
ElasticSearch进阶检索
ElasticSearch进阶检索
入门检索中讲了如何导入elastic提供的样本测试数据,下面我们用这些数据进一步检索
一、SearchAPI
ES 支持两种基本方式检索 :
1、一种是通过使用 REST request URI 发送搜索参数(uri+检索参数)
GET bank/_search 检索 bank 下所有信息,包括 type 和 docs
GET bank/_search?q=*&sort=account_number:asc 请求参数方式检索
2、另一种是通过使用 REST request body 来发送它们(uri+请求体)
GET /bank/_search
{ "query": { "match_all": {}
}, "sort": [
{ "account_number": "asc"
}
]
}# query 查询条件# sort 排序条件响应结果
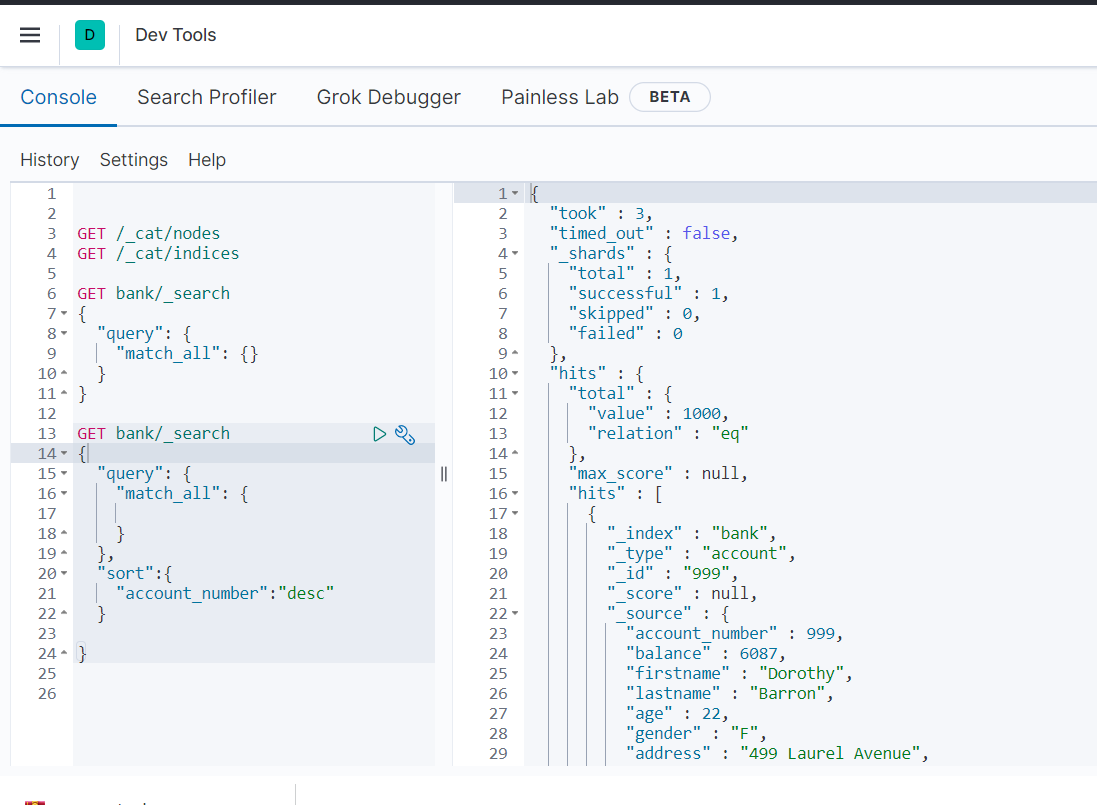
响应结果解释:
took - 执行搜索的时间(毫秒)
time_out - 告诉我们搜索是否超时
_shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片
hits - 搜索结果
hits.total - 搜索结果条数
hits.hits - 实际的搜索结果数组(默认为前 10 的文档)
sort - 结果的排序 key(键)(没有则按 score 排序)
score 和 max_score –相关性得分和最高得分(全文检索用)
二、Query DSL
1、基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特
定语言)。这个被称为 Query DSL。
一个查询语句的典型结构:
QUERY_NAME:{ ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}如果针对于某个字段,那么它的结构如下:
{ QUERY_NAME:{
FIELD_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}请求示例
GET bank/_search{ "query": { "match_all": {}
}, "from":0, "size":5, "sort": [
{ "balance": { "order": "desc"
}
}
]
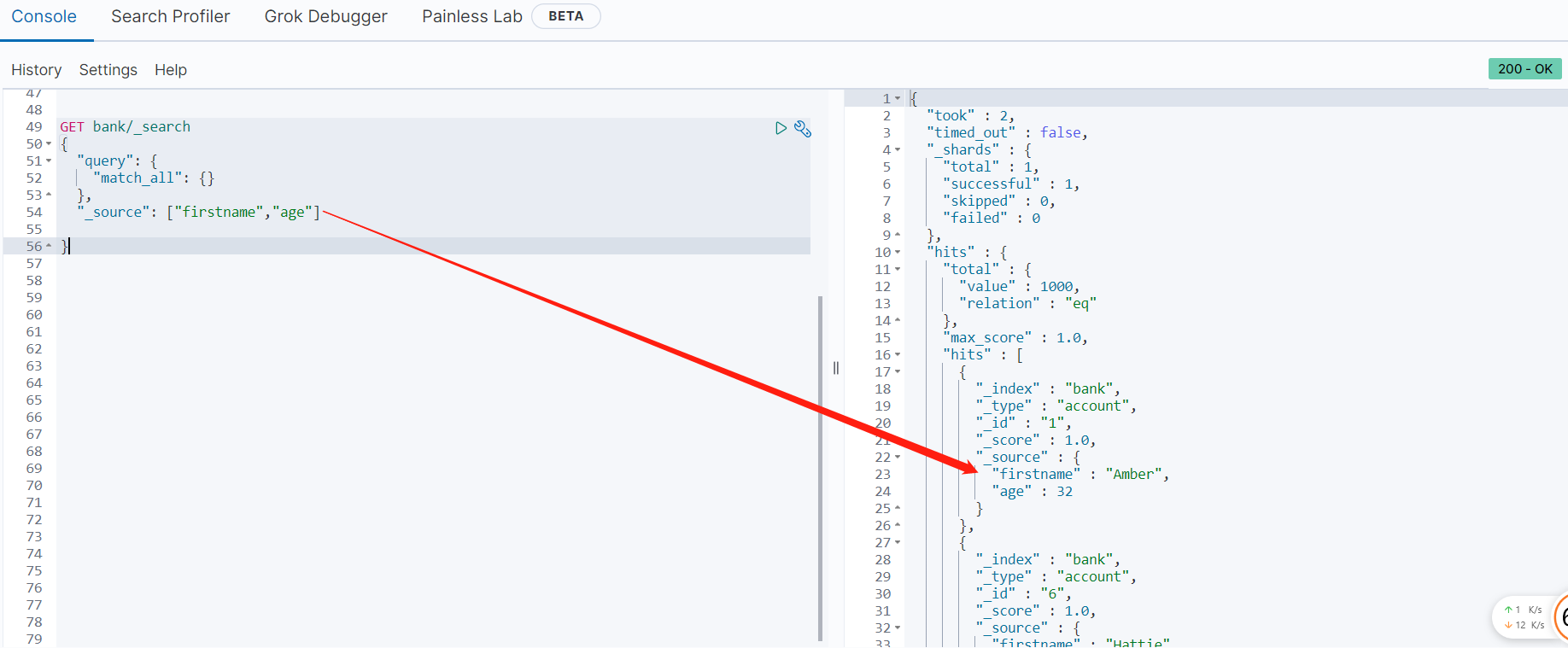
}#query 定义如何查询#match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查询类型完成复杂查询#除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size from+size 限定完成分页#sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准2、返回部分字段
_source:需要返回哪些字段写在数组中即可
3、match【匹配查询】
(1)对于基本数据类型的(非字符串),进行精确匹配
GET bank/_search{ "query": { "match": { "account_number": 10
}
}
}#match 返回 account_number=10 的(2)对于字符串类型的字段,进行全文检索,模糊匹配
GET bank/_search{ "query": { "match": { "address": "mill"
}
}
