注释。再次,让我们看一个例子:
new ByteBuddy() .subclass(Object.class) .annotateType(new RuntimeDefinitionImpl()) .method(named("toString")) .intercept(SuperMethodCall.INSTANCE) .annotateMethod(new RuntimeDefinitionImpl()) .defineField("foo", Object.class) .annotateField(new RuntimeDefinitionImpl()) 复制代码上面的代码示例覆盖了 toString 方法并使用 RuntimeDefinition 注释覆盖的方法。此外,创建的类型定义了一个字段 foo ,该字段带有相同的注释,并且还在创建的类型本身上定义了后一个注释。
默认情况下,ByteBuddy 配置不会为动态创建的类型或类型成员预定义任何注释。但是,可以通过提供默认的 TypeAttributeAppender、MethodAttributeAppender 或 FieldAttributeAppender 来更改此行为。请注意,此类默认附加程序不是可添加的,而是替换了它们以前的值。
有时,在定义类时不加载注解类型或其任何属性的类型是可取的。为此,可以使用 AnnotationDescription.Builder,它提供了一个流畅的接口来定义注释,而不会触发类加载,但以类型安全为代价。但是,所有注释属性都在运行时进行评估。
默认情况下,Byte Buddy 将注释的任何属性包含到类文件中,包括由默认值隐式指定的默认属性。但是,可以通过向 ByteBuddy 实例提供 AnnotationFilter 来自定义此行为。
类型注释
Byte Buddy 公开和编写类型注释,因为它们是作为 Java 8 的一部分引入的。类型注释可以作为声明的注释被任何 TypeDescription.Generic 实例访问。如果应将类型注释添加到泛型字段或方法的类型,则可以使用 TypeDescription.Generic.Builder 生成带注释的类型。
属性附加器
Java 类文件可以包含任何自定义信息作为所谓的属性。可以使用 Byte Buddy 通过对类型、字段或方法使用 *AttributeAppender 来包含此类属性。然而,属性附加器也可用于根据拦截的类型、字段或方法提供的信息来定义方法。例如,在覆盖子类中的方法时,可以复制被拦截方法的所有注解:
class AnnotatedMethod { @SomeAnnotation void bar() { } } new ByteBuddy() .subclass(AnnotatedMethod.class) .method(named("bar")) .intercept(StubMethod.INSTANCE) .attribute(MethodAttributeAppender.ForInstrumentedMethod.INSTANCE) 复制代码上面的代码覆盖了 AnnotatedMethod 类的 bar 方法,但复制了覆盖方法的所有注释,包括参数或类型的注释。
当一个类被重新定义或重新定位时,相同的规则可能不适用。默认情况下,ByteBuddy 被配置为保留重新定位或重新定义的方法的任何注释,即使该方法如上所述被拦截。但是,可以更改此行为,以便 Byte Buddy 通过将 AnnotationRetention 策略设置为 DISABLED 丢弃任何预先存在的注释。
自定义方法实现
在前面的部分中,我们描述了 Byte Buddy 的标准 API。到目前为止所描述的功能都不需要知识或 Java 字节码的显式表达。但是,如果您需要创建自定义字节码,则可以通过直接访问 ASM 的 API 来实现,ASM 是一个低级字节码库,Byte Buddy 在其上构建。但是,请注意,不同版本的 ASM 与另一个版本不兼容,因此您需要在发布代码时将 Byte Buddy 重新打包到您自己的命名空间中。否则,当另一个依赖项需要基于不同 ASM 版本的不同版本的 Byte Buddy 时,您的应用程序可能会导致与 Byte Buddy 的其他用途不兼容。您可以在首页找到关于维护对 Byte Buddy 的依赖的详细信息。
ASM 库附带了关于 Java 字节码和库使用的优秀文档。因此,如果您想详细了解 Java 字节码和 ASM 的 API,我们希望您参考此文档。相反,我们只简单介绍 JVM 的执行模型和 Byte Buddy 对 ASM API 的适配。
任何 Java 类文件都是由若干段构成的。核心细分市场大致可以分为以下几类:
基础数据:类文件引用类的名称以及其超类的名称及其实现的接口。此外,类文件包含不同的元数据,例如类的 Java 版本号、注释或编译器为创建类而处理的源文件的名称。
常量池:类的常量池是该类的成员或注解所引用的值的集合。在这些值中,常量池存储例如由类源代码中的某些文字表达式创建的原始值和字符串。此外,常量池存储类中使用的所有类型和方法的名称。
