
Kafka 总结学习
Kafka 总结学习
最近在鹅厂工作中不断接触到Kafka,虽然以前也使用过,但是对其架构和发展过程总是模模糊糊,所以在回学校准备末考的时候找些资料总结一下。
Kafka Need No Keeper 是一个在Kafka Submit分享的标题,我也是看了Kafka needs no Keeper(关于KIP-500的讨论)这篇博客分享后才对Kafka有了初期的认识,如果想要了解细节的话可以直接阅读该博客分享,本篇博客是一次对Kafka的自我总结,多少有些大白话和概括之意。
|
Kafka是什么?Apache Kafka 是一款分布式流处理框架(新版本后,定位发生了改变),用于实时构建流处理应用。
Kafka的架构可以简单分为Client和Broker两部分。在Kafka发展过程中,Kafka都是不断减少这两部分对Zookeeper的依赖。
那为什么要减少对Zookeeper的依赖呢?
Kafka在新版本后定位变成了分布式流处理框架,但是本质上还是一个消息中间件,中间件与中间件之间不应该存在依赖关系,需要降低耦合。
Kafka与Zookeeper不断通信,不断写入数据,而Zookeeper一致性要求较高,当某个数据节点信息发生变更时,会通知其他节点同步更新,半数以上完成更新才能返回,写入性能较差,影响了Kafka的性能。
|
Client一般分为三类,Consumer Client、Producer Client和Admin Tool。
Producer Client 只需要向Kafka集群中发送消息,不需要连接Zookeeper
Consumer Client 需要读取某主题某分区内的消息,那么需要知道读取哪条消息(读取offset)和下一次读哪条消息(提交offset),所以需要和Zookeeper交互(offset保存在ZK中)
Admin Tool 执行主题的操作,因为元数据保存在ZK中,所以需要与ZK交互
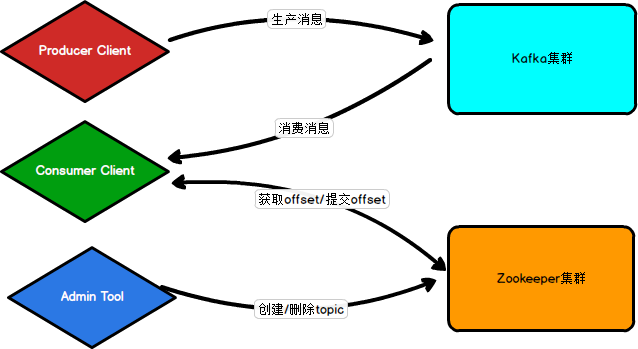
可以看出,Zookeeper在Kafka中①存储元数据
新版主要针对旧版中的Consumer Client和Admin Tool改进
Offset改进:在Kafka中新建一个内部主题_consumer_offset用来保存消费者组的offset,提交和获取offset都可以直接与Kafka集群交互获取。
Rebalance改进:在旧版架构中,消费者组中的消费者消费的主题分区信息都是保存在ZK中,在新版架构改进中,每一个消费组使用一个Coordinator来控制重分区过程。
Admin改进:社区引入了新的运维工具AdminClient以及相应的CreateTopics、DeleteTopics、AlterConfigs等RPC协议,替换了原先的Admin Tool,这样创建和删除主题这样的运维操作也完全移动Kafka这一端来做。
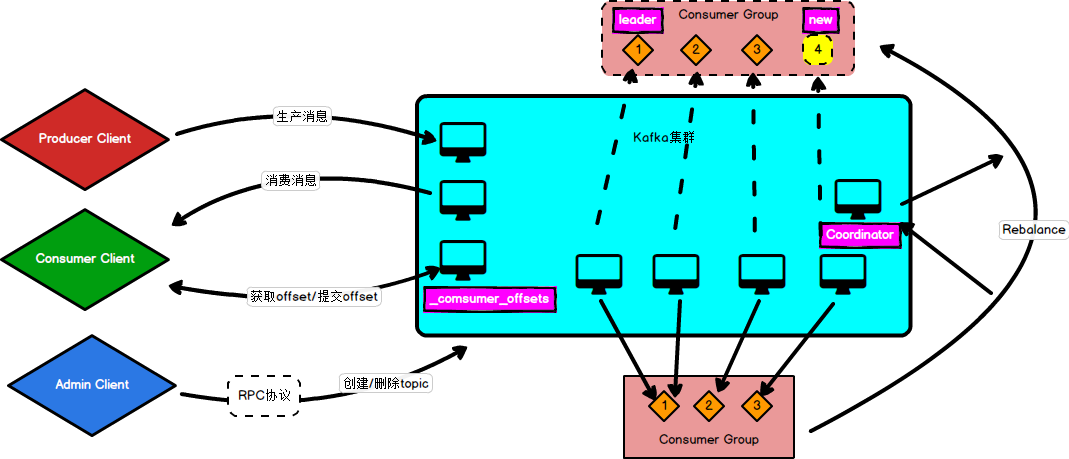
| 重分区是什么? | 如上图,重分区就是将消费者组里订阅主题下的分区重新分配给当前组内消费者实例的过程。 |
| 重分区发生条件是什么? | ①消费者组消费者数量改变; ②订阅的主题数量改变; ③订阅的主题下分区数量改变。 |
| 怎么进行重分区? | 真正的重分区是有Group Leader来完成的。 第一个进入Consumer Group的消费者实例为leader,它向Coordinator申请消费者组成员列表,然后按照分区策略进行分区,接着将分区的结果告诉Coordinator,最后由Coordinator告知所有的消费者分区信息。 |
| Coordinator是怎么找到的 | 消费者组向任意一个Broker发送groupCoordinatorRequest请求,集群返回一个负载最小的Broker节点使其成为当前消费者组的Coordinator。 |
| 分区策略是什么? | ①Range分区(默认):分块分区,对于每一个主题而言, 首先将分区按数字顺序排行序,消费者按名称的字典序排序,然后用分区总数除以消费者总数。如果能够除尽,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区。 ②RoundRobin分区:轮询分区,对所有主题而言,首先将所有主题的分区组成列表,然后按照列表重新轮询分配分区给不同的消费者。 |