}#最终查询出 address 中包含 mill 单词的所有记录#match 当搜索字符串类型的时候,会进行全文检索,并且每条记录有相关性得分(3)字符串,多个单词(分词+全文检索)
GET bank/_search{ "query": { "match": { "address": "mill road"
}
}
}#最终查询出 address 中包含 mill 或者 road 或者 mill road 的所有记录,并给出相关性得分(_score),也会按照这个评分排序(4)精确匹配文本字符串
GET bank/_search{ "query": { "match": { "address.keyword": " Mill road"
}
}
}# 查找 address完全为Mill Street 的数据4、match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不分词)进行检索
GET bank/_search{ "query": { "match_phrase": { "address": "mill road"
}
}
}#查出 address 中包含 mill road 的所有记录,并给出相关性得分5、multi_match【多字段匹配】
GET bank/_search{ "query": { "multi_match": { "query": "mill", "fields": [ "city","address"
]
}
}
}#检索 city 或 address 匹配包含 mill 的数据,会对查询条件分词6、bool【复合查询】
bool 用来做复合查询: 复合语句可以合并任何其它查询语句,包括复合语句,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
(1)must:必须达到must所列举的所有条件
GET bank/_search{ "query": { "bool": { "must": [
{"match": {"firstname": "Forbes"}},
{"match": {"gender": "M"}}
]
}
}
}(2)must_not 必须不是指定的情况
GET bank/_search{ "query": { "bool": { "must": [
{"match": {"firstname": "Forbes"}},
{"match": {"gender": "M"}}
], "must_not": [
{"match": {"lastname": "Wallace"}}
]
}
}
}(3)should:应该达到 should列举的条件
如果达到会增加相关文档的评分并不会改变 查询的结果。如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果
GET bank/_search{ "query": { "bool": { "must": [
{"match": {"address": "mill"}},
{"match": { "gender": "M" }}
], "should": [ {"match": { "address": "lane" }} ]
}
}
}#应该匹配,匹配到能增加文档相关性得分,匹配不到也不会影响查询结果7、filter【结果过滤】
不是所有的查询都需要计算相关性得分,仅用于 “filtering”(过滤)的文档。为了不计算分数 Elasticsearch 会自动检查场景并且优化查询的执行。
GET bank/_search{ "query": { "bool": { "must": [
{"match": {"address": "mill"}}
