
Service Mesh与Istio简述
Service Mesh与Istio简述
前情提要 前段时间去QCon深圳2020大会围观了一下,听了一下大厂们现在在干的事情,后端这一块主流都在讨论云原生,当中美团分享了他们在Service Mesh架构上面的实践,个人觉得挺有价值,写篇博文记录一下
Service Mesh的演化历程
一个服务从项目一开始,通常会是一个简单的单体应用,一个应用提供了所需的所有服务,所有模块都包含在这个应用里面,随着需求的迭代,这个应用的模块数量越来越庞大,功能集成也越来越多,模块与模块之间在应用内强耦合,以致于到后期可能改一个小东西就可能会影响整个应用,导致线上事故
发展到这个阶段,一般就要进行服务拆分了,从业务上进行划分,把完成同类功能的应用放到一组,通常情况下拆分之后业务与业务之间会有相互调用的需求,原先基于单个应用下的模块与模块之间的直接调用现在变成服务与服务之间的RPC调用,基于这个前提,在网络层面就衍生出了几个当前OSI 7层网络模型无法支持的更高维度的问题
服务注册与服务发现
服务之间要实现相互调用,首先必须先找到对方,类似于DNS查找,通过名称查找到具体端点(IP+端口号),所以首先需要一个类似DNS的服务,充当注册中心,功能上面要求一个服务上面或者销毁的时候,注册中心要能够感知到这个事件,以便在第二步:服务发现的时候能够准确拿到可用的目的端点,通常的流程如下所示:
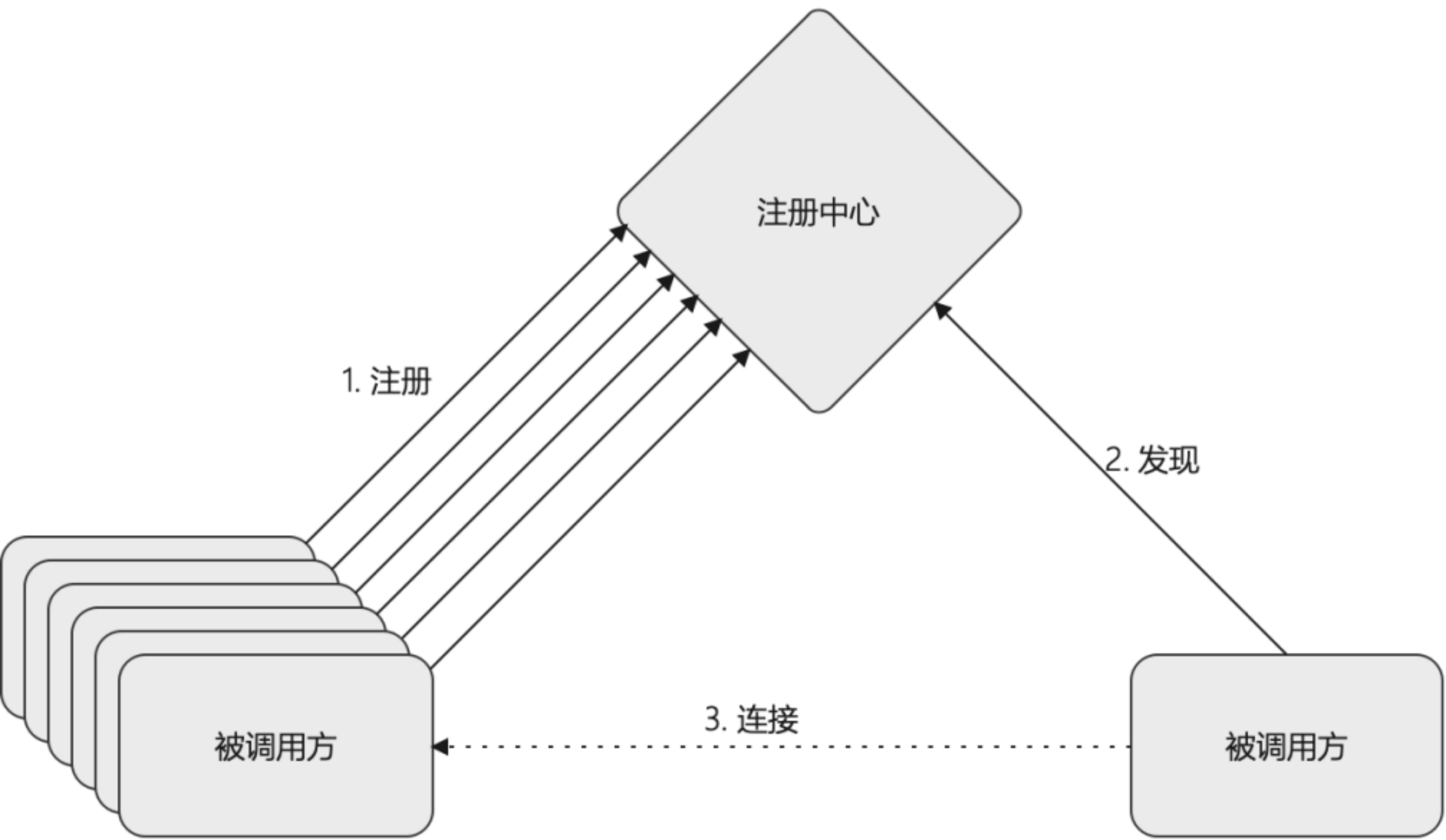
