
HTTP 499 问题处理方法合集
前言
在这篇文章中,我总结了最近处理的日常业务中的 499 问题,其中详细描述出现 499 的原因、以及定位过程,希望对大家有所帮助。
HTTP 499 状态码
nginx 中的 src/http/ngx_http_special_response.c 文件中对 499 状态码进行了定义:
ngx_string(ngx_http_error_494_page), /* 494, request header too large */ ngx_string(ngx_http_error_495_page), /* 495, https certificate error */ ngx_string(ngx_http_error_496_page), /* 496, https no certificate */ ngx_string(ngx_http_error_497_page), /* 497, http to https */ ngx_string(ngx_http_error_404_page), /* 498, canceled */ ngx_null_string, /* 499, client has closed connection */ 复制代码
从注释上,我们可以看到 499 表示客户端主动断开连接。
表面上 499 是客户端主动断开,然而在实际业务开发中,当出现 HTTP 499 状态码时,大部分都是由于服务端请求时间过长,导致客户端等的“不耐烦”了,因此断开了连接。
下面,来说一下,我在日常开发中遇到的 4 中 499 问题,以及相应的问题定位处理方法。
4 种 HTTP 499 问题
1、服务端接口请求超时
在客户端请求服务端接口时,有些接口请求确实很慢。我来随便举个例子:
select * from test where test_id in (2,4,6,8,10,12,14,16); 复制代码
比如我们有一张 test 表,表中有 500 万条数据,我们查询了上述的一条 where in SQL,而 test_id 字段并没有索引,导致进行了全表扫描。这条 SQL 就很慢,请求个几秒钟都是很正常的。
如果客户端设置了超时时间,到了超时时间就自动断开,就会导致 499 问题,如果客户端没有设置超时时间,比如这条 SQL 请求了 5 秒钟,而 php-fpm 的超时时间为 3 秒,就会导致 502 问题。
解决这种问题很简单,找到对应的慢请求,优化即可,一般情况下都是慢 SQL,比如上面的例子,字段没有索引,加个索引就好了。
当然也存在有索引不走索引的情况,比如我之前遇到的问题,MYSQL 选错索引问题分析,就是即使有索引但是还是没走索引的问题。
总结
这种情况呢,就是接口是真的慢,不是偶然现象,是什么时候请求都慢,这个也最好解决,优化接口即可。
2、nginx 导致断开连接
还有一种情况是 nginx 导致的 499 问题。
