
netty 的流量整形深度探险
netty 的流量整形深度探险
阅读目录
重点摘要
TrafficCounter 难点分析
TrafficCounter 的变量
TrafficCounter 的重要方法
TrafficCounter的超级难点
重点摘要
netty通过AbstractTrafficShapingHandler 即TSH 来实现限流的基本框架,它的流量整形的具体作用是? 分析已经有同行做了,而且分析的非常好,这里做些摘要(https://www.jianshu.com/p/bea1b4ea8402):
AbstractTrafficShapingHandler 的3大实现:
分别是,GlobalTrafficShapingHandler、ChannelTrafficShapingHandler、GlobalChannelTrafficShapingHandler,其中ChannelTrafficShapingHandler最好理解,它是对单个通道进行限制;而 GlobalTrafficShapingHandler 是全局流量整形,也就是说它限制了全局的带宽,无论开启了几个channel。但Global 并不是对本地所有的channel 的总流量进行限流,而是仅仅maxGlobalWriteSize GlobalTrafficShapingHandler 对全局的channel 采取一致的 速度控制, 并不是 总共的大小,进行控制。 GlobalChannelTrafficShapingHandler 最难理解, 它其是对GlobalTrafficShapingHandler做了优化,使得等待时间更加平衡,这里暂时不展开。
重点难点:
channelRead 是关键, 其作用就是在每次读到数据的时候计算其大小,然后判断是否超出限制,超出则等待一会(但不能超过最大值),否则就直接读
ReopenReadTimerTask 是重启读操作的定时任务。它在读的时候,如果需要等待则设置为channel 的属性,同时提交 该定时任务 到ctx.executor
write 方法作用类似channelRead ,其作用就是在每次准备写数据的时候计算其大小,然后判断是否超出限制,超出则等待一会(但不能超过最大值),否则就直接写
TrafficCounter 难点分析
TrafficCounter 是流量计数器,也是很关键、很重要的东西,源码不难看懂,不过,也不是很容易。那个博客基本上已经很清楚了,但是 还是好几个关键点没有说明白!
Counts the number of read and written bytes for rate-limiting traffic. It computes the statistics for both inbound and outbound traffic periodically at the given checkInterval, and calls the AbstractTrafficShapingHandler.doAccounting(TrafficCounter) method back. If the checkInterval is 0, no accounting will be done and statistics will only be computed at each receive or write operation.
Counts the number of read and written bytes for rate-limiting traffic.
It computes the statistics for both inbound and outbound traffic periodically at the given checkInterval, and calls the AbstractTrafficShapingHandler.doAccounting(TrafficCounter) method back. If the checkInterval is 0, no accounting will be done and statistics will only be computed at each receive or write operation.
意思是 计算被限制流量的read和written 的字节,它周期性的统计进、出的流量,周期是checkInterval,然后回调AbstractTrafficShapingHandler.doAccounting(TrafficCounter) 方法。 如果checkInterval是0, 那么不进行accounting ,而是只统计每次 receive 或者 write 。单单是看这个,肯定是理解不了的, 也记不住。需要仔细研究一下源码。
TrafficCounter 的变量
TrafficCounter 的方法有很多变量。一个变量可以理解,但是为什么这么多啊! 初看还是比较难懂的。其中checkInterval 一般是很少改动的,在构造函数中确定, 是executor.scheduleAtFixedRate 的参数。
其实很有规律,其中很多last开头的变量,只在 resetAccounting方法被写,也就是被改变:
last 开头的几个变量,都在这个方法中被重置
首先, lastTime 也被重置为当前时间, 基本上就是一个窗口过去,就修改它,所以lastTime 可以理解为就是上个窗口的终点,或当前窗口的起点!它跟读写无关!