被调方向注册中心注册自己的地址
调用方向注册中心询问被调方的服务地址列表3. 向被调方发起请求最直接的办法,就是搞个DNS服务器,用来充当注册中心,但是DNS通常会有缓存,更新不会实时,而且服务注册除了“注册”这个动作,还需要有“销毁”的动作,否则一个节点挂了,DNS上面还保留着这个节点的信息,调用方发起调用将会失败,总体上DNS并不能完美胜任这种工作,需要想办法另外去解决
负载均衡
上图可以看到,被调方这个服务下可以有多个实例,分布在不同的主机上运行,现实中为了避免单点故障,基本上都会布置多个实例同时提供服务,这就导致调用方拿到的服务地址不是一条,而是一组列表,而怎么样从这组列表中选出一个端点来发起请求呢,这就需要调用方有负载均衡的能力,比如rr轮询,random随机访问呢
熔断限流
微服务的集群下,每个服务负责不同的功能,一条请求进来可能会穿越多个微服务,而如果在这当中,某些微服务出现性能瓶颈,比如一些处理流程比较慢的服务,当并发请求量上来之后,可能就直接被打挂了,而这个服务恰好是一个关键路径,导致前端所有请求都报错,这时候就需要有一种保护机制,能够在适当的时候对某些步骤进行降级操作,比如某个服务达到性能瓶颈之后进行熔断,不让请求进来,服务入口直接拒绝访问,等到这个服务恢复可用的时候再把它加进来
安全
如果在一个不信任的集群中,服务与服务之间可能还需要加密通信,这意味着双方要进行身份认证、密钥交换,身份认证需要一个权威的安全中心来颁发证书,否则可能会有中间人窃听,这些主要看业务需要的安全等级
