
Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例
目录
简介
读写文件
DF的选择
选择列数据
选择行数据
同时选择行和列
使用plots作图
使用现有的列创建新的列
进行统计
DF重组
简介
今天我们会讲解一下Pandas的高级教程,包括读写文件、选取子集和图形表示等。
读写文件
数据处理的一个关键步骤就是读取文件进行分析,然后将分析处理结果再次写入文件。
Pandas支持多种文件格式的读取和写入:
In [108]: pd.read_ read_clipboard() read_excel() read_fwf() read_hdf() read_json read_parquet read_sas read_sql_query read_stata read_csv read_feather() read_gbq() read_html read_msgpack read_pickle read_sql read_sql_table read_table

接下来我们会以Pandas官网提供的Titanic.csv为例来讲解Pandas的使用。
Titanic.csv提供了800多个泰坦利特号上乘客的信息,是一个891 rows x 12 columns的矩阵。
我们使用Pandas来读取这个csv:
In [5]: titanic=pd.read_csv("titanic.csv")read_csv方法会将csv文件转换成为pandas 的DataFrame。
默认情况下我们直接使用DF变量,会默认展示前5行和后5行数据:
In [3]: titanicOut[3]: PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S.. ... ... ... ... ... ... ... ... ... ... ...886 887 0 2 Montvila, Rev. Juozas male ... 0 211536 13.0000 NaN S887 888 1 1 Graham, Miss. Margaret Edith female ... 0 112053 30.0000 B42 S888 889 0 3 Johnston, Miss. Catherine Helen "Carrie" female ... 2 W./C. 6607 23.4500 NaN S889 890 1 1 Behr, Mr. Karl Howell male ... 0 111369 30.0000 C148 C890 891 0 3 Dooley, Mr. Patrick male ... 0 370376 7.7500 NaN Q[891 rows x 12 columns]
可以使用head(n)和tail(n)来指定特定的行数:
In [4]: titanic.head(8)Out[4]: PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S5 6 0 3 Moran, Mr. James male ... 0 330877 8.4583 NaN Q6 7 0 1 McCarthy, Mr. Timothy J male ... 0 17463 51.8625 E46 S7 8 0 3 Palsson, Master. Gosta Leonard male ... 1 349909 21.0750 NaN S[8 rows x 12 columns]
使用dtypes可以查看每一列的数据类型:
In [5]: titanic.dtypesOut[5]: PassengerId int64Survived int64Pclass int64Name objectSex objectAge float64SibSp int64Parch int64Ticket objectFare float64Cabin objectEmbarked objectdtype: object
使用to_excel可以将DF转换为excel文件,使用read_excel可以再次读取excel文件:
In [11]: titanic.to_excel('titanic.xlsx', sheet_name='passengers', index=False)
In [12]: titanic = pd.read_excel('titanic.xlsx', sheet_name='passengers')使用info()可以来对DF进行一个初步的统计:
In [14]: titanic.info() <class 'pandas.core.frame.DataFrame'>RangeIndex: 891 entries, 0 to 890Data columns (total 12 columns):PassengerId 891 non-null int64Survived 891 non-null int64Pclass 891 non-null int64Name 891 non-null objectSex 891 non-null objectAge 714 non-null float64SibSp 891 non-null int64Parch 891 non-null int64Ticket 891 non-null objectFare 891 non-null float64Cabin 204 non-null objectEmbarked 889 non-null objectdtypes: float64(2), int64(5), object(5)memory usage: 83.6+ KB
