
【接口测试】数据分离-使用xlsx模块读取Excel文件
【接口测试】数据分离-使用xlsx模块读取Excel文件
数据直接写在代码文件里,不利于修改和构造数据。可使用Excel保存测试数据,实现代码和数据的分离。
新建Excel文件test_user_data.xlsx包含工作簿TestUserReg,并复制到项目根目录下,TestUserReg内容如下:
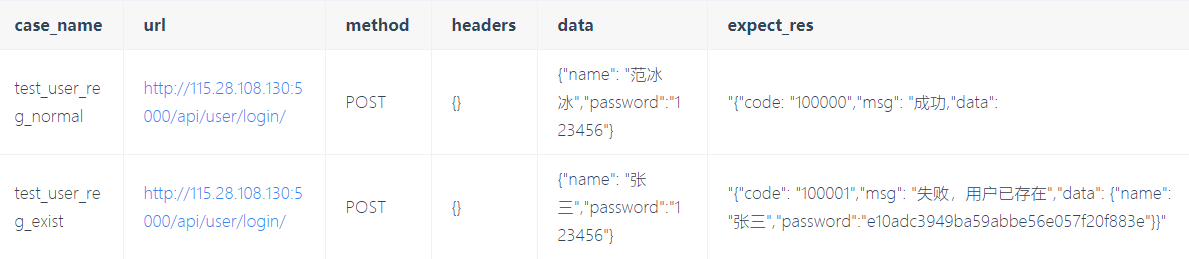
一、Excel读取方法
Python使用第三方库 xlrd 来读取 Excel:

import xlrd
wb = xlrd.open_workbook("test_user_data.xlsx") # 打开excelsh = wb.sheet_by_name("TestUserLogin") # 按工作簿名定位工作表print(sh.nrows) # 有效数据行数print(sh.ncols) # 有效数据列数print(sh.cell(0, 0).value) # 输出第一行第一列的值`case_name`print(sh.row_values(0)) # 输出第1行的所有值(列表格式)# 将数据和标题组装成字典,使数据更清晰# zip()用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。print(dict(zip(sh.row_values(0), sh.row_values(1))))# 遍历excel,打印所有的数据for i in range(sh.nrows): print(sh.row_values(i))
二、封装读取excel操作
新建read_excel.py,目的是获取某条用例的数据,需要3个参数:excel数据文件名(data_file),工作簿名(sheet),用例名(case_name)。
如果只封装一个函数,每次调用(每条用例)都要打开一次excel并遍历一次,这样效率比较低。可以拆分成两个函数:excel_to_list(data_file, sheet),获取一个工作表的所有数据;get_test_data(data_list, case_name)从所有数据中去查找到该条用例的数据。
import xlrddef excel_to_list(data_file, sheet):
data_list = [] # 新建个空列表,来乘装所有的数据
wb = xlrd.open_workbook(data_file) # 打开excel
sh = wb.sheet_by_name(sheet) # 获取工作簿
header = sh.row_values(0) # 获取标题行数据
for i in range(1, sh.nrows): # 跳过标题行,从第二行开始取数据
d = dict(zip(header, sh.row_values(i))) # 将标题和每行数据组装成字典 data_list.append(d) return data_list # 列表嵌套字典格式,每个元素是一个字典def get_test_data(data_list, case_name): for case_data in data_list: if case_name == case_data['case_name']: # 如果字典数据中case_name与参数一致
return case_data # 如果查询不到会返回Noneif __name__ == '__main__': # 测试一下自己的代码
data_list = excel_to_list("test_user_data.xlsx", "TestUserLogin") # 读取excel,TestUserLogin工作簿的所有数据
case_data = get_test_data(data_list, 'test_user_login_normal') # 查找用例'test_user_login_normal'的数据
print(case_data)
三、在用例中调用封装好的方法
test_user_reg.py中代码如下:
import unittestimport requestsfrom db import *from read_excel import *import json # 用来转化excel中的json字符串为字典class TestUserReg(unittest.TestCase):
@classmethod def setUpClass(cls): # 整个测试类只执行一次
cls.data_list = excel_to_list("test_user_data.xlsx", "TestUserReg") # cls.data_list 同 self.data_list 都是该类的公共属性
def test_user_reg_normal(self):
case_data = get_test_data(self.data_list, 'test_user_reg_normal') if not case_data: # 有可能为NONE
print("用例数据不存在")
url = case_data.get('url')
data = json.loads(case_data.get('data')) # 转为字典,需要取里面的name进行数据库检查
expect_res = json.loads(case_data.get('expect_res')) # 转为字典,断言时直接断言两个字典是否相等
name = data.get("name") # 范冰冰
# 环境检查
if check_user(name):
del_user(name) # 发送请求
res = requests.post(url=url, json=data) # 用 data=data 时可以直接传字符串
# 响应断言(整体断言) self.assertDictEqual(res.json(), expect_res) # 数据库断言 self.assertTrue(check_user(name)) # 环境清理(由于注册接口向数据库写入了用户信息) del_user(name)if __name__ == '__main__': # 非必要,用于测试我们的代码
unittest.main(verbosity=2)
四、问题总结
1、使用 xlsx.open_workbook 读取excel数据失败,报错:xlrd.biffh.XLRDError: Excel xlsx file; not supported。
原因:xlrd 为2.0.1版本,更新版本后,xlrd 不支持 xlsx 格式数据的读取了。
解决方法:减低 xlsx 版本:先卸载2.0.1版本,再指定安装1.2.0版本。
2、excel 数据中是纯数字的,读取到的数据是浮点数。
解决方法:在excel文档中,设置单元格格式为文本格式。
3、使用 json.loads 将字符串转化为字典失败,报错:json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes,即期望属性名要用双引号括起来。
原因:json 字符串中的key使用的是单引号,但json.loads()接受的参数并不是直接的一个字典,而需要固定格式的。引号必须为双引号。单引号不行。
解决方法:将单引号修改为双引号。(注意不要是中文的双引号,不然仍会报错)
4、扩展知识:json 模块常用的四个函数
import json json.load() # 将一个存储在文件中的json对象(str)转化为相对应的python对象json.loads() # 将一个json对象(str)转化为相对应的python对象json.dump() # 将python的对象转化为对应的json对象(str),并存放在文件中json.dumps() # 将python的对象转化为对应的json对象(str)
原文地址:https://www.cnblogs.com/superhin/p/10339002.html