
Google发布FLAN,模型参数少400亿,性能超越GPT-3

新智元报道
来源:arXiv
编辑:LRS
【新智元导读】你是否抱怨过深度学习这畸形的研究发展路线,大公司才能玩得起 sota,普通人连买张显卡都要承受几倍的溢价!最近 Google 发布了一个新的语言模型 FLAN,或许能在深度学习中带来新的发展趋势,它相比 GPT-3 少了 400 亿参数,性能还更强!
像 OpenAI 的 GPT-3 这样的语言模型,近年来层出不穷,企业也更愿意投入来研究如何利用 AI 技术和数据来学习文本生成等。
而 GPT-3 也不负众望,它及它的后继模型能够像人一样来写电子邮件、文本摘要、甚至写各种语言的代码。

但它也有一个致命缺点,那就是训练时间长,需要海量的训练数据,并且生成的模型参数量极大,需要高性能运算设备才能发挥全部性能。目前的研究也在朝着更大的语言模型、更多任务的数据方向发展。
传统观点认为,模型的参数越多,它可以完成的任务就越复杂,性能也越好。在机器学习中,参数是模型在进行预测时使用的内部配置变量,通过不同的参数可以对不同的问题进行拟合。
但是越来越多的研究对这个概念提出了质疑。最近,谷歌的研究人员发表了一项研究,声称他们发布了一个参数量远小于 GPT-3 的模型——微调语言网络 (fine-tuned language net, FLAN),并且在许多有难度的基准测试中性能都大幅超过 GPT-3。

论文地址:https://arxiv.org/pdf/2109.01652.pdf
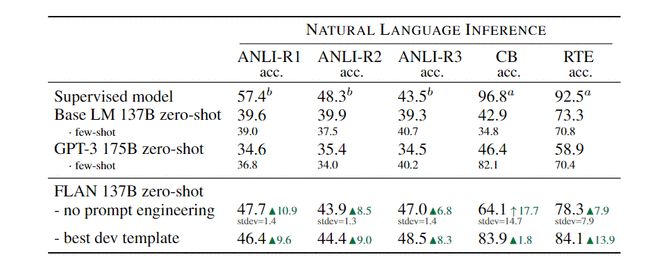
与 GPT-3 的 1750 亿个参数相比,FLAN 拥有 1370 亿个参数,在研究人员对其进行测试的 25 项任务中,有 19 项超过了 zero-shot 175B GPT-3。
FLAN 甚至在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 上的表现都大大超过了 few-shot GPT-3。
消融研究表明,任务数量和模型规模是教学调整成功的关键因素
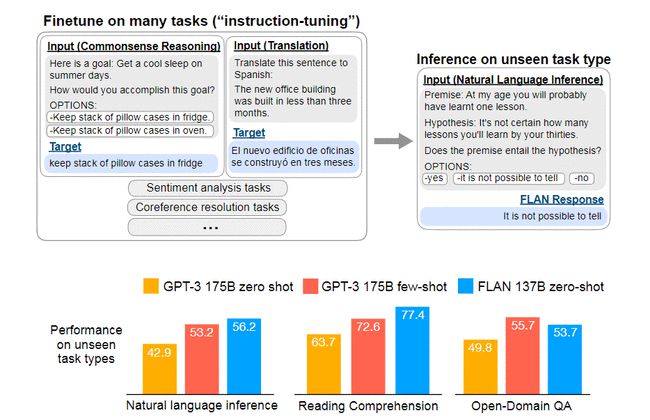
FLAN 与 GPT-3 的不同之处在于,FLAN 面向 60 项自然语言处理任务进行了微调,这些任务通过自然语言指令来表达,例如情感分类中使用“这条影评的情绪是正面还是负面?”来表示。
FLAN 是 Base LM 的指令调优(instruction-tuned)版本。指令调优管道混合了所有数据集,并从每个数据集中随机抽取样本。
各个数据集的样本数相差很大,有的数据集甚至有超过 1000 万个训练样本(例如翻译),因此将每个数据集的训练样例数量限制为 30000 个。
有的数据集几乎没有训练样本,例如 CommitmentBank 只有 250 个样本,为了防止这些数据集被边缘化,遵循样本比例混合方案(examples-proportional mixing schema),在最大混合率为 3000 的情况下,使用 Adafactor 优化器以 3e-5 的学习率,以 8192 的 batch size 对所有模型进行 30000 次梯度更新的微调。
微调过程中使用的输入和目标序列长度分别为 1024 和 256。使用 packing 将多个训练样本组合成一个序列,使用特殊的序列结束标记将输入与目标分离。
谷歌的研究人员表示,这种指令调节(instruction tuning)通过教模型如何执行指令描述的任务来提高模型处理和理解自然语言的能力。
在 FLAN 对网页、编程语言、对话和维基百科文章的训练后,研究人员发现,该模型可以学习按照未经明确训练的任务进行操作,也就是说可以部分理解了自然语言的真实意图。尽管训练数据不如 GPT-3 的训练集“干净”,但 FLAN 仍然在问答和长文摘要等任务上超过了 GPT-3。
除此之外,FLAN 的 zero-shot 和 few-shot 性能与也比 GPT-3 好一些,这也表明模型有能力遵循各种指令。
除了速度优势,更小、更仔细微调(more carefully tuned)的模型还可以解决一些大型语言模型可能产生的其他问题,例如环境影响。
2020 年 6 月,马萨诸塞大学艾摩斯特分校的研究人员发布了一份报告,估计训练和搜索某一模型所需的电力量约为 626000 磅二氧化碳的排放量,相当于美国平均汽车寿命排放量的 5 倍。

