
java爬虫(一)主流爬虫框架的基本介绍
java爬虫(一)主流爬虫框架的基本介绍
引言
获取:目前都有哪些爬虫技术?
理解:这些爬虫技术的特色是什么?
扩展:快速上手一下cdp4j爬虫技术。
纠错:解析网页过程中踩过的坑与填坑之路。
应用:实战爬取网易新闻评论内容。
正文
一、目前的主流java爬虫框架包括

Python中有Scrapy、Pyspider;
Java中有Nutch,WebMagic,WebCollector,heritrix3,Crawler4j
这些框架有哪些优缺点?
(1)、Scrapy:

Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试.
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrap,是碎片的意思,这个Python的爬虫框架叫Scrapy。
优点:
1.极其灵活的定制化爬取。
2.社区人数比较多、文档比较完善。
3.URL去重采用布隆过滤器方案。
4.可以处理不完整的HTML,Scrapy已经提供了selectors(一个在lxml的基础上提供了更高级的接口),
可以高效地处理不完整的HTML代码。
缺点:
1.对新学员不友好,需要一定新手期
(2)、Pyspider:

pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
优点:
1.支持分布式部署。
2.完全可视化,对用户非常友好:WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出。
3.简单,五分钟就能上手。脚本规则简单,开发效率高。支持抓取JavaScript的页面。
总之,Pyspider非常强大,强大到更像一个产品而不是一个框架。
缺点:
1.URL去重使用数据库而不是布隆过滤器,亿级存储的db io将导致效率急剧降低。
2.使用上的人性化牺牲了灵活度,定制化能力降低。
(3)Apache Nutch(高大上)

Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫,Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的.
Nutch这个框架运行需要Hadoop,Hadoop需要开集群,对于想要快速入门爬虫的我是望而却步了......
一些资源地址列在这里,说不定以后会学习呢。
Apache顶级项目列表
Nutch官网
Nutch官方教程
1.Nutch支持分布式抓取,并有Hadoop支持,可以进行多机分布抓取,存储和索引。另外很吸引人的一点在于,它提供了一种插件框架,使得其对各种网页内容的解析、各种数据的采集、查询、集群、过滤等功能能够方便的进行扩展,正是由于有此框架,使得 Nutch 的插件开发非常容易,第三方的插件也层出不穷,极大的增强了 Nutch 的功能和声誉。
缺点
1.Nutch的爬虫定制能力比较弱
(4)、WebMagic

WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
优点:
1.简单的API,可快速上手
2.模块化的结构,可轻松扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面抓取
(5)、WebCollector

WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
优点:
1.基于文本密度的网页正文自动抽取
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只能单机
2.无URL优先级调度
3.活跃度不高
(6)、Heritrix3

Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源
优点
Heritrix的爬虫定制参数多
缺点
1.单实例的爬虫,之间不能进行合作。
2.在有限的机器资源的情况下,却要复杂的操作。
3.只有官方支持,仅仅在Linux上进行了测试。
4.每个爬虫是单独进行工作的,没有对更新进行修订。
5.在硬件和系统失败时,恢复能力很差。
6.很少的时间用来优化性能。
7.相对于Nutch,Heritrix仅仅只是一个爬虫工具,没有提供搜索引擎。如果要对抓取的站点排序必须要实现类似于Pagerank的复杂算法。
(7)、Crawler4j

Crawler4j是一款基于Java的轻量级单机开源爬虫框架
优点
1.多线程采集
2.内置了Url 过滤机制,采用的是BerkeleyDB 进行url的过滤。
3.可扩展为支持结构化提取网页字段,可作为垂直采集用
缺点
1.不支持动态网页抓取,例如网页的ajax部分
2.不支持分布式采集,可以考虑将其作为分布式爬虫的一部分,客户端采集部分
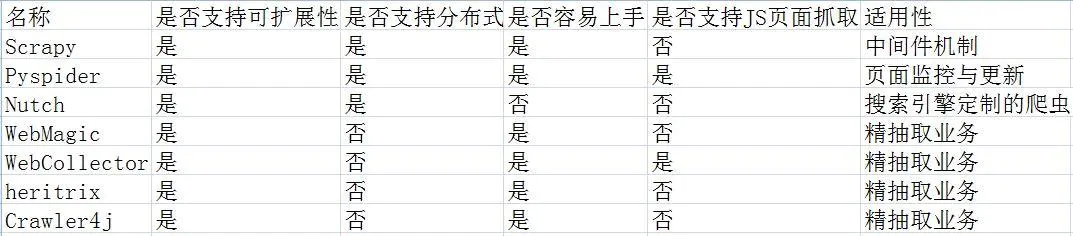
为了更加直观这7种爬虫框架,小编做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期实训老师讲解的框架。有近乎完整的文档介绍。
和HtmlUnit同样,只能get到静态内容。
不过,这个框架有个有个优点,具有很强大的解析网页的功能。
Jsoup中文教程
selenium(Google多名大佬参与开发)
感觉很厉害,实际真的很厉害,看官网以及其他人的介绍,说是真正模拟浏览器。GitHub1.4w+star,你没看错,上万了。但是我硬是没配好环境。入门Demo就是没法运行成功,所以就放弃了。
selenium 官方GitHub
cdp4j(方便快捷,但是需要依赖谷歌浏览器)
使用前提:
安装Chrome浏览器,即可。
简单介绍:
HtmlUnit的优点在于,可以方便的爬取静态网友;缺点在于,只能爬取静态网页。
selenium的优点在于,可以爬取渲染后的网页;缺点在于,需要配环境变量等等。
将二者整合,取长补短,就有了cdp4j。
之所以选用它,是因为真的方便好用,而且官方文档详细,Demo程序基本都能跑起来,类名起的见名知意。想当年学软件工程的时候,一直在纳闷,为什么要写文档啊,我程序能实现功能不就得了?现如今,看着如此详实的文档,留下了激动而又悔恨的泪水......
cdp4j有很多功能:
a. 获得渲染后的网页源码
b. 模拟浏览器点击事件
c. 下载网页上可以下载的文件
d. 对网页进行截屏或转PDF打印
e. 等等
更多详细信息可以自行去如下三个地址中探索发现:
[cdp4j官网地址]
[Github仓库]
[Demo列表]
总结
上述框架各有优缺点,其中cdp4j方便且功能齐全,但个人觉得唯一不足就是需要依赖谷歌浏览器。