
UI自动化学习笔记- PO模型介绍和使用
UI自动化学习笔记- PO模型介绍和使用
一、PO模型
1、PO介绍:page(页面) object(对象)
在自动化中,Selenium 自动化测试中有一个名字经常被提及 PageObject (思想与面向对象的特征相同),通常PO 模型可以大大提高测试用例的维护效率。
优点:
提交测试脚本可读性
减少代码重复
提高测试用例的可维护性,特别是针对UI变动频繁的项目缺点:
结构复杂:基于流程进行了模块化的拆分结构:
base(基类)
page(页面对象)
scripts(业务层)
扩展:
loc 变量:类型为元组:*loc为解包
2、PageObject 设计模式
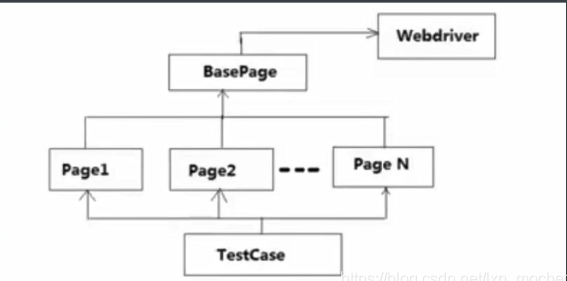
3、PO 的核心要素
在 PO 模式中抽离封装集成一个 BasePage 类,该基类应该拥有一个只实现 webdriver 实例的属性
每一个page 都继承BasePage,通过 driver 来管理 page 中元素,将 page 中的操作封装成一个个方法
TestCase 继承 unittest.TestCase类,并依赖page类,从而实现相应的测试步骤
二、将Selenium代码封装成PO模型
1、案例说明(简单的登录测试用例)
(1)改造案例思路:
第一, 我们要分离测试对象(元素对象)和测试脚本(用例脚本),那么我们分别创建两个脚本文件,分别为:
LoginPage.py用于定义页面元素对象,每一个元素都封装成组件(可以看做存放页面元素对象的仓库)TestCaseLogin.py测试用例脚本。第二,抽取出公共方法定义在
base.py文件中,每个Page类都要继承这个base.py文件,也就是每Page类都能使用base类中的方法,来操作页面中的元素,同时也可以在每个Page类中定义自己独有的方法,解决工作中的实际需求。第三,设计实现思想,一切元素和元素的操作组件化定义在
Page页面,用例脚本页面,通过调用Page中的组件对象,进行拼凑成一个登录脚本。
(2)封装公共操作在base类(base.py)
把一些公共的方法放到此类中,这个类将被PO对象继承。
from selenium.common.exceptions import NoSuchElementExceptionfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.support.wait import WebDriverWaitclass Base(object): def __init__(self, driver): self.driver = driver # 查找元素方法(提供:点击、输入、获取文本)使用 def base_find_element(self, loc, timeout=30, poll=0.5): element, index = loc[:2], loc[-1] try: ele = WebDriverWait( self.driver, timeout=timeout, poll_frequency=poll ).until( lambda x: x.find_elements(*element) )[index] except (NoSuchElementException, TimeoutError, IndexError): return False else: return ele # 点击方法 def base_click(self, loc): self.base_find_element(loc).click() # 输入方法 def base_input(self, loc, value): el = self.base_find_element(loc) # 清空 el.clear() # 输入 el.send_keys(value) # 获取文本方法 def base_get_text(self, loc): return self.base_find_element(loc).text # 获取当前页面地址 def base_get_current_url(self): return self.driver.current_url # 鼠标悬停事件 def base_move_to_element(self, loc): ActionChains(self.driver).move_to_element(loc).perform()
(3)每个页面对应一个Page类(login_page.py)
定位元素的定位器和操作元素方法分离开,元素定位器全部放一起,然后每一个操作元素动作写成一个方法。
from selenium.webdriver.common.by import Byfrom public.base import Base login_username = (By.CLASS_NAME, 'el-input__inner', 1) login_password = (By.CLASS_NAME, 'el-input__inner', 2) login_btn = (By.CLASS_NAME, 'login__button', 0) organ_name = (By.CSS_SELECTOR, '.role-names-button', 0) logout_btn = (By.CLASS_NAME, 'logout', 0) password_login_text = (By.CSS_SELECTOR, '.pwd-login', 0)class LoginPage(object): def __init__(self, driver): self.element = Base(driver) # 输入手机号 def input_username(self, content): self.element.base_input(login_username, content) # 输入密码 def input_password(self, content): self.element.base_input(login_password, content) # 点击登录 def click_login_button(self): self.element.base_click(login_btn) # 获取当前页面url def get_current_url(self): return self.element.base_get_current_url() # 点击机构名称 def click_to_organ_name(self): self.element.base_click(organ_name) # 点击退出 def click_logout(self): self.element.base_click(logout_btn) # 获取“密码登录”文字 def get_password_login_text(self): return self.element.base_get_text(password_login_text)
(4)封装业务层(login_business.py)
import timefrom Test.Page.login_page import *class LoginBusiness(object): def __init__(self, driver): self.login_business = LoginPage(driver) # 登录系统 def go_system(self, username, password): self.login_business.input_username(username) self.login_business.input_password(password) self.login_business.click_login_button() time.sleep(2) return self.login_business.get_current_url() # 退出成功 def logout(self): self.login_business.click_to_organ_name() self.login_business.click_logout() return self.login_business.get_password_login_text()
(4)原登陆案例封装完成代码
测试方法及测试类的执行都在此文件中。
from Test.Case.base_case import LoginBaseCasefrom public.get_log import LogInfofrom public.read_ini import get_valuefrom Test.Business.login_business import LoginBusinessclass TestLogin(LoginBaseCase, LogInfo):
""" 登录退出测试用例 """ @classmethod
def setUpClass(cls) -> None:
cls.case_forward()
LogInfo().log.info('TestLogin Cases Suite Start Running')
cls.login = LoginBusiness(cls.driver) @LogInfo.get_error
def test_1(self):
""" 登录流程 """
self.log.info('TestCase1 Start Running') # 获取用户名密码
username = get_value(get_value('Base', 'Env'), 'username')
password = get_value(get_value('Base', 'Env'), 'password')
url = self.login.go_system(username, password)
text = "https://gssdev.haoshengy.com/pc_workbench/workbench/overview"
self.assertEqual(url, text, '当前页面URL不正确--测试不通过') def test_2(self):
""" 退出登录 """
self.log.info('TestCase2 Start Running')
text = self.login.logout()
self.assertEqual("密码登录", text, '首页密码登录字样错误--测试不通过')三、数据驱动
1.1 什么是数据驱动
数据驱动:是以数据来驱动整个测试用例的执行,也就是测试数据决定测试结果
1.2 数据驱动的特点
数据驱动本身不是一个工业级标砖的概念,因此在不同的公司都会有不同的解释
可以把数据驱动理解成一种模式或者一种思想
数据驱动技术可以让用户把关注点放在测试数据的构建和维护上,而不是直接维护脚本,可以利用同样的过程对不同的数据输入进行测试
数据驱动的实现要依赖参数化的技术
1.3 传入数据的方式(测试数据的来源)
直接定义在测试脚本中(简单直观,但代码和数据未实现真正的分离,不方便后期维护)
从文件读取数据,如json、Excel、xml、txt、等格式文件
从数据库中读取数据
直接调用接口获取数据源
本地封装一些生成数据的方法
来源https://www.cnblogs.com/Emliy/p/15054532.html