字段列表:Java 类文件包含在该类中声明的所有字段的列表。除了字段的类型、名称和修饰符之外,类文件还存储每个字段的注释。
方法列表:与字段列表类似,Java 类文件包含所有声明方法的列表。除了字段之外,非抽象方法还由描述方法主体的字节编码指令数组进行描述。这些指令代表所谓的 Java 字节码。
幸运的是,ASM 库在创建类时完全负责建立适用的常量池。有了这个,唯一重要的元素仍然是方法实现的描述,它由一组执行指令表示,每个指令都编码为一个字节。这些指令由虚拟堆栈机在方法调用时处理。举一个简单的例子,让我们考虑一个计算并返回两个原始整数 10 和 50 之和的方法。这个方法的 Java 字节码如下所示:
LDC 10 // stack contains 10 LDC 50 // stack contains 10, 50 IADD // stack contains 60 IRETURN // stack is empty 复制代码
上述 Java 字节码数组的助记符首先使用 LDC 指令将两个数字压入堆栈。请注意,此执行顺序与 Java 源代码中表示的顺序有何不同,在 Java 源代码中,加法将编写为中缀符号 10 + 50。但是,后一种顺序无法由堆栈机器处理,其中任何指令如 + 只能访问当前在堆栈中找到的最高值。这种加法由 IADD 表示,它消耗两个最上面的堆栈值,它们都期望是原始整数。在此过程中,它将这两个值相加并将结果压回到堆栈顶部。最后,IRETURN 语句消费这个计算结果并从方法中返回它,给我们留下一个空堆栈。
我们已经提到在方法中引用的任何原始值都存储在类的常量池中。对于上述方法中引用的数字 50 和 10 也是如此。常量池中的任何值都被分配了一个长度为两个字节的索引。让我们假设数字 10 和 50 存储在索引 1 和 2 中。 连同上述助记符的字节值,LDC 为 0x12,IADD 为 0x60,IRETURN 为 0xAC,我们现在知道如何将上述方法表示为原始字节指令:
12 00 01 12 00 02 60 AC 复制代码
对于已编译的类,可以在类文件中找到这个确切的字节序列。然而,这个描述还不足以完全定义一个方法的实现。为了加速 Java 应用程序的运行时执行,每个方法都需要通知 Java 虚拟机其执行堆栈所需的大小。对于上面没有分支的方法,这很容易确定,因为我们已经看到堆栈上最多有两个值。然而,对于更复杂的方法,提供这些信息很容易成为一项复杂的任务。更糟糕的是,堆栈值可能有不同的大小。 long 和 double 值都消耗两个槽,而任何其他值都消耗一个。似乎这还不够,Java 虚拟机还需要有关方法主体内所有局部变量大小的信息。方法中的所有此类变量都存储在一个数组中,该数组还包括任何方法参数和非静态方法的 this 引用。同样,long 和 double 值在这个数组中消耗了两个槽。
显然,跟踪所有这些信息会使 Java 字节码的手动组装变得乏味且容易出错,这就是 Byte Buddy 提供简化抽象的原因。在 Byte Buddy 中,任何堆栈指令都包含在 StackManipulation 接口的实现中。堆栈操作的任何实现都将更改给定堆栈的指令和有关该指令大小影响的信息结合在一起。任何数量的此类指令都可以很容易地合并为一条通用指令。为了证明这一点,让我们首先为 IADD 指令实现一个 StackManipulation:
enum IntegerSum implements StackManipulation { INSTANCE; // singleton @Override public boolean isValid() { return true; } @Override public Size apply(MethodVisitor methodVisitor, Implementation.Context implementationContext) { methodVisitor.visitInsn(Opcodes.IADD); return new Size(-1, 0); } } 复制代码从上面的apply方法我们了解到,这个栈操作是通过调用ASM的方法访问者上的相关方法来执行IADD指令的。此外,该方法表示该指令将当前堆栈大小减少一个槽。创建的 Size 实例的第二个参数是 0 表示该指令不需要特定的最小堆栈大小来计算中间结果。此外,任何 StackManipulation 都可以表示为无效。此行为可用于更复杂的堆栈操作,例如可能会破坏类型约束的对象分配。我们将在本节后面查看无效堆栈操作的示例。最后,请注意我们将堆栈操作描述为单例枚举。事实证明,对于 Byte Buddy 的内部实现来说,使用这种不可变的、功能性的堆栈操作描述是一种很好的做法,我们只能建议您遵循相同的方法。
通过将上述 IntegerSum 与预定义的 IntegerConstant 和 MethodReturn 堆栈操作相结合,我们现在可以实现一个方法。在 Byte Buddy 中,方法实现包含在 ByteCodeAppender 中,我们实现如下:
enum SumMethod implements ByteCodeAppender { INSTANCE; // singleton @Override public Size apply(MethodVisitor methodVisitor, Implementation.Context implementationContext, MethodDescription instrumentedMethod) { if (!instrumentedMethod.getReturnType().asErasure().represents(int.class)) { throw new IllegalArgumentException(instrumentedMethod + " must return int"); } StackManipulation.Size operandStackSize = new StackManipulation.Compound( IntegerConstant.forValue(10), IntegerConstant.forValue(50), IntegerSum.INSTANCE, MethodReturn.INTEGER ).apply(methodVisitor, implementationContext); return new Size(operandStackSize.getMaximalSize(), instrumentedMethod.getStackSize()); } } 复制代码同样,自定义 ByteCodeAppender 实现为单例枚举。
在实现所需的方法之前,我们首先验证检测的方法是否真的返回一个原始整数。否则,创建的类将被 JVM 的验证器拒绝。然后我们将这两个数字 10 和 50 加载到执行堆栈中,应用这些值的总和并返回计算结果。通过使用复合堆栈操作包装所有这些指令,我们可以最终检索执行此堆栈操作链所需的聚合堆栈大小。最后,我们返回此方法的总体大小要求。返回的 ByteCodeAppender.Size 的第一个参数反映了我们刚刚提到的 StackManipulation.Size 包含的执行堆栈所需的大小。此外,第二个参数反映了局部变量数组所需的大小,这里只是类似于方法参数所需的大小和可能的 this 引用,因为我们没有定义我们自己的任何局部变量。
通过我们的求和方法的这个实现,我们现在准备为这个方法提供一个自定义的实现,我们可以提供给 Byte Buddy 的领域特定语言:
enum SumImplementation implements Implementation { INSTANCE; // singleton @Override public InstrumentedType prepare(InstrumentedType instrumentedType) { return instrumentedType; } @Override public ByteCodeAppender appender(Target implementationTarget) { return SumMethod.INSTANCE; } } 复制代码Any Implementation 分两个阶段进行查询。首先,实现有机会通过在准备方法中添加额外的字段或方法来更改创建的类。此外,该准备允许实现注册我们在上一节中学到的 TypeInitializer。如果不需要这样的准备,返回作为参数提供的未改变的 InstrumentedType 就足够了。请注意,实现通常不应返回检测类型的单个实例,而应调用检测类型的附加方法,这些方法都以 with 为前缀。在为特定类创建准备好任何实现之后,将调用 appender 方法来检索 ByteCodeAppender。然后,这个 appender 被查询任何被给定实现选择拦截的方法,以及在实现调用准备方法期间注册的任何方法。
请注意,Byte Buddy 在任何类的创建过程中只调用一次每个 implementation 的 prepare 和 appender 方法。无论在类的创建中注册实现多少次,都可以保证这一点。这样,一个实现就可以避免验证一个字段或方法是否已经定义。在此过程中,Byte Buddy 通过 hashCode 和 equals 方法比较实现实例。通常,Byte Buddy 使用的任何类都应该提供这些方法的有意义的实现。枚举带有每个定义的此类实现的事实是使用它们的另一个很好的理由。
有了这一切,让我们看看 SumImplementation 的运行情况:
abstract class SumExample { public abstract int calculate(); } new ByteBuddy() .subclass(SumExample.class) .method(named("calculate")) .intercept(SumImplementation.INSTANCE) .make() 复制代码恭喜!您只是扩展了 Byte Buddy 来实现一个自定义方法,该方法计算并返回 10 和 50 的总和。当然,这个示例实现并没有太大的实际用途。但是,可以在此基础架构之上轻松实现更复杂的实现。毕竟,如果你觉得你创造了一些方便的东西,请考虑贡献你的实现。我们期待您的来信!