然后
lastReadBytes lastWrittenBytes 是上个时间窗口的读、写到的数据总和;—— 指用户发出的动作,但实际可能会被封装为一个延迟任务!
lastReadThroughput lastWriteThroughput 是使用秒作为单位,所以乘以1000,表示 读或写吞吐量 xx 字节/秒
realWriteThroughput 是上个时间窗口实际发生的写的数据总和
lastWritingTime 是上一次写的时间; lastWritingTime 是lastWritingTime writingTime中取较大者, 也就是较新的一个时间 ,lastReadingTime 类似。从Math.max(lastWritingTime, writingTime)来看, 不好理解,因为是自己和 上次写writingTime 取max,所以 lastWritingTime肯定是越来越大
一般情况下,应该都是 这行代码执行完后, lastWritingTime = writingTime;
任意时刻下,因为writingTime 任何情况下,不可能变小,应该应该有: lastWritingTime <= writingTime;
lastReadingTime 也是同理。
lastTime 是重置为 入参,resetAccounting方法是 lastTime 唯一修改的地方。
除了last 开头的几个变量,重置的部分还有 current 开头的变量,包括currentReadBytes currentWrittenBytes 被置为0, 还有 realWrittenBytes
修改的部分 lastReadBytes lastWrittenBytes 平时都是不变的,当前方法会进行赋值,值来源正是currentReadBytes currentWrittenBytes ,即是 当前上个窗口时间内已经完成读写的部分,lastWriteThroughput lastWriteThroughput 也是平时都是不变,当前方法会进行计算
累加的部分是 realWriteThroughput ,通过 realWrittenBytes 计算而得
readingTime在每次 readTimeToWait 方法 准确说是 读操作 AbstractTrafficShapingHandler.channelRead 的时候更新,writingTime 类似
currentReadBytes 也是
writingTime readingTime 分别在每次进行写或者读的时候进行更新,但是 需要特别注意的是, 它表示的是 写或者读动作完成的时间, 而不是开始的时间!(除非超过了最大等待时间即 maxTime),所以它可能是未来的时间! ( lastWritingTime 也可能是未来的时间!)
其他时候只会被读。
TrafficCounter 的重要方法
resetAccounting 方法
resetAccounting 是Reset the accounting on Read and Write. 有一个参数是newLastTime 是说我们应该考虑进行更新的时间。其实是重置,就是把所有last开头的变量 置为原始状态,或者进行了累加。io.netty.handler.traffic.TrafficCounter#start 的时候,启动一个定时任务:TrafficMonitoringTask ,每隔固定时间执行:scheduleAtFixedRate,—— 这个非常重要,它就相当于实现了一个时间窗口。一定要理解。

/**
* Reset the accounting on Read and Write.
*
* @param newLastTime the milliseconds unix timestamp that we should be considered up-to-date for. */synchronized void resetAccounting(long newLastTime) { //interval为什么每次要重新计算?看起来它是固定的,其实不一定,因为我们是固定时间间隔,所以可能会因为具体定时任务稍微单位几个毫秒
long interval = newLastTime - lastTime.getAndSet(newLastTime); if (interval == 0) { // nothing to do