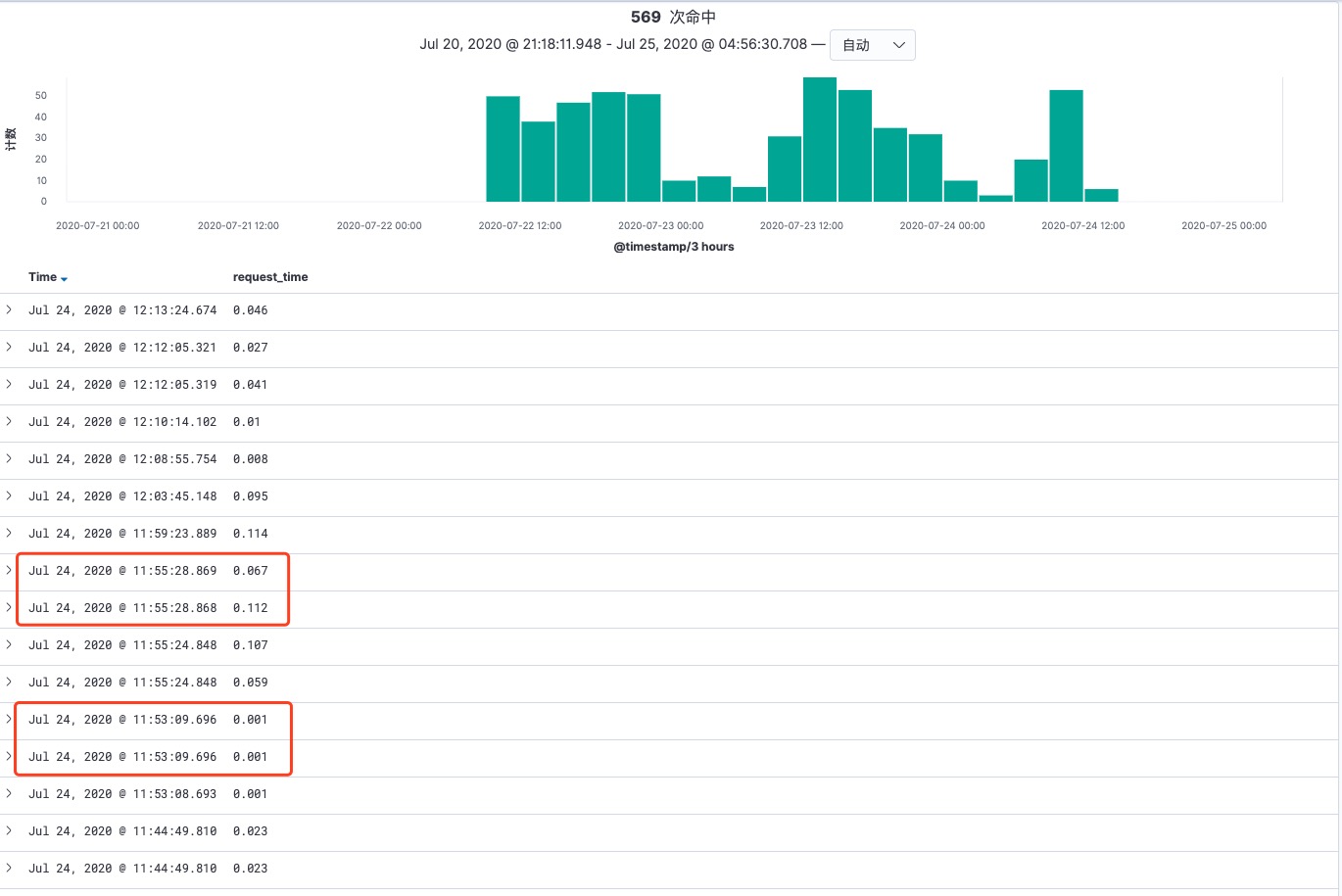
从上图我们可以发现,request_time 非常小,不可能是请求接口超时,那是什么原因导致的这个问题呢?
其实从图中有些信息还没有展示出来,因为涉及到公司的具体接口请求,我在这里描述一下现象:图中请求时间非常接近的两个请求,其实请求参数一模一样。
解决方案
通过谷歌发现,有同学遇到过这种情况,就是连续两次过快的 post 请求就会出现 499 的情况,是 nginx 认为这是不安全的连接,主动断开了客户端的连接。
解决方案是在 nginx 配置:
proxy_ignore_client_abort on; 复制代码
这个参数的意思是 proxy 忽略客户端的中断,一直等待着代理服务器的返回,如果没有执行错误,则记录的日志是 200 日志,如果执行超时,记录的日志是 504 日志。
将此参数设置为 on 之后,线上观察一段时间后,发现基本没有 499 的问题了。
注意事项
该配置只对代理服务器起作用,比如有有两台 nginx 服务器,第一台服务器反向代理到第二台 nginx 服务器,第二台 nginx 服务器指向 PHP 服务,那么该参数只有配置在第一台 nginx 服务器上才会生效,在第二台 nginx 服务器上配置不会生效。
配置该参数后,当客户端断开连接之后,服务器仍然会继续执行,存在着拖垮服务器的风险。所以线上根据自己的情况合理使用。
3、固定时间出现 499 问题
还有一种情况是固定时间出现 499 问题。
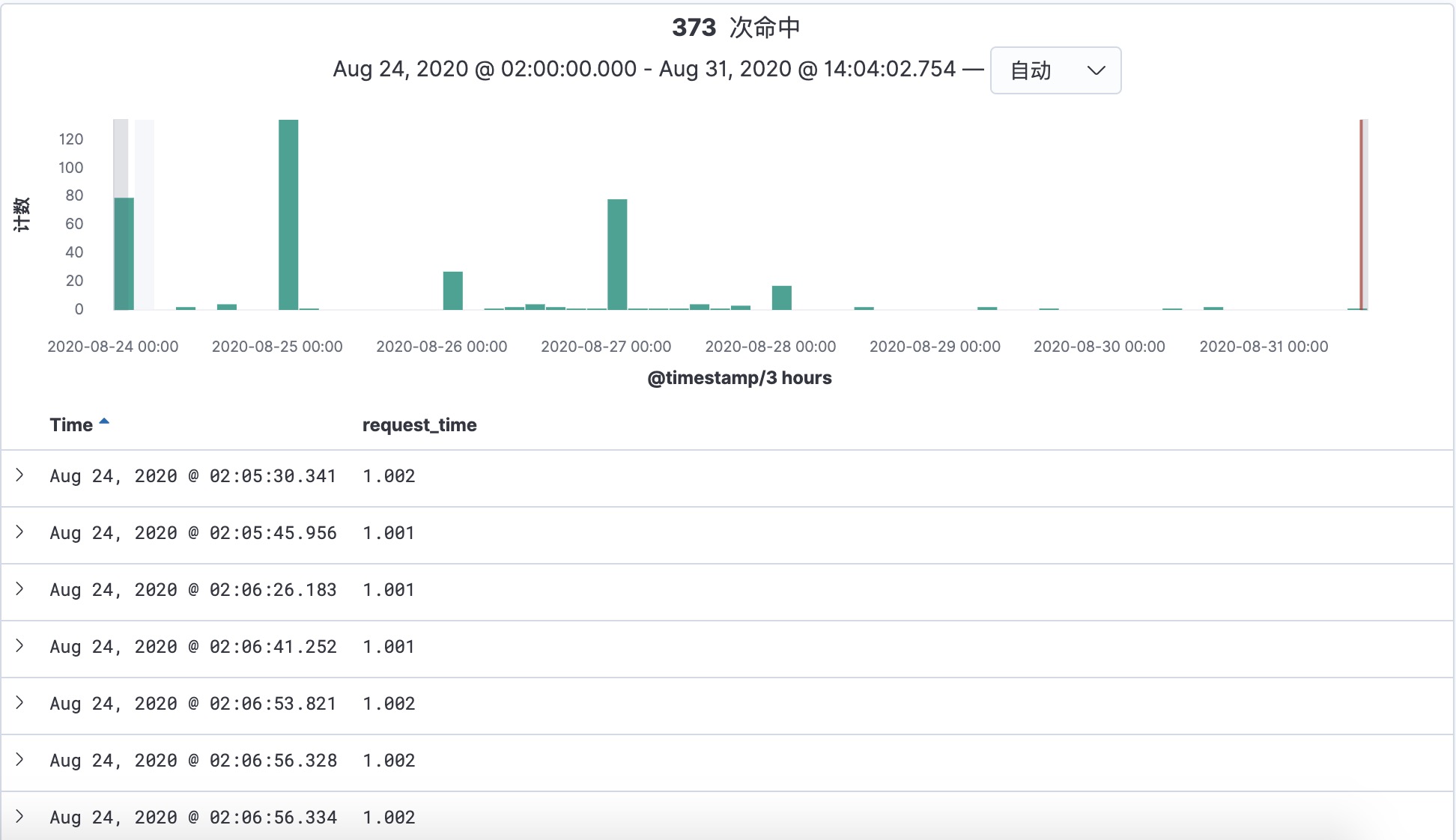
可以看到,上述出现 499 的情况都比较固定,都是在凌晨 2 点之后的十分钟内。
这个时候我们一般快速想到的是是不是有什么定时任务占用资源了,事实上确实如此,不过定位到这个问题却不太容易,下面说一下我是怎样定位这个问题的。
定位步骤
crontab 脚本:首先我想到的是凌晨两点有定时任务脚本,占用了资源。我查看了报错的机器上面的所有 crontab 脚本,发现只有一个是在凌晨两点附近的脚本,我执行了一下,发现非常快,并不会执行特别长时间、占用资源、进而影响正常业务。
机器:接着我怀疑出问题的这几台机器有问题,然后我查看了机器的监控图表(使用的是 falcon),发现凌晨两点并没有什么异常情况。(其实这个也可以推断出来,该服务出现 499 在多台机器上,不可能所有机器都有问题,而且这台机器上还部署着其他项目,其他项目也没有问题,说明不太可能是这台机器有问题。)
数据库:既然是这个服务有问题,我又查看了这个服务连接的主要数据库的监控图表(同样是 falcon),也没有发现什么问题。(其实是有问题的,不过我没有察觉)
nginx:既然上述都没有问题,是不是上层的 nginx 有什么问题。因为