在我们继续定制 Byte Buddy 的其他一些组件之前,我们应该简要讨论一下跳转指令的使用和所谓的 Java 堆栈帧的问题。从 Java 6 开始,用于实现 if 或 while 语句等任何跳转指令都需要一些附加信息,以加速 JVM 的验证过程。此附加信息称为堆栈映射帧。堆栈映射帧包含有关在跳转指令的任何目标的执行堆栈上找到的所有值的信息。通过提供这些信息,JVM 的验证器可以节省一些现在留给我们的工作。对于更复杂的跳转指令,提供正确的堆栈映射框架是一项相当困难的任务,许多代码生成框架在始终创建正确的堆栈映射框架方面遇到了很多麻烦。那么我们如何处理这个问题呢?事实上,我们根本就没有。 Byte Buddy 的理念是,代码生成应该只用作编译时未知的类型层次结构和需要注入这些类型的自定义代码之间的粘合剂。因此,生成的实际代码应尽可能受到限制。在可能的情况下,条件语句应该在您选择的 JVM 语言中实现和编译,然后通过使用简约的实现绑定到给定的方法。这种方法的一个很好的副作用是 Byte Buddy 的用户可以使用普通的 Java 代码并使用他们习惯的工具,如调试器或 IDE 代码导航器。对于没有源代码表示的生成代码,这一切都是不可能的。但是,如果您确实需要使用跳转指令创建字节码,请确保使用 ASM 添加正确的堆栈映射帧,因为 Byte Buddy 不会自动为您包含它们。
创建自定义分配器
在上一节中,我们讨论了 Byte Buddy 的内置实现依赖于赋值器来为变量赋值。在此过程中,Assigner 能够通过发出适当的 StackManipulation 将一个值转换为另一个值。这样做,Byte Buddy 的内置分配器提供例如原始值及其包装器类型的自动装箱。在最简单的情况下,一个值可以按原样分配给一个变量。然而,在某些情况下,分配可能根本不可能,这可以通过从分配器返回无效的 StackManipulation 来表达。 Byte Buddy 的 IllegalStackManipulation 类提供了无效赋值的规范实现。
为了演示自定义分配器的使用,我们现在将实现一个分配器,该分配器仅通过对接收到的任何值调用 toString 方法来将值分配给字符串类型的变量:
enum ToStringAssigner implements Assigner { INSTANCE; // singleton @Override public StackManipulation assign(TypeDescription.Generic source, TypeDescription.Generic target, Assigner.Typing typing) { if (!source.isPrimitive() && target.represents(String.class)) { MethodDescription toStringMethod = new TypeDescription.ForLoadedType(Object.class) .getDeclaredMethods() .filter(named("toString")) .getOnly(); return MethodInvocation.invoke(toStringMethod).virtual(sourceType); } else { return StackManipulation.Illegal.INSTANCE; } } } 复制代码上面的实现首先验证输入值不是原始类型,并且目标变量类型是字符串类型。如果不满足这些条件,则分配器会发出 IllegalStackManipulation 以使尝试的分配无效。否则,我们通过名称标识 Object 类型的 toString 方法。然后我们使用 Byte Buddy 的 MethodInvocation 来创建一个 StackManipulation,它在源类型上虚拟地调用这个方法。最后,我们可以将此自定义分配器与例如 Byte Buddy 的 FixedValue 实现集成,如下所示:
new ByteBuddy() .subclass(Object.class) .method(named("toString")) .intercept(FixedValue.value(42) .withAssigner(new PrimitiveTypeAwareAssigner(ToStringAssigner.INSTANCE), Assigner.Typing.STATIC)) .make() 复制代码当对上述类型的实例调用 toString 方法时,它将返回字符串值 42。这只能通过使用我们的自定义分配器来实现,该分配器通过调用 toString 方法将 Integer 类型转换为 String。请注意,我们还使用内置的 PrimitiveTypeAwareAssigner 包装了自定义分配器,在将此包装的原始值的分配委托给其内部分配器之前,它执行提供的原始 int 为其包装类型的自动装箱。其他内置分配器是 VoidAwareAssigner 和 ReferenceTypeAwareAssigner。永远记住为您的自定义分配器实现有意义的 hashCode 和 equals 方法,因为这些方法通常是从使用给定分配器的实现中的对应方法调用的。同样,通过将分配器实现为单例枚举,我们可以避免手动执行此操作。
创建自定义参数绑定器