return;
} if (logger.isDebugEnabled() && interval > checkInterval() << 1) {
logger.debug("Acct schedule not ok: " + interval + " > 2*" + checkInterval() + " from " + name);
}
lastReadBytes = currentReadBytes.getAndSet(0);
lastWrittenBytes = currentWrittenBytes.getAndSet(0);
lastReadThroughput = lastReadBytes * 1000 / interval;// lastReadThroughput 是使用秒作为单位 // nb byte / checkInterval in ms * 1000 (1s)
lastWriteThroughput = lastWrittenBytes * 1000 / interval; // nb byte / checkInterval in ms * 1000 (1s)
realWriteThroughput = realWrittenBytes.getAndSet(0) * 1000 / interval;
lastWritingTime = Math.max(lastWritingTime, writingTime);
lastReadingTime = Math.max(lastReadingTime, readingTime);
}
writeTimeToWait方法
以写为例,我们看io.netty.handler.traffic.TrafficCounter#writeTimeToWait(long, long, long, long),我们看到 里面很多个if else, 只要size == 0 || limitTraffic == 0,那么writingTime 必然会被更新一次。 其中的代码 其实还是比较难理解的。
记上一次写的时间戳(特指 写操作实际完成的时间!),即writingTime,缩写为w,分下面几个情况 分析:
1、小于当前窗口的起点:
即w < c2,比如w=w2,那么lastWritingTime<=writingTime<=w2,因为w2-c2<0, 所以postDelay=0, lastWrittenBytes是整个window2窗口写的数据之和; 进一步,如果w小于上一个窗口的起点,即如果w < c1,比如w=w1, 则lastWrittenBytes必然是0
2、大于当前窗口的起点,但小于当前时间:
即c2<w<now ,分两组情况:
a、 lastWritingTime<=c2 。比如w=w3,那么writingTime是w3,但 lastWritingTime还是w2; 因为w2-c2<0, 所以postDelay=0, 同样lastWrittenBytes是整个window2窗口写的数据之和
b、 lastWritingTime>c2 。比如w=lastWritingTime=w3,那么 w2-c2>0, 所以postDelay>0.
3、大于当前窗口的起点,且大于当前时间:
即c2<now<w ,比如w=w4,那么lastWritingTime是w4;postDelay=w4-c2,同样lastWrittenBytes是整个window2窗口写的数据之和
a、 lastWritingTime<=c2 。比如w=w2, postDelay=0
b、 lastWritingTime>c2 。比如w=w3 或者w=w4, postDelay>0
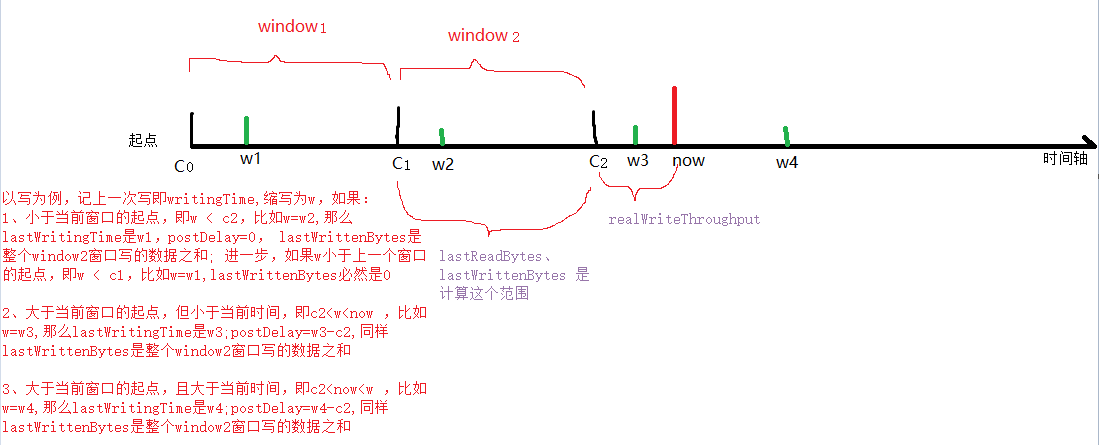
c 0/1/2 表示 定时任务的各个checkpoint 时间点
localWritingTime = writingTime,即上一次写即writingTime,缩写为w,
lastTimeCheck 即上次定时任务的时间点,即图中的c2
interval = now - lastTimeCheck 即当前时间距离上个c 的时间差,也就是当前窗口已经走过的时间!
