
HttpRunner3.X - 全面讲解如何落地项目实战
一、前言
接触httprunner框架有一段时间了,也一直探索如何更好的落地到项目上,本篇主要讲述如何应用到实际的项目中,达到提升测试效率的目的。
1、项目难题
这个月开始忙起来了,接了个大项目,苦不堪言,以下3个问题应该大部分测试人员都能感同身受,并且也是经常会遇到的问题
测试时间被压缩
测试资源被砍
业务流程长
2、解决方案
针对前面2点,除了猛加班,还能有更好的解决方案吗?只要你够肝就能完美应对前面2点问题
针对第3点,只能英勇献身,主动写脚本帮助团队造数据,以前是用jmeter做接口自动化,但在接触了httprunner后,发现该测试框架比jmeter方便很多,因为它有.har直接转换成用例的功能,所以就采用了httprunner框架。
二、设计自动化测试用例结构
1、项目系统流程图
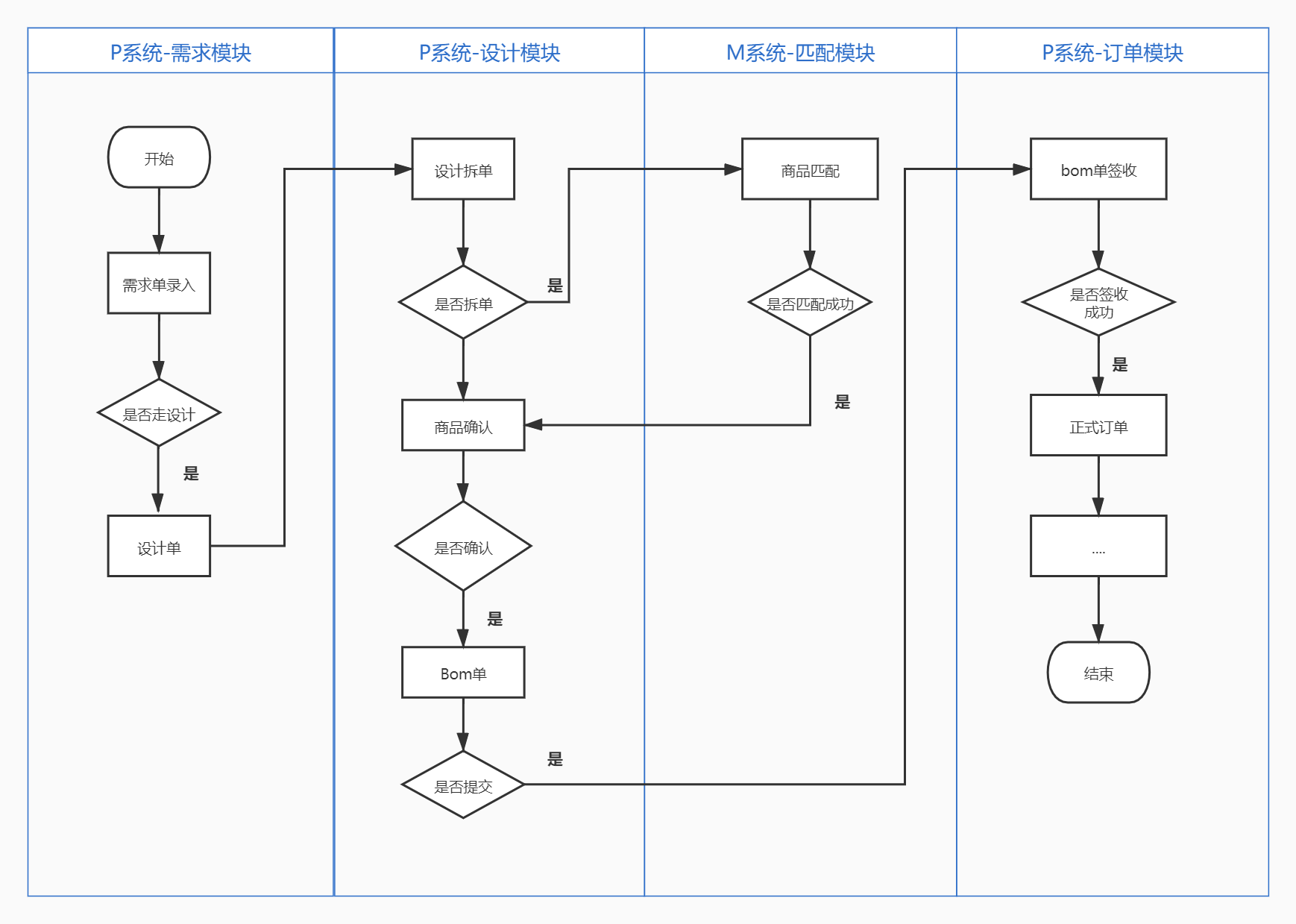
图1:项目系统流程图
2、用例分层
2.1 简要说明
该项目范围是订单模块,根据系统流程图可以知道,订单的数据需要走2个系统的交互,共涉及3个大模块。应项目要求,将需求单录入->bom单的流程实现接口自动化用例,对应功能步骤为需求单录入->商品确认成功。
2.2 官网用例分层示例图
分层思想如下:
测试用例(testcase)应该是完整且独立的,每条测试用例应该是都可以独立运行的
测试用例是测试步骤(teststep)的有序集合
测试用例集(testsuite)是测试用例的无序集合,集合中的测试用例应该都是相互独立,不存在先后依赖关系的;如果确实存在先后依赖关系,那就需要在测试用例中完成依赖的处理
