
Spark Ignite踩坑记录
简述
ignite访问数据有两种模式:
Thin Jdbc模式;
Jdbc 模式和Ignite client模式;
shell客户端输出问题,不能输出全列;
针对上述三个问题,我们一一说明一下
详述
Thin Jdbc
瘦客户端的模式是官网介绍的模式,这种模式类似关系型数据库jdbc的访问模式,有两个参数
ignite.jdbc.distributedJoins 启用分布式join的开关
ignite.jdbc.enforceJoinOrder 在查询中强制表join顺序的开关
这两个开关默认都是false,如需开启在URL中添加参数直接指定即可,这部分基本没什么好说的
注意:schema大小写不敏感
Jdbc client
这种方式区别于瘦客户端,我们姑且叫他胖客户端吧,最开始ignite有直接JDBC的模式,但这种方式现在已经废弃了,现在IgniteJdbcDriver这个类提供的其实就ignite client的这种访问模式,里面可以指定多个参数,包含cache、local等,大家看下这个类的源码,在类的注释部分有说明。
这种方式会在ignite集群的topo结构中看出连接集群的client节点。
但我要说的是,这个中方式最后会拼接出一个h2的链接,坑的是这个h2的链接中会包含一个h2都解析不了的参数,导致链接报错,报错的第一个参数是MULTIPLE_THREAD,还把这个URL申明成final的,导致调试的时候都不能手动指定value,坑啊,后面参数不知道还有没有未知参数,得改改ignite的源码了;
连接超时
这个问题更坑,客户端模式去连接集群时,会有个达到超时的时间,但这个设置是写死在程序里的,不可配置的,在win下连接集群的话,我们的环境通常2s是连不上的,下面是类和我在我本地做的链接测试:
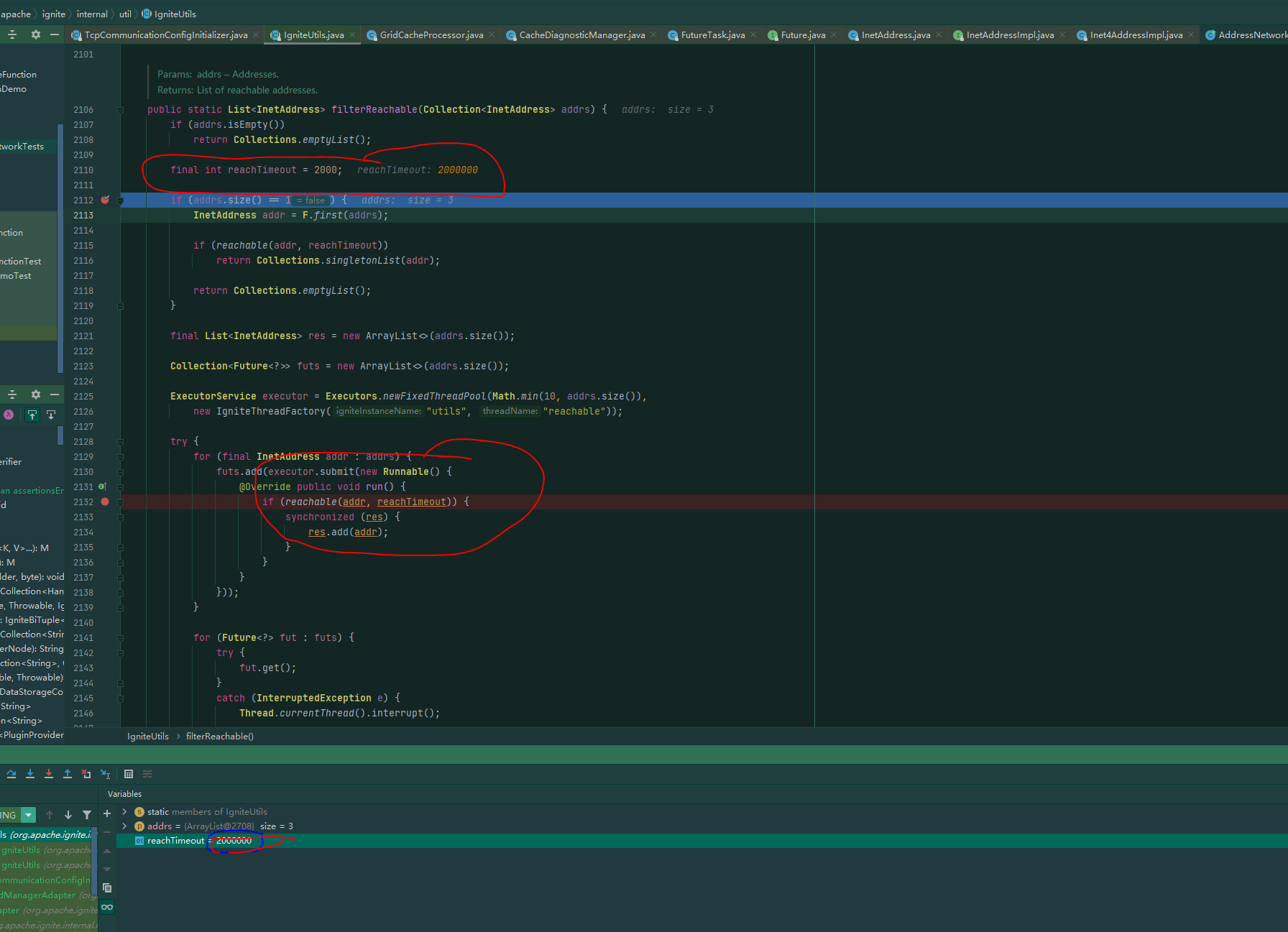
所用的时间:
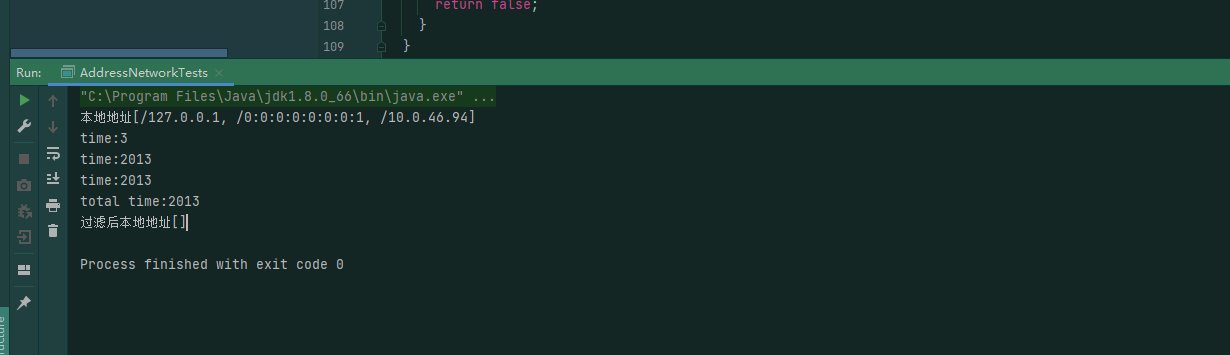
这个用起来让人感觉十分难受,要不就修改源码,把这个时间改大点,要不就每次程序走到这,断点,然后去给这个变量在线程中去set value,难受。
ignite shell 客户端
在使用ignite shell客户端时,如果列数比较多的话,直接给把后面的列显示给切断了,如果刚好切成了整列,你还以为导数的时候后面的列没导进去,产生错觉,难受;
与spark集成
这段时间一直在做ignite 与spark的集成测试,找了好几个数据集,也按照官网的方式试了几种方式,但没有出现性能提升,这个原因可能是我spark集群和ignite集群没有完全安装在相同的服务器导致的,也可能是ignite的原因,这个还需要再进行定位。
最后
Ignite这个组件虽然是Java写的,但是官网的介绍很简略,只是说明的了下,怎么操作,怎么配置,对其存储的原理,里面的设计细节以及实现并没有详细的说明,而且网上的资料很少,遇到问题只能是追代码、看源码,不想Hadoop、spark这种组件我对起里面的存储、计算的实现也是清晰的,用起来感觉有点别扭;而且和spark这种明星组件集成,可以官方给出个性能的测试的,现在大数据环境都有基准的测试包,从2018年提供了这种集成能力之后,再也没有关于这部分的更新,spark版本只支持2.3、2.4,在ignite3.0(开发)中会对spark3.0有支持,希望到时候能有个官方的测试说明吧,完毕。