long pastDelay = Math.max(lastWritingTime- lastTimeCheck, 0); 其实不好理解,因为lastWritingTime 是上一个窗口的最后写时间,和现在的写操作可能隔着好几个写操作呢... pastDelay 的最小值是0, ;如果分拆为两种情况,那么会稍微好理解一点,
lastWritingTime - lastTimeCheck <= 0 是上面分析的 1 , 此时lastWritingTime 位于C2 的左边,pastDelay 为0,
lastWritingTime - lastTimeCheck >0 是上面分析的 2、3, 此时lastWritingTime 位于C2 的右边,pastDelay > 0, 表示上次检查就已经存在的 超出其本身窗口的延迟, 那为什么当前窗口的每一次写 都要去计量它呢? 是lastTimeCheck 可能会发生变化吗? lastTimeCheck 发生变化,只可能是configure() 方法, 这显然不会经常发生。 所以这个可能是 误写的bug吗? 是不是把 lastWritingTime 改成 writingTime 更好?
如果pastDelay 是上次检查就已经存在的 超出其本身窗口的延迟,那么它在整个当前窗口都是固定的!
---- 仔细考虑, 其实没有bug! 因为我们当前计算 写延迟, 是从lastTimeCheck 开始计算的:
long time = sum * 1000 / limitTraffic - interval + pastDelay;
这行代码,sum 是计算当前窗口的所有写数据大小,乘以 1000 是因为limitTraffic 的单位是秒,需要转为毫秒;
limitTraffic 就是限制的速度
interval 是当前窗口已经走过的时间!
pastDelay 是上个窗口(准确说是 之前所有的窗口的)的留下的延迟, 是不能不考虑的
总体就是
当前窗口所有写操作的需要的总的延迟 = 计算当前窗口的已经执行的写的总流量 / 当前窗口已经走过的时间 + 之前所有写的留下的延迟
换句话说, time 是当前窗口所有写操作的需要的总的延迟, 它并不是 当次写的需要的延迟了!! 这一点和 Guava 的Ratelimiter 差别非常大!
如果 time > 最小延迟10ms, 那么当前写操作自然需要排队到后面, 从而就应该 返回一个等待时间! 可以想象的是, 如果当前+之前的写操作导致延迟很大,本次写也不得不排在它的后面!
等等, 这里为什么判断 是否大于最小延迟10ms呢? 我猜测是因为,10ms太短,没有使用延迟任务的必要性,直接去阻塞的方式写吧!而且从io.netty.handler.traffic.AbstractTrafficShapingHandler#write 方法看, wait 时间也是需要大于最小延迟10ms! 就是说ctx.write 方法本来是异步式的, 然后写到管道中去,让它去管道中稍微排队一会吧!但是 如果搞成异步任务的话,还需要修改通道的可写兴,即setUserDefinedWritability,然后启动异步检测任务 10ms之内把它改回来,也是挺消耗性能的!大概是因为 不能太频繁,xx也需要一定时间。 实际的真正的写操作其实很快,关键是需要wait时间。
writeTimeToWait 方法的复杂之处在于其中好几个if , interval > 最小延迟10ms 的if 已经说完,else呢? else情况是怎么处理的?仔细看, else情况其实是通过计算当前窗口和上一个窗口的 总流量 / 总时间差 来求得需要的 延迟。我想是因为 如果interval < 10ms 太小,可能计算不准确,干脆拿上个窗口的写流量来一起计算!
TrafficCounter的超级难点
===================== 超级难点 =====================
if (time > maxTime && now + time - localReadingTime > maxTime) {
time = maxTime;
}time > maxTime && now + time - localWritingTime > maxTime 怎么理解?time > maxTime 意思比较直白就是 延迟不能超过了最大延迟, now + time - localWritingTime > maxTime( 记为X),比较难理解。如果不考虑maxTime ,其实X 就是当前写操作应该时间执行的时间点!