|
在现阶段结构中,Broker端是严重依赖Zookeeper的,基本上所有元数据信息和管理都要通过Zookeeper集群,如下图:
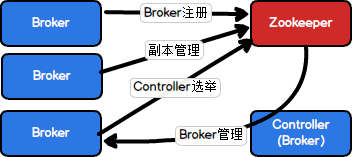
可以看出,Zookeeper在Kafka中有②集群管理和③选举Controller的作用
第一步首先是隔离非Controller端对ZK的依赖;
第二步是移除Controller端对ZK的依赖,这一步可以采用基于Raft的共识算法来做(?)。

|
|
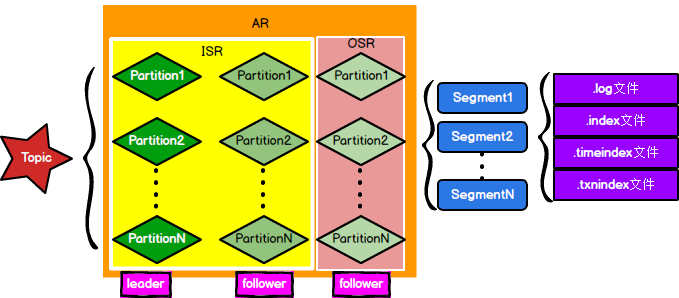
| LEO | Log End Offset。日志末端位移值或末端偏移量,表示日志下一条待插入消息的 位移值。 |
| LSO | Log Stable Offset。这是 Kafka 事务的概念。如果你没有使用到事务,那么这个值无意义。该值控制了事务型消费 者能够看到的消息范围。它经常与 Log Start Offset,即日志起始位移值相混淆,因为 有些人将后者缩写成 LSO,这是不对的。在 Kafka 中,LSO就是指代 Log Stable Offset。 |
| HW | 高水位值(High watermark)。这是控制消费者可读取消息范围的重要字段。一 个普通消费者只能“看到”Leader 副本上介于 Log Start Offset 和 HW(不含)之间的 所有消息。水位以上的消息是对消费者不可见的。 |
| AR | Assigned Replicas。AR 是主题被创建后,分区创建时被分配的副本集合,副本个数由副本因子决定。 |
| ISR | In-Sync Replicas。Kafka 中特别重要的概念,指代的是 AR 中那些与 Leader 保持同步的副本集合。在 AR 中的副本可能不在 ISR 中,但 Leader 副本天然就包含在 ISR 中。 |
|
|
ISR中的Leader是由Controller指定,与Leader保持同步用指标来衡量就是follower中LEO落后leader中LEO的时间不超过指定时间范围(replica.lag.time.max.ms=10s)。
(在旧版本中还有另外一个指标是落后的LEO条数,不过这样子的话每次发送大量数据后,一开始ISR就只有leader,到后面follower跟上的才能加入ISR,这样子会导致ZK的频繁写入修改性能下降)
另外在Leader挂掉后,Controller会让ISR中的一个Follower成为Leader,并且开始同步新的Leader的Offset。这里要注意的是有可能此时ISR中并没有Follower,所以有两种选择,①允许OSR的Follower成为Leader和②该分区没有Leader。这来源于设置unclean.leader.election.enable,设置为true为选择①,保证了系统的高可用性和损失了一致性,设置为false为选择②,保证系统的一致性和损失高可用性。
同时一个Leader和多个Follower看上是读写分离的结构,但是Kafka并不支持读写分离。原因由两点,①场景不合适,读写分离适用于读负载很大,而写操作不频繁的场景,显然Kafka不是;②同步机制,Follower和Leader之间存在不一致的窗口,很可能出现消息滞后(类似于幻读)
这主要决定了Producer发送信息时,Kafka的接受机制,有三种:
| ack = 0 | at most once,最多一次语义,Producer不需要等待Broker回发确认消息,直接发送下一批消息。 |
| ack = 1 | at least onve,最少一次语义,Producer只要Leader成功消息并且返回确认后,就可以发送下一批消息 |
| ack = -1 | Producer需要等到Leader和ISR中的Follower同步完成并且返回确认后,才能发送下一批消息 |
那么问题就来,怎么实现Exactly Once呢?