], "filter": [
{"range": { "balance": { "gte": 10000, "lte": 20000
}
}}
]
}
}
}#range范围查询,大于1000小于200008、term精确检索
避免使用 term 查询文本字段,默认情况下,Elasticsearch 会通过analysis分词将文本字段的值拆分为一部分,这使精确匹配文本字段的值变得困难。如果要查询文本字段值,请使用 match 查询代替。
和 match 一样,匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term
GET bank/_search{ "query": { "term": { "age": "20"
}
}
}9、Aggregation-执行聚合
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL聚合函数。
详细的介绍可以查看官网关于Aggregation的文档,下面提供几个示例来看一下聚合
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/search-aggregations.html
(1)搜索address中包含 mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search{ "query": { "match": { "address": "mill"
}
}, "aggs": { "group_by_state": { "terms": { "field": "age"
}
}, "avg_age":{ "avg": { "field": "age"
}
}
}, "size": 0}#size:0 不显示搜索数据#aggs:执行聚合。聚合语法如下:#"aggs": {
"aggs_name 这次聚合的名字,方便展示在结果集中": { "AGG_TYPE 聚合的类型(avg,term,terms)": { "field": "age"
}
}
}(2)按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET bank/_search{ "query": {"match_all": {}}, "aggs": { "group_by_state": { "terms": { "field": "age"
}, "aggs": { "avg_age": { "avg": { "field": "age"
}
}
}
}
}
}#其实就是aggs里面又加了一个aggs,第二个aggs根据第一个aggs聚合后的结果在聚合(3)查出所有年龄分布,并且这些年龄段中 性别为M 的平均薪资和 性别为F 的平均薪资以及这个年龄
段的总体平均薪资
GET bank/_search{ "query": {"match_all": {}}, "aggs": { "age_avg":{ "terms": { "field": "age", "size": 1000
}, "aggs": { "gender_avg": { "terms": { "field": "gender.keyword", "size": 10
}, "aggs": { "balance_avg": { "avg": { "field": "balance"
}
}
}
}, "balance_avg": { "avg": { "field": "balance"
}
}
}
}
}
}分类: Java
来源https://www.cnblogs.com/dupengpeng/p/15127449.html