以上这些问题,统称服务治理,基本上服务治理经过了三个阶段
第一阶段,在应用程序中包含治理逻辑
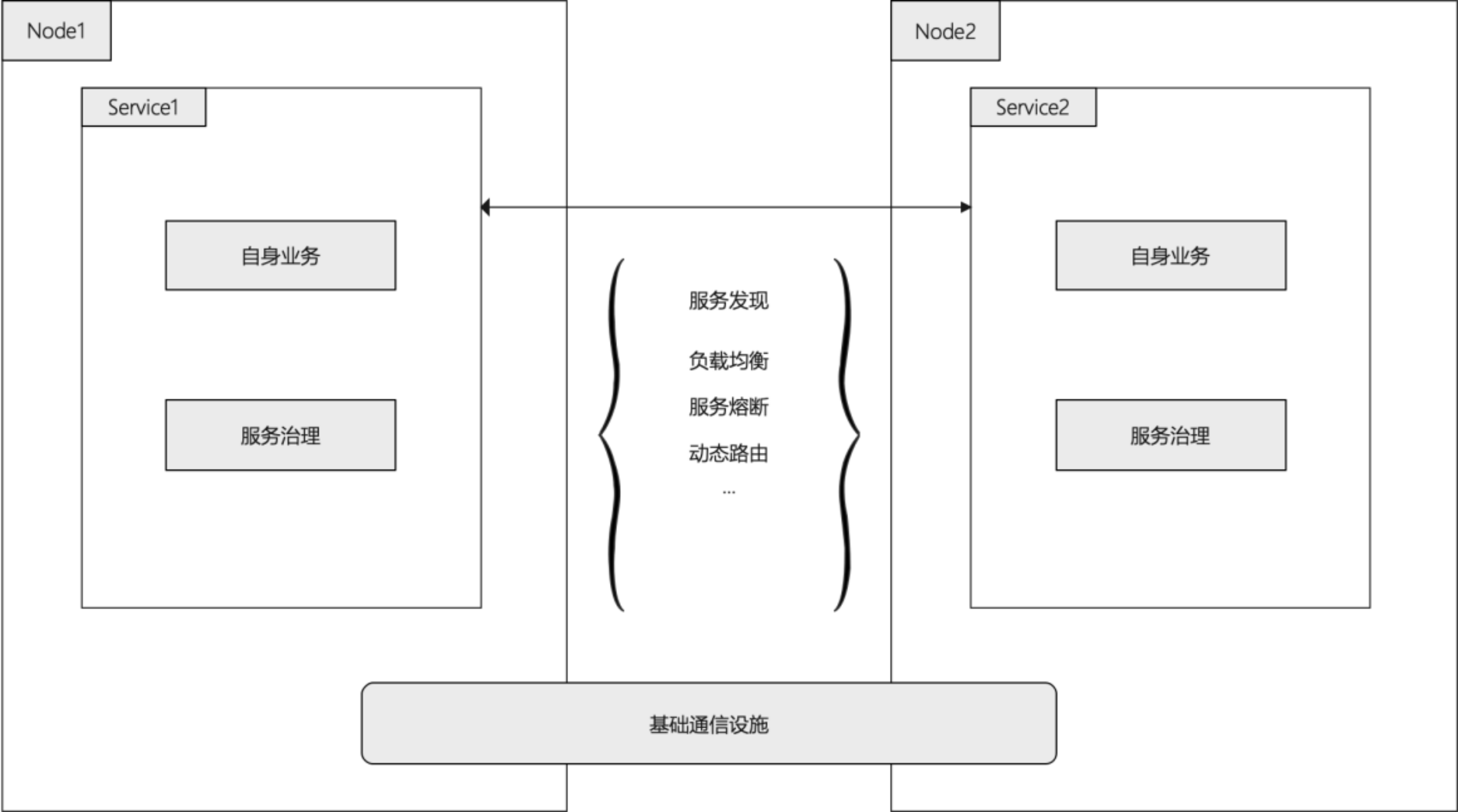
这个阶段,应用本身除了业务代码之外,还加进了治理逻辑部分的代码,应用本身亲自来解决服务发现、负载均衡等等问题,这种方式存在以下问题:
业务代码与治理逻辑强耦合,意味着开发者在实现业务的同时还必须去关心这些治理的问题,无法开发纯粹的业务代码
存在大量重复的代码,集群内的所有服务的业务代码都得实现这样一套治理逻辑,维护困难,搞不好一出bug还得所有服务都得改一遍
第二阶段,独立出治理逻辑SDK
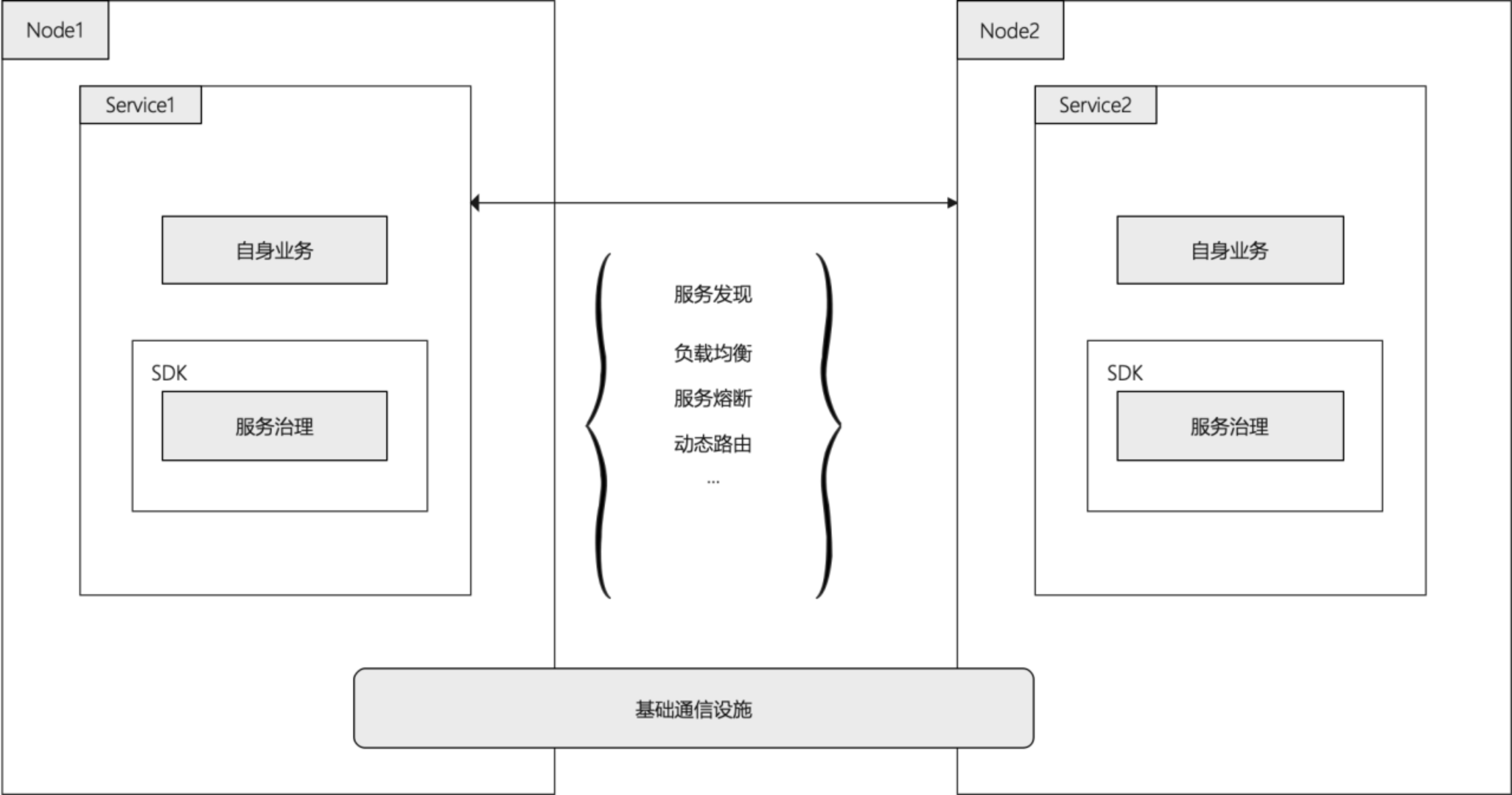
为了解决耦合的问题,业务尝试把这些逻辑抽象出来,独立成一个SDK库,由业务代码去调用,对业务来说相当于一个黑盒子,总体上,代码逻辑上面能够做到业务与治理分离,但是引入SDK又有了新的问题
语言强绑定,SDK需要与语言适配,每种语言都得实现一套相同功能的SDK
SDK版本不易管理,SDK本身也会有升级迭代的过程,而业务开发通常是惰性的,不要指望业务会主动去升级SDK,这就导致集群内会有各种各样版本的SDK,功能不够统一,对SDK维护者来说不好管理
仍然有代码级的侵入,虽然说独立成SDK,但是业务代码本身还需要跟SDK进行适配,这种情况下,服务治理无法完全对业务透明
第三阶段,独立出治理逻辑进程