谷歌的一项研究也发现,GPT-3 在训练期间使用了 1287 兆瓦电,产生了 552 吨的二氧化碳排放。相比之下,FLAN 只使用了 451 兆瓦电,产生了 26 吨的二氧化碳。
麻省理工学院最近一篇论文也说明,如果按照大型语言模型的趋势继续下去,从硬件、环境和资金的角度来看,训练的成本将变得令普通人无法触及。以低经济的方式实现高性能目标需要更高效的硬件、更高效的算法或其他改进,才能够让整体的收益保持为正。
康奈尔大学的自然语言处理研究员 Maria Antoniak 就曾公开表示,是否一定需要更大的模型才能处理好自然语言,目前来说这个问题还没有答案。即便说基准测试的排行榜被这些大模型刷了个遍,但把更多的数据输入到模型中,是否能继续带来性能提升,还是不确定的。
并且 NLP 的领域的评测通常是以任务为中心,研究人员通常共同解决特定数据集上的特定问题,这些任务通常是结构化的,并且所能涵盖的自然语言问题也是比较单一的。虽然在排行榜上取得更好的成绩代表模型性能更强,这种研究方法也在促进者 NLP 技术的发展,也可能限制研究人员在泛化性上的思考。并且这种研究结果能否最终进行真正的语言理解还有待商榷。
谷歌研究中提到大型语言模型的问题可能在于用于训练它们的数据以及常见的训练方法。例如奥地利维也纳大学医学院人工智能研究所的研究人员发现,GPT-3 在生物医学领域中的表现并不如小型架构但精细的模型。

即使在对生物医学数据进行预训练和微调后,研究者们还发现大的语言模型很难在问答、文本分类和识别上与更小的模型相媲美。
实验结果表明,在生物医学自然语言处理领域,多任务语言模型仍有很大的发展空间,很少有模型能够在少量训练数据可用的情况下有效地将知识转移到新任务。
这也可以归结为数据质量的问题。社区驱动项目 EleutherAI 的数据科学家 Leo Gao 的另一篇论文表明,训练数据中集中数据的管理方式会显著影响大型语言模型的性能。

通常研究人员普遍认为,使用分类器过滤掉来自「低质量源」像 Common Crawl 的数据可以提高训练数据质量,但过度过滤会导致类似 GPT 的语言模型性能下降。
通过对分类器得分进行过度的优化,会使得保留的数据开始以满足分类器要求的方式而出现偏差,从而生成一个不太丰富、多样性不足的数据集。
从直觉上看,丢弃的数据越多,剩余数据的质量就越高,但研究人员发现,基于浅分类器的过滤并不总是如此。相反,过滤在一定程度上提高了下游任务的性能,但随着过滤变得过多,性能又会下降高。可以推测这是由于 Goodhart 定律造成的,随着优化压力的增加,agent 和真实目标之间的不一致变得更加明显。

Goodhart 定律内容:当一个措施本身成为目标时,它就不再是一个好的措施。
(When a measure becomes a target, it ceases to be a good measure.)
参考资料:
https://arxiv.org/pdf/2109.01652.pdf
来自: www.163.com