upstream_response_time根本没有值,有可能是该请求根本没有到后端的 PHP 服务,是不是凌晨两点的时候 nginx 有问题。最后发现我其实理解错了,同样涉及上述参数proxy_ignore_client_abort,如果该参数没有设置为on的话,到服务端的请求不会继续执行,upstream_response_time记录的就是-,这个是没问题的。说明 nginx 没问题。异常请求:那么有没有可能是凌晨两点的时候有一波异常请求。该请求为 post 请求,正好 nginx 开启了 post 日志,通过 nginx 记录的请求参数,重新拼装了一下进行请求,发现没有问题。说明和请求参数无关。
数据库:
到这里基本上就能想到的方案基本上都想到了。只能再找找这些请求都有什么共同点吧。
发现这些请求都请求了一个数据库,然后我找了一个请求量最大的接口,打印了数据库请求的执行时间,发现一个简单的接口竟然要执行 2 秒,而且一晚上竟然有十几个超过 2 秒的请求。而我们的超时时间是 1 秒,所以会导致 499 问题。
这里无论是不是导致 499 的原因,都存在问题,需要进行处理,然后我又重新看了一下 falcon 监控,发现凌晨两点的时候有一台机器的 IO 和 CPU 异常。我登录了这台机器查看了 error 日志。
error.log:
在
error.log中我发现了 499 请求接口的 SQL 语句,发现错误信息如下mycat Waiting for query cache lock。从这条日志我们发现这条 SQL 被锁住了,而且等待的是
query cache lock,该锁是一个全局锁,这里我们不过多介绍。query cache在 MYSQL 8.0 中已经不建议使用了,因为如果表只要更新的话,就会清空query cache,对于频繁更新的表来说,没有太大用处,如果数据量少、更新不频繁的表,直接查库就可以,也没什么意义。而且如果开启query cache,一个查询请求过来,就得先去query cache中寻找,找不到的话,去数据库中查找,查找完了再把数据放到query cache中。我查看了一下该数据库,果然开启着
query cache,我以为是该原因导致的,只要关了就可以,然后又查看了一下其他数据库,发现也开启着query cache,这下可以证明query cache不是导致该问题的原因。顺便说一下,查看query cache是否开启的命令为show variables like '%query_cache%';。query_cache_type值为ON则开启,值为OFF则关闭。经过了一堆乱七八糟的试验后,最终将重点放在什么占用了查询缓存上。翻看错误日志,发现有如下一条 SQL(已处理):
select A,B,C from test where id > 1 and id < 2000000。这条 SQL 查询了 200 万条数据,再把这些数据放入query cache中,肯定会占用query cache了。slow.log:
在