now + time - localWritingTime > maxTime ==> time - maxTime > localWritingTime - now
因为time - maxTime > 0, 所以,
如果 localWritingTime - now < 0 , 也就是 上一个写 在当前时间之前 则自动成立;那么如果本次写的总延迟 大于 最大延迟 则重置 延迟为 maxTime
如果 localWritingTime - now > 0, 也就是 上一个写 在当前时间之后,那么需要把 这个时间差计算在内! 也就是如果 延迟 需要大于 最大延迟 + 上一个写在当前时间之后的时间差,则重置 延迟为 maxTime! 比如上一个写 在 1点30分,当前时间是 1点25分,maxTime 是15分钟,那么如果本次写的总延迟为21 > 15 + 5 = 20, 但是因为最大延迟是 15, 所以需要重置 延迟时间为 15,而不能是20! 这个判断,实际上是避免了 过长的等待! 如果本次写的总延迟为17, 那么不会重置, 还是 17分钟!可见, 还是可能出现 延迟大于15分钟的!
从另外角度分析
令
X = now + time - localWritingTime
= now + ( sum * 1000 / limitTraffic - interval + pastDelay )- localWritingTime
= now + ( sum * 1000 / limitTraffic - now + lastTimeCheck + pastDelay )- localWritingTime
= sum * 1000 / limitTraffic + pastDelay + lastTimeCheck - localWritingTime
可见 X 其实跟now 无关,其实就是 当前窗口的所有写延迟 + 之前所有的写延迟 + 上次写实际执行的时间 。注意到lastTime writingTime lastWritingTime 等时间值,包括now,并不是时间戳,而是 System.nanoTime() ,也就是cpu 指纹时间!它们 只能用来计算相对值。(目的是为了 精度?)
lastTimeCheck - localWritingTime 意味着什么?分两种情况来看比较好:
1、如果 lastTimeCheck - localWritingTime > 0, 也就是上一个写的理论上应该实际执行的时间 在当前窗口起点之前, 那么pastDelay = 0,相当于上一个写还在上一个窗口,本窗口没有发生过写,那么它 相当于是pastDelay 的补偿,也就是之前的空闲!
2、如果 lastTimeCheck - localWritingTime <= 0, 也就是上一个写的理论上应该实际执行的时间 在当前窗口起点之后, 那么它就是 上一个写的总的写延迟。
还是不直观,这样考虑:
第一次写的时候肯定是 localWritingTime = init time, 所以 lastTimeCheck - localWritingTime 就是 启动到当前窗口起点的时间差,则 X 就是以当次写的实际执行的时间差; 第二次写的时候 lastTimeCheck - localWritingTime是 第一次写 从当前窗口起点 超出的部分的负数( 可能是正数、也可能负数)也就是上一次的 延迟, 所以X是补偿了上一次写的延迟的 时间差,也就是本次的写的单独计算的 时间延迟!
注意 writeTimeToWait 返回的是从当前时间 开始的延迟!localWritingTime 是上一个写的理论上应该实际执行的时间,时间变量很多, 需要搞清楚哪个是 时间片段或称时间差,哪个是时间点 或称CPU的指纹时间点。
但是注意到因为 pastDelay 只会计算之前的延迟,不会计算之前的 空闲,所以X 意味着考虑之前空闲之后的真正的 延迟!
综上 X = 当前窗口的所有写延迟 + 之前所有的写延迟 + 之前所有的写延迟的误差,X 到底是什么? 其实就是本地写 单独核算需要的延迟!
所以, time > maxTime && X > maxTime 就是意味着,当前总延迟 大于 最大时间,且本次写单独核算的延迟 大于 最大时间!
就是说 如果 总延迟 大于 最大时间, 但是 本次写单独核算的延迟 没有超出,那么 可能需要等待更久,如果本次超出,那么就延迟重置为 最大时间!
writeTimeToWait 方法很复杂,readTimeToWait 稍微简单一点,下文分析!
真是煞费苦心!!!
版权声明
本文原创发表于 博客园,作者为 阿K . 本文欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则视为侵权。
欢迎关注本人微信公众号:觉醒的码农,或者扫码进群:


来源https://www.cnblogs.com/FlyAway2013/p/14824615.html