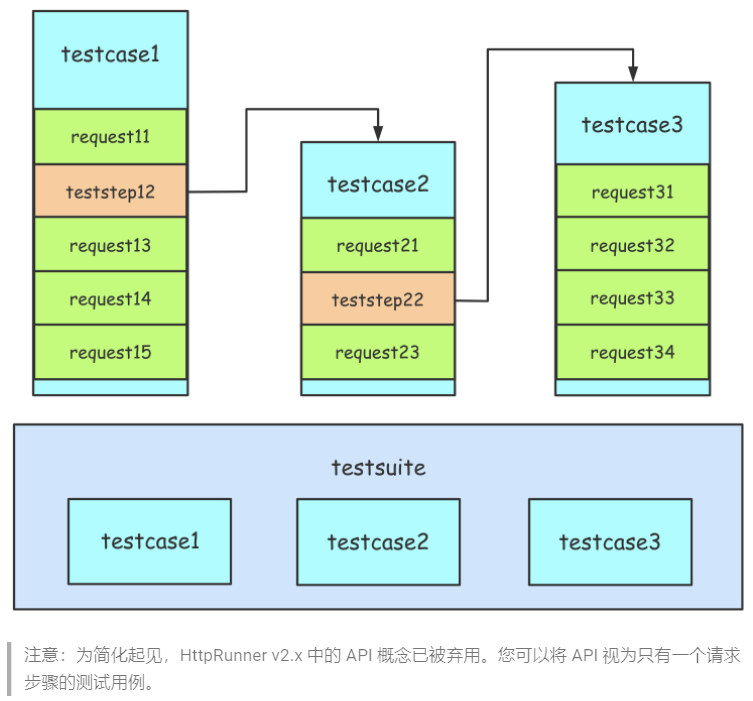
图2:官网分层示例图
3)项目用例分层架构
该项目用例分层架构图是根据自己的理解做的用例分层,如果各位大佬有其他好的用例拆分设计可以赐教下。
如图3,共有5条用例,用例跟用例之间有调用关系,因在测试用例中已经完成了用例依赖处理,所以testsuite的每条用例都是可以直接运行的,不存在先后顺序。
本项目存在个问题,应当都会存在这种问题,即当case3调用case2,若case2用例存在问题,那case3自然就会执行失败。
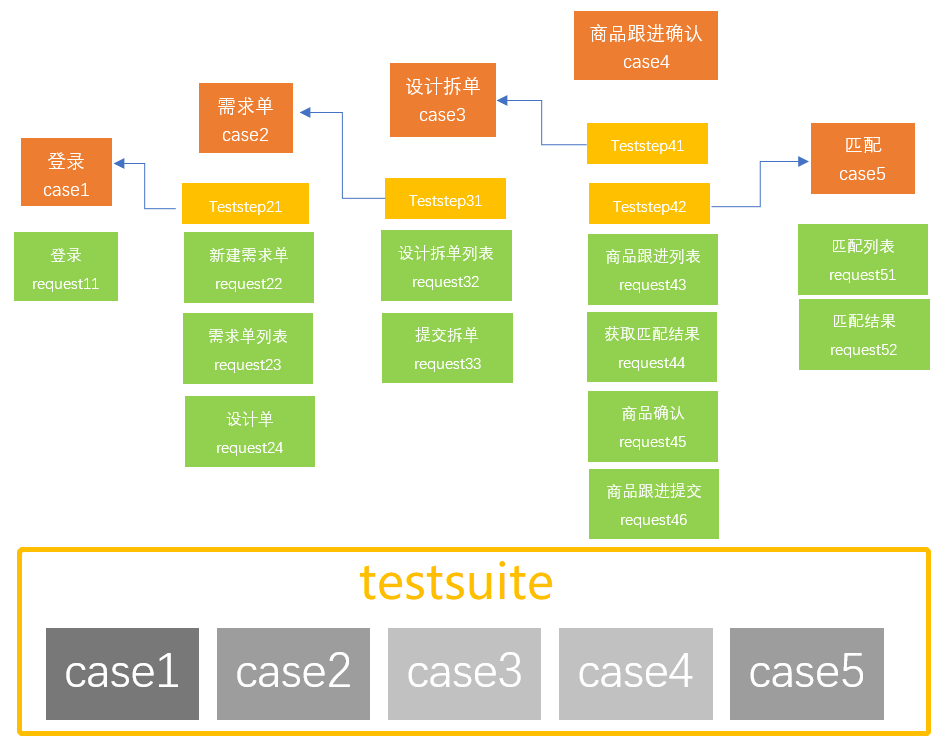
图3:项目用例分层架构图
三、项目源码解析
1、.env文件说明
env主要是存放环境配置的信息,比如url或者用户名密码之类的
username=李白password=123456 url=https://xxx.com
2、登录Case1:login_test.py
知识点1:结合实际情况,若有多个测试环境,url是会变的,用户名和密码也可能会频繁更换,所以可以考虑将url和用户名密码放在.env文件中,达到可配置化
知识点2:.env文件的变量取用:${ENV(文件内的键名)},详见下面标黄部分

httprunner = Config(=**: , , , , 200 ==
3、需求单Case2:demand_test.py
from testcases import login_test:该用例需要先调用登录用例,如果想要引用别的文件的用例,需要先import进来
RunTestCase:前面的文章讲过,这是直接调用别的用例,引用方式为.call(文件的类方法)
headers:该用例共有3个step,请求头是一样的,所以可以用一个变量存起来,便于后面step引用
.with_jmespath("body.data.list[0].styleCode","styleCode"):类似jmter的jsonpath写法,可以提取想要的响应字段,用于后面用例的引用
# NOTE: Generated By HttpRunner v3.1.5# FROM: har\需求单.harfrom httprunner import HttpRunner, Config, Step, RunRequest, RunTestCasefrom testcases import login_test
class TestCase需求单(HttpRunner):
config = Config("需求单录入-需求单列表-设计单").verify(False).base_url("https://xxx.cn") headers = {"Connection": "keep-alive", "Content-Length": "1480", }
teststeps = [
Step( RunTestCase("调用登录用例").call(login_test.TestCaseLogin)
),
Step(
RunRequest("需求单录入")
.put("/demand-task")
.with_headers( **headers
)
.with_cookies( **{ "experimentation_subject_id": "ImY3ZG"
}
)
.with_json(
{"deliveryTypePeriod": "2", "remark": "需求单", ......