从第一阶段和第二阶段的经验可以总结出,如果要想让业务玩得爽,必须尽量把服务治理这块逻辑不断地下沉,最好能够实现对业务完全透明,比如说,业务完全不需要加任何特殊逻辑,直接向某个服务名发起http请求,然后获得预期的返回这是最好的
举例来说,就像tcp的发展历程一样,从最早的时候,tcp/ip还没被制定出来,机器与机器之间的连接可能就直接通过一条网络直连(甚至都没有网线这种东西,直接就用一条RS232串口线连接),A机器发出的数据流由B机器直接接收,后来,有了更远距离的通信,网络问题开始浮现出现,比如说数据可能会延迟、可能会丢包、包序可能是乱的,更甚者如果两台机器性能不一致,一端拼命地发数据,一端来不及收数据等等,这时候就需要某种策略来确定来至少解决以下几个问题
双方需要有一个应答逻辑来确定对端到底有没有收到数据
需要有一个超时重启机制来确认网络中有没有发生丢包,不能让人无限等待下去
需要有一个拥塞控制机制,来确认发送方到达能以多大的速度向对方发数据
需要保证数据包顺序
这是不是很像tcp解决的问题?是的,因为这种机器间通信的需求太普遍了,所以制定了tcp/ip协议,把他变成网络通信的基础设施,业务层不再需要亲自去解决这种网络治理问题,这其实就是一种逻辑层次的下沉,业务不断往上层发展,基础设施不断下沉,向上层屏蔽治理的细节
那微服务时代的服务治理逻辑有没有机会下沉成基础设施,让应用层不再需要去关心这些东西呢,目前没有看到OSI 7层模型有继续升高的想法,那就让治理逻辑人为地下沉,尽最大可能地向业务层屏蔽底层细节
这就是第三阶段的发展方向:治理逻辑独立进程