DF的选择
选择列数据
DF的head或者tail方法只能显示所有的列数据,下面的方法可以选择特定的列数据。

In [15]: ages = titanic["Age"]In [16]: ages.head()Out[16]:0 22.01 38.02 26.03 35.04 35.0Name: Age, dtype: float64
每一列都是一个Series:
In [6]: type(titanic["Age"])Out[6]: pandas.core.series.SeriesIn [7]: titanic["Age"].shapeOut[7]: (891,)
还可以多选:
In [8]: age_sex = titanic[["Age", "Sex"]]In [9]: age_sex.head()Out[9]: Age Sex0 22.0 male1 38.0 female2 26.0 female3 35.0 female4 35.0 male
如果选择多列的话,返回的结果就是一个DF类型:
In [10]: type(titanic[["Age", "Sex"]])Out[10]: pandas.core.frame.DataFrameIn [11]: titanic[["Age", "Sex"]].shapeOut[11]: (891, 2)
选择行数据
上面我们讲到了怎么选择列数据,下面我们来看看怎么选择行数据:
选择客户年龄大于35岁的:
In [12]: above_35 = titanic[titanic["Age"] > 35]In [13]: above_35.head()Out[13]: PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C6 7 0 1 McCarthy, Mr. Timothy J male ... 0 17463 51.8625 E46 S11 12 1 1 Bonnell, Miss. Elizabeth female ... 0 113783 26.5500 C103 S13 14 0 3 Andersson, Mr. Anders Johan male ... 5 347082 31.2750 NaN S15 16 1 2 Hewlett, Mrs. (Mary D Kingcome) female ... 0 248706 16.0000 NaN S[5 rows x 12 columns]
使用isin选择Pclass在2和3的所有客户:
In [16]: class_23 = titanic[titanic["Pclass"].isin([2, 3])]In [17]: class_23.head()Out[17]: PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S5 6 0 3 Moran, Mr. James male NaN 0 0 330877 8.4583 NaN Q7 8 0 3 Palsson, Master. Gosta Leonard male 2.0 3 1 349909 21.0750 NaN S
上面的isin等于:
In [18]: class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
筛选Age不是空的:
In [20]: age_no_na = titanic[titanic["Age"].notna()]In [21]: age_no_na.head()Out[21]: PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S[5 rows x 12 columns]
同时选择行和列

我们可以同时选择行和列。
使用loc和iloc可以进行行和列的选择,他们两者的区别是loc是使用名字进行选择,iloc是使用数字进行选择。
选择age>35的乘客名:
In [23]: adult_names = titanic.loc[titanic["Age"] > 35, "Name"]In [24]: adult_names.head()Out[24]: 1 Cumings, Mrs. John Bradley (Florence Briggs Th...6 McCarthy, Mr. Timothy J11 Bonnell, Miss. Elizabeth13 Andersson, Mr. Anders Johan15 Hewlett, Mrs. (Mary D Kingcome) Name: Name, dtype: object
loc中第一个值表示行选择,第二个值表示列选择。
使用iloc进行选择:
In [25]: titanic.iloc[9:25, 2:5]Out[25]: Pclass Name Sex9 2 Nasser, Mrs. Nicholas (Adele Achem) female10 3 Sandstrom, Miss. Marguerite Rut female11 1 Bonnell, Miss. Elizabeth female12 3 Saundercock, Mr. William Henry male13 3 Andersson, Mr. Anders Johan male.. ... ... ...20 2 Fynney, Mr. Joseph J male21 2 Beesley, Mr. Lawrence male22 3 McGowan, Miss. Anna "Annie" female23 1 Sloper, Mr. William Thompson male24 3 Palsson, Miss. Torborg Danira female[16 rows x 3 columns]
使用plots作图
怎么将DF转换成为多样化的图形展示呢?
要想在命令行中使用matplotlib作图,那么需要启动ipython的QT环境:
ipython qtconsole --pylab=inline
直接使用plot来展示一下上面我们读取的乘客信息:
import matplotlib.pyplot as pltimport pandas as pd
titanic = pd.read_excel('titanic.xlsx', sheet_name='passengers')
titanic.plot()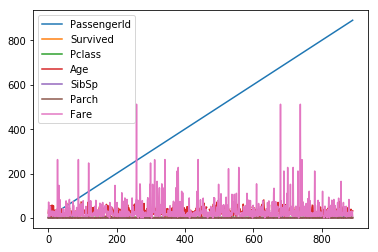
横坐标就是DF中的index,列坐标是各个列的名字。注意上面的列只展示的是数值类型的。
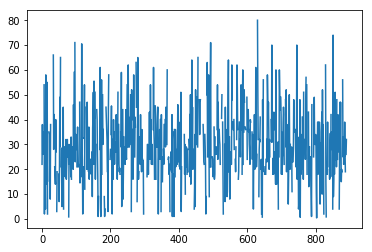
我们只展示age信息:
titanic['Age'].plot()
默认的是柱状图,我们可以转换图形的形式,比如点图:
titanic.plot.scatter(x="PassengerId",y="Age", alpha=0.5)
选择数据中的PassengerId作为x轴,age作为y轴:
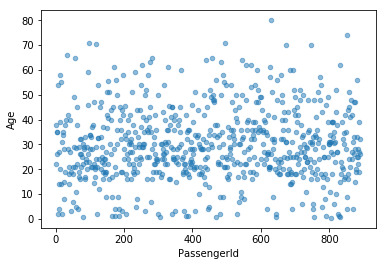
除了散点图,还支持很多其他的图像:
[method_name for method_name in dir(titanic.plot) if not method_name.startswith("_")]
Out[11]:
['area', 'bar', 'barh', 'box', 'density', 'hexbin', 'hist', 'kde', 'line', 'pie', 'scatter']再看一个box图:
titanic['Age'].plot.box()
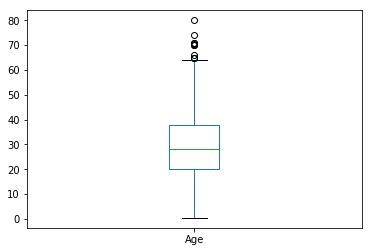
可以看到,乘客的年龄大多集中在20-40岁之间。
还可以将选择的多列分别作图展示:
titanic.plot.area(figsize=(12, 4), subplots=True)
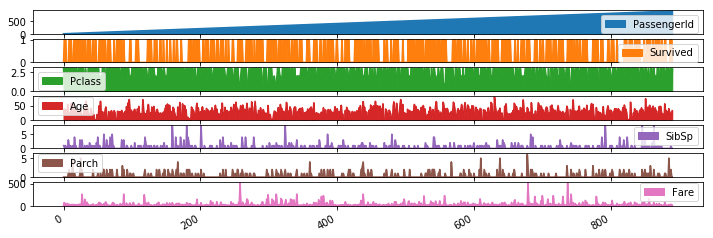
指定特定的列:
titanic[['Age','Pclass']].plot.area(figsize=(12, 4), subplots=True)
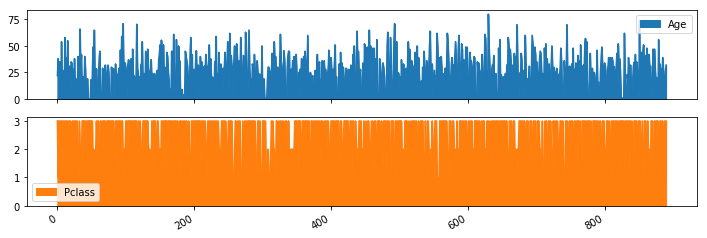
还可以先画图,然后填充:
fig, axs = plt.subplots(figsize=(12, 4));
先画一个空的图,然后对其进行填充:
titanic['Age'].plot.area(ax=axs);axs.set_ylabel("Age");fig
使用现有的列创建新的列

有时候,我们需要对现有的列进行变换,以得到新的列,比如我们想添加一个Age2列,它的值是Age列+10,则可以这样:
titanic["Age2"]=titanic["Age"]+10;titanic[["Age","Age2"]].head()Out[34]: Age Age20 22.0 32.01 38.0 48.02 26.0 36.03 35.0 45.04 35.0 45.0
还可以对列进行重命名:
titanic_renamed = titanic.rename(
...: columns={"Age": "Age2",
...: "Pclass": "Pclas2"})列名转换为小写:
titanic_renamed = titanic_renamed.rename(columns=str.lower)
进行统计
我们来统计下乘客的平均年龄:
titanic["Age"].mean()Out[35]: 29.69911764705882
选择中位数:
titanic[["Age", "Fare"]].median()Out[36]: Age 28.0000Fare 14.4542dtype: float64
更多信息:
titanic[["Age", "Fare"]].describe()Out[37]: Age Farecount 714.000000 891.000000mean 29.699118 32.204208std 14.526497 49.693429min 0.420000 0.00000025% 20.125000 7.91040050% 28.000000 14.45420075% 38.000000 31.000000max 80.000000 512.329200