error.log中无法发现该条 SQL 的来源,应该不是业务的 SQL,业务不会请求这样的 SQL,通过slow.log中查询 200 万的 SQL 的请求 IP 发现,该请求来源于 Hadoop 集群机器,该机器中有同步线上数据到 HIVE 的脚本,发现该脚本配置的数据库的 IP 即是出问题的 IP。然后修改了数据库配置,将 IP 换成了一个非线上使用的从库的 IP,观察了几天,即上图中后面三天,明显发现 499 情况变少了。
总结
该问题定位起来非常难,花了好长时间,基本上把自己能够想到的情况都一一试验了一下,如果 MYSQL 没有问题的话,可能还会继续往机器层面去定位问题,在这里主要是给大家一些思路借鉴一下。
4、偶尔出现一下 499 问题
我们平时也会看到一两个 499 的情况,但是再重新执行一下该请求,响应速度非常快,根本无法复现,这种偶尔出现的情况,我们一般可以忽略。这里呢,我和大家简单说一下可能导致该问题的原因。
MYSQL 会有将脏页数据刷到磁盘的操作,这个我们具体我们会有一片单独的文章介绍。在 MYSQL 执行刷脏页的时候,会占用系统资源,这个时候,我们的查询请求就有可能比平时慢了。
而且,MYSQL 还有一个机制,可能让你的查询更慢,就是在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个”邻居“也带着一起刷掉;而且这个把”邻居“拖下水的逻辑还会继续蔓延,也就是对于每个邻居数据页,如果跟它相邻的数据页也还是脏页的话,也会放到一起刷。
找”邻居“这个优化机制在机械硬盘时代是很有意义的,减少了寻道时间,可以减少很多随机 IO,机械硬盘的随机 IOPS 一般只有几百,相同的逻辑操作减少随机 IO 就意味着系统性能的大幅度提升。但是现在 IOPS 已经不是瓶颈,如果“只刷自己”,就能更快的执行完必要的刷脏页操作,减少 SQL 响应时间。
有趣的是,这个机制在 MYSQL 8.0 同样被禁止了,该功能由 innodb_flush_neighbors 参数控制,1 表示有连刷机制,0 表示只刷自己。MYSQL 8.0 innodb_flush_neighbors 默认为 0。
我们来看一下我们的线上配置:
mysql> show variables like "%innodb_flush_neighbors%"; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_flush_neighbors | 1 | +------------------------+-------+ 1 row in set (0.00 sec) 复制代码
很不巧,我们线上是开启的,那么就很有可能突然一个请求 499 啦。
总结
上面我们介绍了在日常业务开发中,会出现 499 的 4 中情况以及定位问题、解决问题的方法,希望能给大家提供一些帮助。
作者:开坦克的贝吉塔
链接:https://juejin.cn/post/6867050579139493896