通过把治理逻辑的代码独立出来变成一个进程,负责劫持业务进程的出入流量,并负责实现服务治理逻辑,对业务进程来说,它完全不知道这个治理进程的存在,这个旁路进程就是SideCar,也称为proxy代理
如果我们把集群内的所有proxy管理起来,服务间通信完全由proxy来负责,并有一个控制中心来负责控制这些proxy,实现一张服务治理的网,这种形式就叫Service Mesh 服务网格

Service Mesh解决了以下问题:
对业务层完全透明,感知不到网格的存在
网格上的控制中心和应用节点上的proxy共同完成服务治理:服务注册、服务发现、服务熔断、负载均衡等功能,甚至能够实现动态路由分发、监控、调用链跟踪等高级功能
Istio架构
Istio就是当前Service Mesh形态上比较热门的实现方案,由Google推出,所以Istio能够实现跟K8s深度结合,由于师出同门,所以Istio的路线就是能依赖K8s的功能就尽量复用K8s的,基于K8s的生态去构建一个Service Mesh服务,当然Istio也可以跟基本平台进行结合,只不过跟K8s是配合得最好的,下面是Istio官网首页的图

总结出以下四种功能

流量管理
实现负载均衡,动态路由,同时能够支持灰度发布、故障注入等高级的治理能力
可观察性
接管了应用的流量,那就可以实现对流量的监控,基本访问日志及流量维度的各种监控是基本功能,另外还支持调用链跟踪,Istio可以给流经prox的请求打上span跟踪ID,然后Istio接上一个有跟踪能力的后端比如zipkin啥的,就可以马上实现调用链跟踪,不需要业务层介入开发
