
GraphQL与REST API - 后端API开发应使用哪一种?
REST和GraphQL都是开发后端API的标准方式。但在过去的十年中,REST APIs作为开发后端API的一种选择占据了主导地位。而且许多公司和开发人员在他们的项目中积极使用它。
,但REST有一些局限性,还有另一种可供选择的方式 - GraphQL。GraphQL是在大型代码库中开发API的一个伟大选择。
什么是GraphQL?
GraphQL 是由Facebook在2012年开发的,供内部使用,并在2015年公开了。它是一种用于API的查询语言,也是用你的现有数据完成这些查询的运行时间。许多公司在生产中使用它。
官方网站对GraphQL是这样介绍的。
GraphQL为你的API中的数据提供了一个完整的、可理解的描述,使客户有能力准确地要求他们所需要的东西,而不是更多,使API更容易随着时间的推移而发展,并使强大的开发者工具成为可能。
我们将在这篇博客中看到这一切是如何运作的。
REST API的问题
查询多个端点
过度获取
获取不足和n+1请求问题
速度不快,无法应对不断变化的客户终端需求
后台控制器和前端视图之间的高耦合度
那么,这些问题是什么,GraphQL是如何解决这些问题的?好吧,我们将在未来了解更多。但首先我们需要确保你对GraphQL的基本概念感到满意,比如类型系统、模式、查询、突变等等。
现在我们来看看一些例子,以便更好地理解使用REST API的缺点。
超取
让我们假设,我们需要在用户界面中显示这个用户卡。
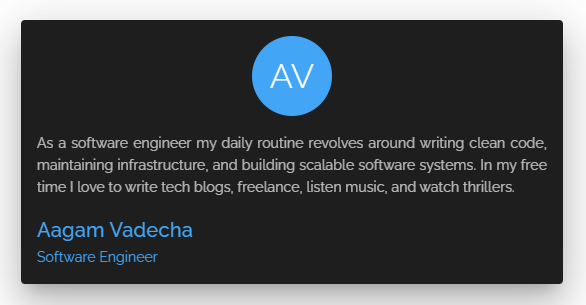
使用REST,请求将是一个GET ,在 /users/1.
这里的问题是,服务器返回一个固定的数据结构,就像这样。
{ "_id": "1", "name": "Aagam Vadecha", "username": "aagam", "email": "testemail@gmail.com", "currentJobTitle": "Software Engineer", "phone": "9876543210", "intro": "As a software engineer my daily routine revolves around writing cleancode, maintaining infrastructure, and building scalable softwaresystems. In my free time I love to write tech blogs, freelance, listenmusic, and watch thrillers.", "website": "https://www.aagam.tech", "gender": "MALE", "city": "Surat", "state": "Gujarat", "country": "India", "display_picture": "8ba58af0-1212-4938-8b4a-t3m9c4371952", "phone_verified": true, "email_verified": true, "_created_at": "2021-03-08T14:13:41Z", "_updated_at": "2021-03-08T14:13:41Z", "_deleted": false } 复制代码服务器返回了额外的数据(除了姓名、介绍和工作职位),这些数据在客户端建立卡片时是不需要的--但响应中仍然有这些数据。这就是所谓的overfetching。
overfetching在每个请求中带来了客户端不需要的额外数据。而这增加了有效载荷的大小,最终对查询的整体响应时间产生了影响。
更糟糕的是,当一个查询从多个表中获取数据时,情况就会升级,尽管客户端当时并不需要这些数据。因此,如果我们可以避免,我们一定要避免
有了GraphQL,请求体中的查询会看起来像这样。

它将只返回客户端所需要的name,intro, 和currentJobTitle ,所以过度获取的问题就解决了。
取值不足和n+1请求问题
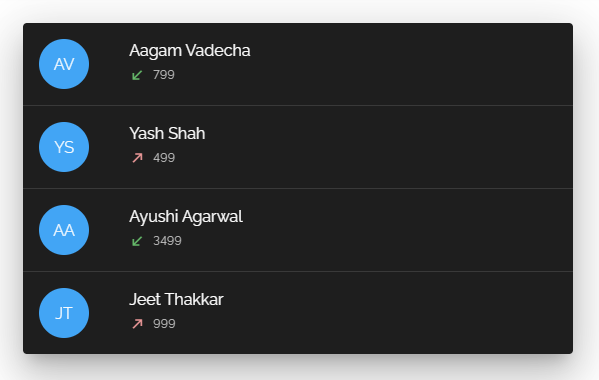
现在让我们假设这个UserList需要在用户界面中显示。

