
TensorFlow神经网络构造线性回归模型示例教程
这篇文章主要为大家介绍了TensorFlow构造线性回归模型示例教程,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步
先制作一些数据:
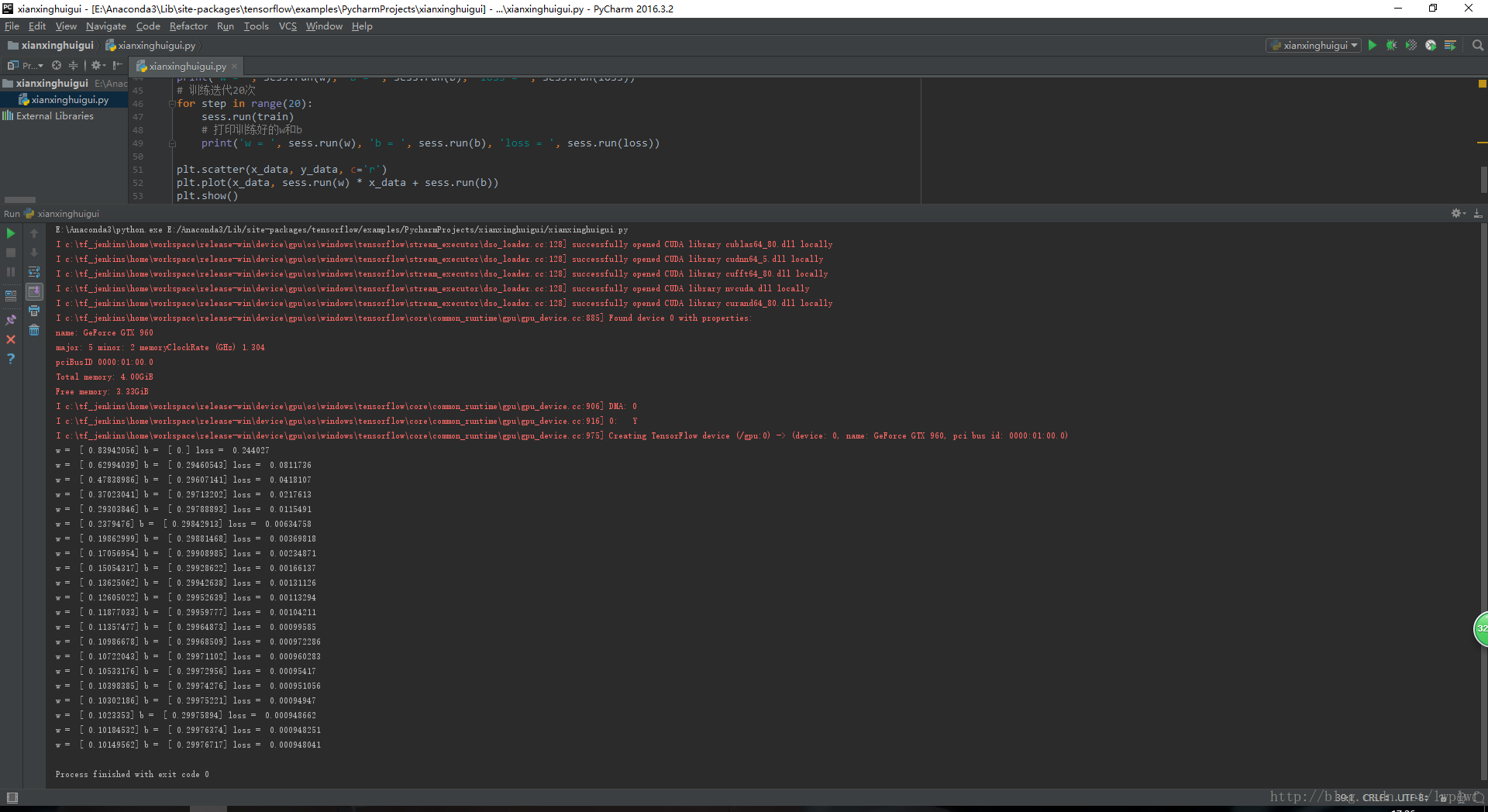
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | import numpy as npimport tensorflow as tfimport matplotlib.pyplot as plt# 随机生成1000个点,围绕在y=0.1x+0.3的直线周围num_points = 1000vectors_set = []for i in range(num_points): x1 = np.random.normal(0.0, 0.55) # np.random.normal(mean,stdev,size)给出均值为mean,标准差为stdev的高斯随机数(场),当size赋值时,如:size=100,表示返回100个高斯随机数。 y1 = x1 * 0.1 + 0.3 + np.random.normal(0.0, 0.03) # 后面加的高斯分布为人为噪声 vectors_set.append([x1, y1])# 生成一些样本x_data = [v[0] for v in vectors_set]y_data = [v[1] for v in vectors_set]plt.scatter(x_data, y_data, c='r')plt.show()# 构造1维的w矩阵,取值是随机初始化权重参数为[-1, 1]之间的随机数w = tf.Variable(tf.random_uniform([1], -1.0, 1.0), name='w')# 构造1维的b矩阵,初始化为0b = tf.Variable(tf.zeros([1]), name='b')# 建立回归公式,经过计算得出估计值yy = w * x_data +b# 定义loss函数,估计值y和实际值y_data之间的均方误差作为损失loss = tf.reduce_mean(tf.square(y - y_data), name='loss')# 采用梯度下降法来优化参数,学习率为0.5optimizer = tf.train.GradientDescentOptimizer(0.5)# train相当于一个优化器,训练的过程就是最小化losstrain = optimizer.minimize(loss, name='train')sess = tf.Session()# 全局变量的初始化init = tf.global_variables_initializer()sess.run(init)# 打印初始化的w和bprint('w = ', sess.run(w), 'b = ', sess.run(b), 'loss = ', sess.run(loss))# 训练迭代20次for step in range(20): sess.run(train) # 打印训练好的w和b print('w = ', sess.run(w), 'b = ', sess.run(b), 'loss = ', sess.run(loss)) |
代码运行一下,下面这个图就是上面代码刚刚构造的数据点:
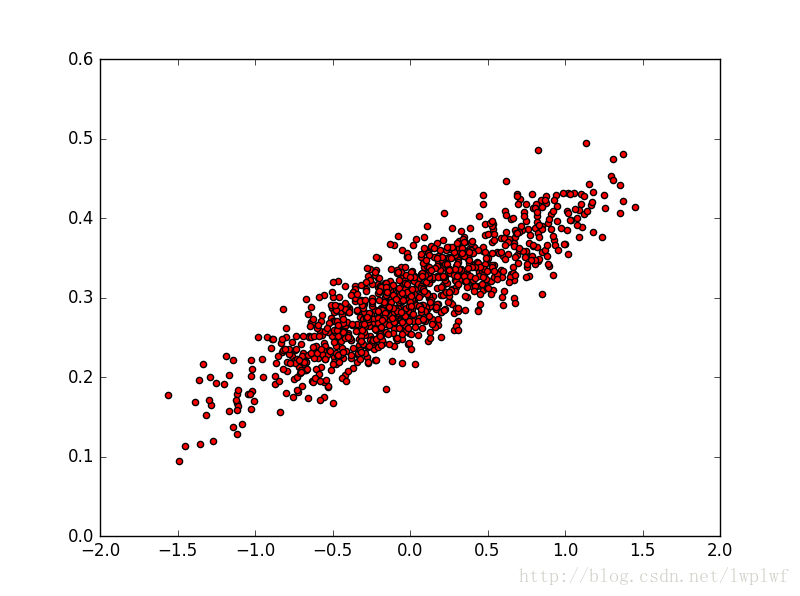
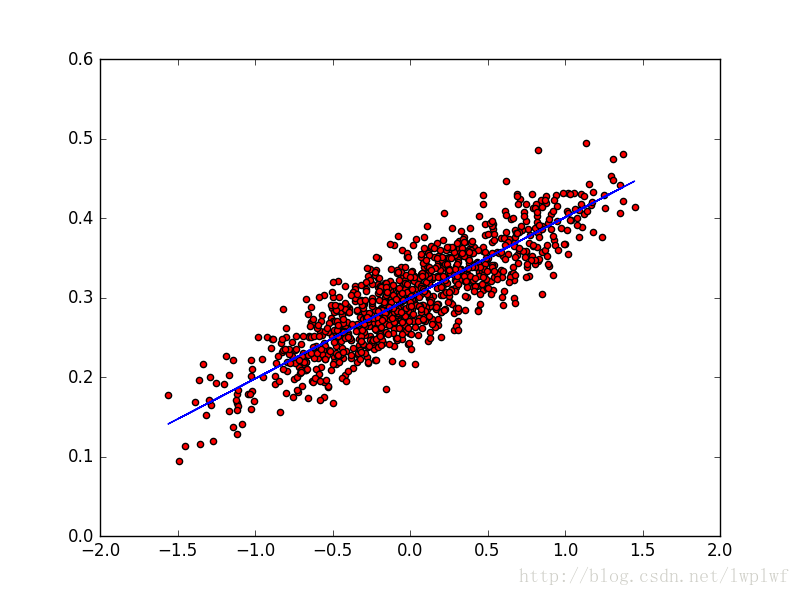
有了数据之后,接下来构造线性回归模型,去学习出来这个数据符合什么样的w和b,训练完后看下得到的w和b是不是接近构造数据时的w和b,最后一次结果是w = [ 0.10149562] b = [ 0.29976717] loss = 0.000948041的,也就是这个线性回归模型学习到了数据的分布规则。也可以看出随着训练次数的迭代,loss值也越来越小,也就是模型越来越好,将训练出来的w和b构造成图中蓝色的线,这条线就是当前最能拟合数据的直线了。运行结果如图所示:

以上就是TensorFlow构造线性回归模型示例教程的详细内容