策略执行
能够实现熔断限流等访问策略
安全
通信安全
基本上在微服务上面所要解决的关于服务治理的需求,Istio都能够支持
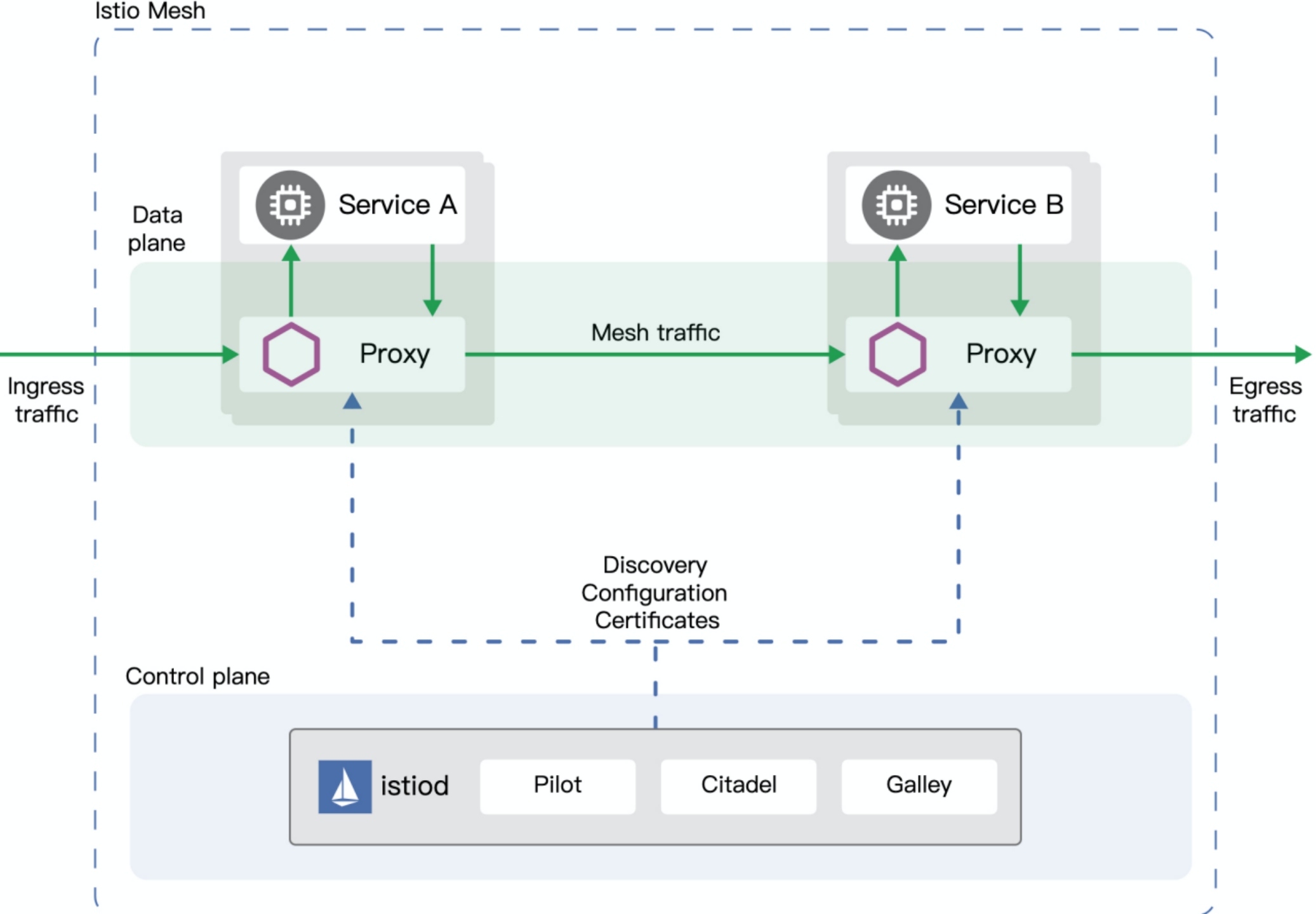
在架构上面,Istio跟K8s一样,分为两层,底层控制面,上层数据面
数据面会在服务创建的时候自动向一个Pod里面注入Istio的prox容器(使用的是Envoy组件),这个注入过程业务层是无感知的,这个Proxy容器会通过iptables转发的办法把出入流量从Pod的业务容器中劫持走
再说控制面,这个是Istio的控制中心,主要由Pilot(控制器),Citadel(负责安全相关的功能)、Galley(负责各种配置)组成,旧版本中还有一个Mixer组件,主要负责遥测采集,proxy会向Mixer上报各种指标,Mixer来控制策略,由于会有性能瓶颈,这个组件在新版Istio中已经被废弃,相关能力下放到数据面的Proxy来完成

对K8s来说,Istio是以插件的形式对K8s的一种功能补齐,K8s本身只实现了运维部署、基本的服务发现等基础层,Istio则是在其之上,业务层之下,处于中间的平台层,实现了以上的服务治理能力
Istio的服务治理规则
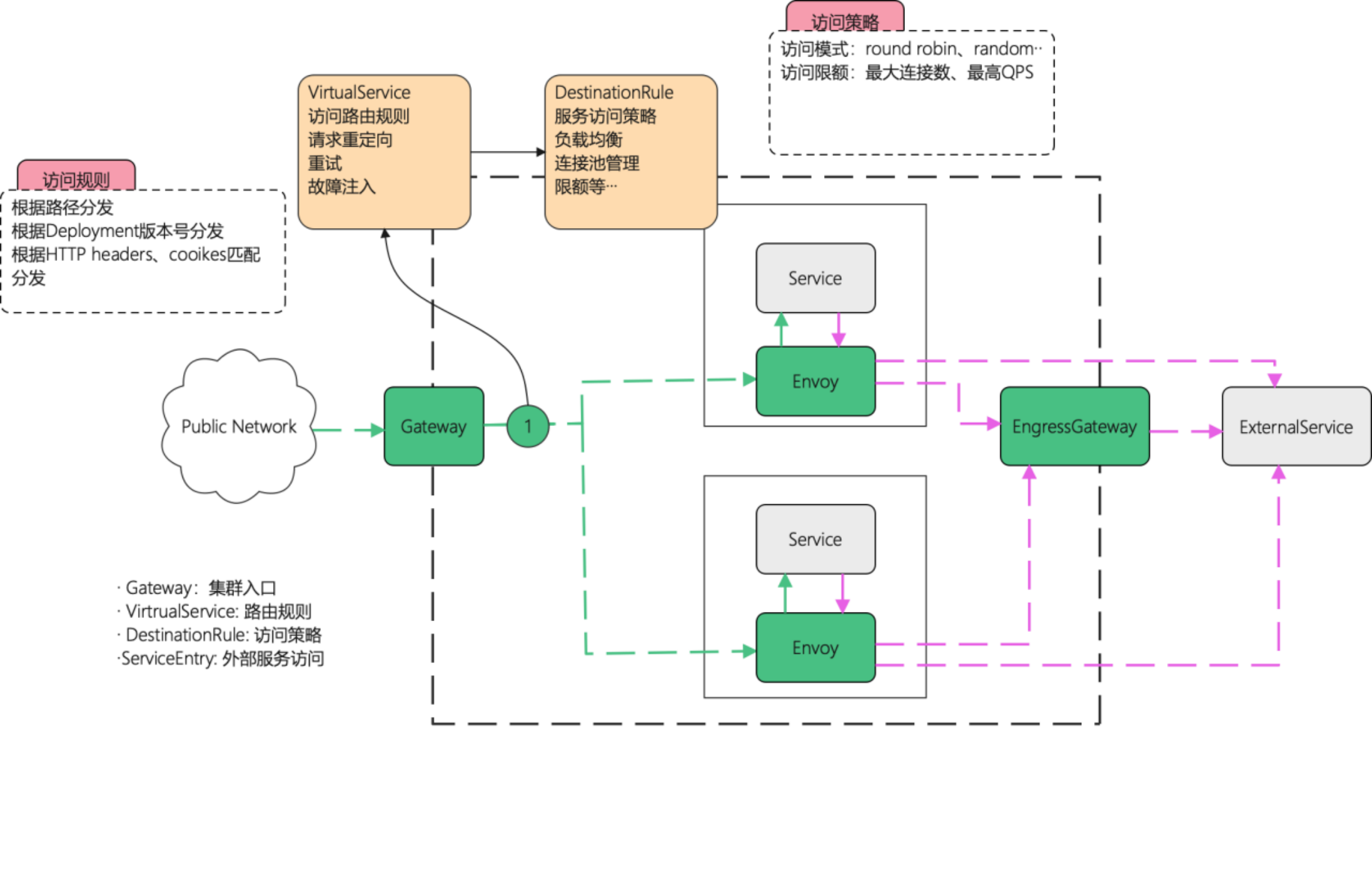
提供了四种逻辑模型
Gateway: 作为一个集群的入口网关,外部流量通过这个网关来访问内部服务