使用agg指定特定的聚合方法:
titanic.agg({'Age': ['min', 'max', 'median', 'skew'],'Fare': ['min', 'max', 'median', 'mean']})
Out[38]:
Age Faremax 80.000000 512.329200mean NaN 32.204208median 28.000000 14.454200min 0.420000 0.000000skew 0.389108 NaN可以使用groupby:
titanic[["Sex", "Age"]].groupby("Sex").mean()Out[39]:
AgeSex female 27.915709male 30.726645groupby所有的列:
titanic.groupby("Sex").mean()Out[40]:
PassengerId Survived Pclass Age SibSp Parch
Sex female 431.028662 0.742038 2.159236 27.915709 0.694268 0.649682 male 454.147314 0.188908 2.389948 30.726645 0.429809 0.235702groupby之后还可以选择特定的列:
titanic.groupby("Sex")["Age"].mean()Out[41]:
Sexfemale 27.915709male 30.726645Name: Age, dtype: float64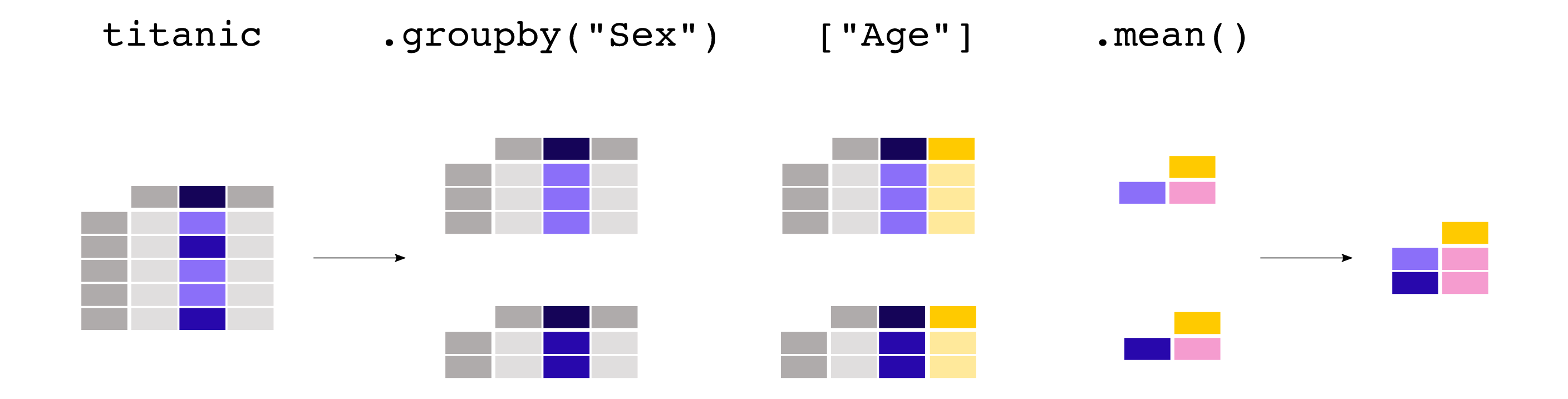
可以分类进行count:
titanic["Pclass"].value_counts()Out[42]: 3 4911 2162 184Name: Pclass, dtype: int64
上面等同于:
titanic.groupby("Pclass")["Pclass"].count()DF重组
可以根据某列进行排序:
titanic.sort_values(by="Age").head()Out[43]: PassengerId Survived Pclass Name Sex \803 804 1 3 Thomas, Master. Assad Alexander male 755 756 1 2 Hamalainen, Master. Viljo male 644 645 1 3 Baclini, Miss. Eugenie female 469 470 1 3 Baclini, Miss. Helene Barbara female 78 79 1 2 Caldwell, Master. Alden Gates male
根据多列排序:
titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head()Out[44]: PassengerId Survived Pclass Name Sex Age \851 852 0 3 Svensson, Mr. Johan male 74.0 116 117 0 3 Connors, Mr. Patrick male 70.5 280 281 0 3 Duane, Mr. Frank male 65.0 483 484 1 3 Turkula, Mrs. (Hedwig) female 63.0 326 327 0 3 Nysveen, Mr. Johan Hansen male 61.0
选择特定的行和列数据,下面的例子我们将会选择性别为女性的部分数据:
female=titanic[titanic['Sex']=='female']female_subset=female[["Age","Pclass","PassengerId","Survived"]].sort_values(["Pclass"]).groupby(["Pclass"]).head(2)female_subsetOut[58]: Age Pclass PassengerId Survived1 38.0 1 2 1356 22.0 1 357 1726 30.0 2 727 1443 28.0 2 444 1855 18.0 3 856 1654 18.0 3 655 0
使用pivot可以进行轴的转换:
female_subset.pivot(columns="Pclass", values="Age")Out[62]: Pclass 1 2 31 38.0 NaN NaN356 22.0 NaN NaN443 NaN 28.0 NaN654 NaN NaN 18.0726 NaN 30.0 NaN855 NaN NaN 18.0female_subset.pivot(columns="Pclass", values="Age").plot()

本文已收录于 http://www.flydean.com/02-python-pandas-advanced/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
来源https://www.cnblogs.com/flydean/p/14857480.html