通过REST,考虑到 "experience "是一个有user_id外键的表,有三种可能的选择
一个是在GET /users请求中从所有外键链接的表中发送一些精确的固定数据结构到用户表中,许多框架提供了这个选项。
{ "_id": "1", "name": "Aagam Vadecha", "username": "aagam", "email": "testemail@gmail.com", "currentJobTitle": "Software Engineer", "phone": "9876543210", "intro": "As a software engineer my daily routine revolves around writing cleancode, maintaining infrastructure, and building scalable softwaresystems. In my free time I love to write tech blogs, freelance, listenmusic, and watch thrillers.", "website": "https://www.aagam.tech", "gender": "MALE", "city": "Surat", "state": "Gujarat", "country": "India", "display_picture": "8ba58af0-1212-4938-8b4a-t3m9c4371952", "phone_verified": true, "email_verified": true, "_created_at": "2021-03-08T14:13:41Z", "_updated_at": "2021-03-08T14:13:41Z", "_deleted": false, "experience": [ { "organizationName": "Bharat Tech Labs", "jobTitle": "Software Engineer", "totalDuration": "1 Year" } ], "address": [ { "street": "Kulas Light", "suite": "Apt. 556", "city": "Gwenborough", "zipcode": "929983874", "geo": { "lat": "-37,3159", "lng": "81.1496" } } ] } 复制代码但是这种方法会产生昂贵的查询,也会过度获取所有其他的/users请求,并且最终会从所有的外键表(地址、经验)带回大量的数据,而这在大多数情况下是不需要的。
例如,你想在前端的其他地方获得用户数据,你只需要显示用户的网站,所以你做一个GET user/1请求。但是它从经验表以及地址表中超取数据,而你根本不需要这些数据。
第二个选择是,客户端可以像这样多次前往服务器。
GET /users GET users/1/experience 复制代码
这是一个欠取的例子,因为一个端点没有足够的数据。但多次网络调用会减慢进程,影响用户体验。 :(
另外,在这个列表的特定情况下,获取不足升级了,我们遇到了n+1的请求问题。
你需要进行一次API调用来获取所有的用户,然后为每个用户进行单独的API调用来获取他们的体验,类似这样的情况。
GET /users GET /users/1/experience GET /users/2/experience ... GET /users/n/experience. 复制代码
这就是所谓的n+1请求问题。为了解决这个问题,我们一般做的是第三种方案,我们现在就来讨论。
另一个选择是在服务器上做一个自定义的控制器,返回符合客户在该时间点要求的数据结构。
GET /user-experience 复制代码
这就是现实世界中主要的REST API案例中的做法。
另一方面,一个简单的GraphQL请求,在服务器端不需要任何开发就能无缝工作,它看起来像这样。

没有超取,没有欠取,也没有服务器上的开发。这简直太棒了
前端视图和后端API之间的紧密耦合
好吧,你可能会争辩说,你可以只使用REST,用一次初始开发的努力来制作服务器控制器,然后就很高兴了--对吗?
但是,使用自定义控制器会有一个很大的缺点。
我们已经与前端视图和后端控制器形成了紧密的耦合,所以总体来说,它需要更多的努力来应对客户端的变化。它也给了我们更少的灵活性。
作为软件工程师,我们知道需求的变化有多频繁。此时的自定义控制器GET /user-experience是根据前端视图想要显示的内容(用户名和当前角色)来返回数据。因此,当需求发生变化时,我们需要重构客户端和服务器。
例如,在相当长的时间后,需求发生变化,UI需要显示用户的最后交易信息,而不是体验数据。
通过Rest,我们需要在前端层做相关的改变。此外,为了从后端返回交易数据而不是体验数据,自定义控制器要么需要重构(数据发送、路由等),要么我们需要制作一个新的控制器,以防我们想保留旧的控制器。
所以基本上,客户需求的变化极大地影响了服务器要返回的内容--这意味着我们在前端和后端之间有紧密的耦合性
最好不要在服务器上做任何改变,而只是在前端。
有了GraphQL,我们就不需要在服务器端做任何改变。前端查询的变化将是最小的,就像这样。

没有服务器API的重构,部署,测试 - 这意味着节省了时间和精力
结论
我希望你能从这篇文章中看到,GraphQL在很多方面都比REST有很多优势。
最初设置GraphQL可能需要更多的时间,但有许多支架可以使这项工作更容易。即使在开始时需要更多的时间,它也会给你带来长期的优势,是完全值得的。
作者:迪鲁宾
链接:https://juejin.cn/post/7023214501499502606