我们在上一节中已经提到,可以扩展 MethodDelegation 实现来处理用户定义的注释。为此,我们需要提供一个自定义的 ParameterBinder,它知道如何处理给定的注释。例如,我们想定义一个注解,目的是简单地将一个固定的字符串注入到带注释的参数中。首先,我们定义这样一个StringValue注解:
@Retention(RetentionPolicy.RUNTIME) @interface StringValue { String value(); } 复制代码我们需要通过设置适当的 RuntimePolicy 来确保注释在运行时可见。否则,注释在运行时不会保留,Byte Buddy 没有机会发现它。这样做,上面的 value 属性包含作为值分配给带注释的参数的字符串。
使用我们的自定义注解,我们需要创建一个相应的 ParameterBinder,它能够创建一个 StackManipulation 来表达此参数的绑定。每次调用此参数绑定器时,MethodDelegation 在参数上发现其相应的注释。为我们的示例注释实现自定义参数绑定器很简单:
enum StringValueBinder implements TargetMethodAnnotationDrivenBinder.ParameterBinder<StringValue> { INSTANCE; // singleton @Override public Class<StringValue> getHandledType() { return StringValue.class; } @Override public MethodDelegationBinder.ParameterBinding<?> bind(AnnotationDescription.Loaded<StringValue> annotation, MethodDescription source, ParameterDescription target, Implementation.Target implementationTarget, Assigner assigner, Assigner.Typing typing) { if (!target.getType().asErasure().represents(String.class)) { throw new IllegalStateException(target + " makes illegal use of @StringValue"); } StackManipulation constant = new TextConstant(annotation.loadSilent().value()); return new MethodDelegationBinder.ParameterBinding.Anonymous(constant); } } 复制代码最初,参数绑定器确保目标参数实际上是字符串类型。如果不是这种情况,我们将抛出异常以通知注释的用户他非法放置此注释。否则,我们只需创建一个 TextConstant,它表示将常量池字符串加载到执行堆栈上。然后将此 StackManipulation 包装为匿名 ParameterBinding,最终从该方法返回。或者,您可以提供 Unique 或 Illegal 参数绑定。唯一绑定由允许从 AmbiguityResolver 检索此绑定的任何对象标识。在后面的步骤中,这样的解析器能够查找参数绑定是否使用某个唯一标识符注册,然后可以确定此绑定是否优于另一个成功绑定的方法。使用非法绑定,可以指示 Byte Buddy 一对特定的源方法和目标方法不兼容且不能绑定在一起。
这已经是将自定义注释与 MethodDelegation 实现一起使用所需的所有信息。收到 ParameterBinding 后,它会确保其值绑定到正确的参数,否则将丢弃当前的源和目标方法对,因为它是不可绑定的。此外,它将允许 AmbiguityResolvers 查找唯一绑定。最后,让我们将这个自定义注释付诸实践:
class ToStringInterceptor { public static String makeString(@StringValue("Hello!") String value) { return value; } } new ByteBuddy() .subclass(Object.class) .method(named("toString")) .intercept(MethodDelegation.withDefaultConfiguration() .withBinders(StringValueBinder.INSTANCE) .to(ToStringInterceptor.class)) .make() 复制代码请注意,通过将 StringValueBinder 指定为唯一的参数绑定器,我们替换了所有默认值。或者,我们可以将参数绑定器附加到已经注册的那些。在 ToStringInterceptor 中只有一个可能的目标方法时,动态类的拦截 toString 方法绑定到后一个方法的调用。调用目标方法时,Byte Buddy 将注释的字符串值分配为目标方法的唯一参数。
作者:anthem37
链接:https://juejin.cn/post/7031748974285422629