|
这里讨论的Exactly Once主要是针对Producer端,至于消费者的Exactly Once可以在客户端上保留偏移量来实现(参见flink事务机制)。
|
先来讨论单Session的情况,在Kafka中给每个Producer都分配了一个内部的唯一的PID,每次Producer发送信息时,带有的主键是<PID ,Topic,Partition,SequenceNumber>,Leader端收到信息后对相同的<PID,Topic,Partition>的SequenceNumber进行比较,如果来的信息比Leader端的小,证明数据重复,丢弃该条信息;如果来的信息比Leader端的大1,插入该信息;吐过来的信息比Leader端的大超过1,证明发生了乱序丢弃该信息。
|
具体内容参考这篇博客
在单Session的情况如果存在PID都可以保证Exactly Once,那么要是在不同的Session中我能拿到相同的PID就可以了。所以引入了一个TID(自己定义的)并且绑定了事务一开始的PID,只要事务没有提交,那么每次都拿着这个TID去获取对应的PID就可以保证Exactly Once了。
内部引入了一个Transaction Coordinator用于分配PID和管理事务,并且在内置了一个主题Transaction Log用于记录事务信息,事务的操作简图如下:
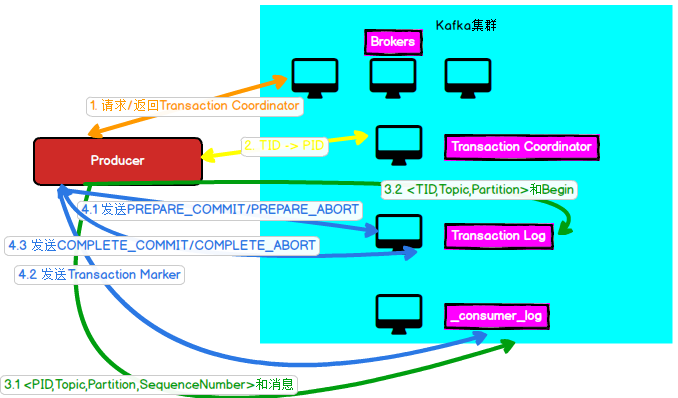
| 1.请求/返回Transaction Coordinator | 由于Transaction Coordinator是分配PID和管理事务的核心,因此Producer要做的第一件事情就是通过向任意一个Broker发送FindCoordinator请求找到Transaction Coordinator的位置。 |
| 2.TID->PID | 找到Transaction Coordinator后,具有幂等特性的Producer必须发起InitPidRequest请求以获取PID。 |
| 3 Producer生产消息 | ①Producer拿到PID后向Kafka主题发送消息 ②Transaction Coordinator会将该<Transaction, Topic, Partition>存于Transaction Log内,并将其状态置为BEGIN |
| 4 事务完成 | ①将PREPARE_COMMIT或PREPARE_ABORT消息写入Transaction Log。 ②以Transaction Marker的形式将COMMIT或ABORT信息写入用户数据日志以及_consumer_log中。 ③最后将COMPLETE_COMMIT或COMPLETE_ABORT信息写入Transaction Log中。 |
Kafka事务机制中,PREPARE时即要指明是PREPARE_COMMIT还是PREPARE_ABORT,并且只须在Transaction Log中标记即可,无须其它组件参与。而两阶段提交的PREPARE需要发送给所有的分布式事务参与方,并且事务参与方需要尽可能准备好,并根据准备情况返回Prepared或Non-Prepared状态给事务管理器。
Kafka事务中,一但发起PREPARE_COMMIT或PREPARE_ABORT,则确定该事务最终的结果应该是被COMMIT或ABORT。而分布式事务中,PREPARE后由各事务参与方返回状态,只有所有参与方均返回Prepared状态才会真正执行COMMIT,否则执行ROLLBACK
Kafka事务机制中,某几个Partition在COMMIT或ABORT过程中变为不可用,只影响该Partition不影响其它Partition。两阶段提交中,若唯一收到COMMIT命令参与者Crash,其它事务参与方无法判断事务状态从而使得整个事务阻塞
Kafka事务机制引入事务超时机制,有效避免了挂起的事务影响其它事务的问题
Kafka事务机制中存在多个Transaction Coordinator实例,而分布式事务中只有一个事务管理器
__EOF__

本文作者:SexCode
本文链接:https://www.cnblogs.com/ginkgo-/p/14936359.html