VitualService: 制定路由规则,比如根据路径分发,根据Http cookies匹配分发等,可以理解为Nginx下的server配置,server下你可以有各种location匹配规则
DestinationRule: 访问策略的规则,比如过滤目标节点,设置负载均衡模式等,可以理解为Nginx下的upstream配置,server.location匹配到规则后就会向指定的upstream发起请求,而DestinationRule就相当于upstream下的各种控制规则,比如定义后端服务列表,定义最大连接数等
ServiceEntry,这个是集群内服务请求外部服务的出口网关,当然也可以不用这个东西,直接由Proxy发起连接
以上,基于VitralService+DestinationRule的规则,可以实现各种访问形式,比如蓝绿部署,金丝雀部署,A/B test等
Istio具备监控能力,后端可以接各种监控系统,比如promethus,实现监控告警,而无需业务层介入
Istio的服务发现依赖于K8s,Isito会通过list/wath监听来自KubeAPIServer的事件,所以Istio不需要实现服务注册
最后,最近在看一本华为云出的关于Istio的书,看完到时再续一下更详细的内容,今晚写作的时候被工作打断了,没有思路了,先暂停一下,关于Istio先介绍到这里
学习过程中参考了一些资料如下: Pattern: Service Mesh Istio入门级实训-华为云CloudNative 系列培训课程 《云原生服务网格Istio》