}
)
.extract()
.with_jmespath("body.data.demandDetailId","demandDetailId") #提取detaildid,taskid供后续用例使用
.with_jmespath("body.data.demandTaskId","demandTaskId")
.validate()
.assert_equal("status_code", 200)
),
Step(
RunRequest("需求列表接口")
.post("/list")
.with_headers( **headers
)
.with_json(
{ "demandTaskType": "",
}
)
.extract() .with_jmespath("body.data.list[0].styleCode","styleCode")
.validate()
.assert_equal("status_code", 200)
),
Step(
RunRequest("设计单接口")
.put( "/task/${demandDetailId}" #引用前面提取的detaildid
)
.with_headers( **headers
)
)
.with_json(
{ "current": "178",
}
)
.validate()
.assert_equal("status_code", 200)
),
]if __name__ == "__main__":
TestCase需求单().test_start()
4、设计拆单Case3:design_test.py
export(*["styleCode","demandTaskId"]):这里需要用到case2提取出来的参数,所以要用.export导出参数变量,供case3引用,引用方式为 ${参数名}
teardown_hook("${sleep(2)}"):case2和case3所属的模块归属于不同的服务,case2服务完成设计单推送到case3服务时会存在回调时间差的情况,
所以需要使用teardown_hook,让用例执行完后,等待几秒再运行后面的step。(原理是调用debugtakl.py的sleep函数,达到延迟执行的目的)
# NOTE: Generated By HttpRunner v3.1.5# FROM: har\设计拆单.harfrom httprunner import HttpRunner, Config, Step, RunRequest, RunTestCasefrom testcases import demand_testclass TestCase设计拆单(HttpRunner):
config = Config("设计拆单列表-提交拆单").verify(False).base_url("https:xxx.cn")
headers = {"Connection": "keep-alive", }
teststeps = [
Step(
RunTestCase("调用需求单用例Case2").call(demand_test.TestCase需求单).export(*["styleCode","demandTaskId"]).teardown_hook("${sleep(2)}")
),
Step(
RunRequest("设计拆单列表接口")
.post("type/list")
.with_headers( **headers
)
.with_json(
{ "prototypeStatus": "1",
}
)
.extract()
.with_jmespath("body.data.list[0].prototypeId","prototypeId")
.with_jmespath("body.data.list[0].designCode","designCode")
.validate()
.assert_equal("status_code", 200)
),
Step(
RunRequest("提交拆单接口")
.put("/save")
.with_headers( **headers
)
)
.with_json(
{ "prototypeId": "${prototypeId}","styleCode": "${styleCode}", "demandTaskId": "${demandTaskId}", "designCode": "${designCode}",
}
)
.validate()
.assert_equal("status_code", 200)
)
]if __name__ == "__main__":
TestCase设计拆单().test_start()
5、商品跟进确认Case4:goods_test.py
httprunner testcases = Config().verify(False).base_url(=).call(design_test.TestCase设计拆单).teardown_hook().export(*[).call(confirm_test.TestCase匹配).teardown_hook(**: : : 1: 20,, 200**: **: ,, 200**: : : , 200**: : : : , 200 ==
6、匹配Case5:confirm_test.py
# NOTE: Generated By HttpRunner v3.1.5# FROM: har\匹配.harfrom httprunner import HttpRunner, Config, Step, RunRequest, RunTestCaseclass TestCase匹配(HttpRunner):
config = Config("匹配列表-匹配结果").verify(False).base_url("https://xxx.cn")
teststeps = [
Step(
RunRequest("匹配列表接口")
.post("/list")
.with_headers( **{"Connection": "keep-alive", }
)
.with_json(
{"pageNum": 1, "pageSize": 10,
}
)
.extract()
.with_jmespath("body.data.list[0].demandId","demandId")
.validate()
.assert_equal("status_code", 200)
),
Step(
RunRequest("匹配结果接口")
.post("/match/create")
.with_headers( **{"Connection": "keep-alive", "Content-Length": "577", }
)
.with_json(
{ "bottomCloth": "","colorNumber": "1.0", "commodityCode": "PURE",
}
)
.validate()
.assert_equal("status_code", 200)
),
]if __name__ == "__main__":
TestCase匹配().test_start()
四、结束语
以上就是本项目运用httprunner实现接口自动化的全过程,因涉及到公司安全,所以源码中删减了部分信息,但这并不会影响整个思路的梳理哈,本次项目涉及到的知识点比较少,后续新项目如果有其他知识点运用,会继续更新进来,还有因为想要的参数 接口都有返回,所以这次没有用到数据库,如果对数据库连接感兴趣的,可以看我前面的博客,以及因项目原因,本次的断言信息基本是用它自动生成的断言,没有增加新的断言,但一般接口自动化中是需要跟落表信息或者关键id信息进行断言的。
来源 https://www.cnblogs.com/Chilam007/p/15359403.html