
数据结构与算法---跳跃表
数据结构与算法---跳跃表
前言
最近接触到了跳跃表,感觉很牛x,这不又把《数据结构与算法分析》翻开了,也查了一些资料,这里总结一下自己的理解。
概念及特点
跳跃表是一种分层结构的有序链表,其查找和插入的平均时间复杂都是O(logN)。相比数组插入的时间复杂度O(N)和平衡二叉树
插入过程中为满足平衡而实施复杂旋转操作,跳跃表有很大优势;同时跳跃表在并行计算中也非常有用,因为跳跃表插入是局部的操作,
可以进行并行操作。
原理分析
普通链表的蜕变
如下图(图都是截取自《数据结构与算法分析》,比较粗糙将就着看吧),一个简单的有序链表,查找元素时,只能进行顺序扫描,
其查找时间正比于节点的个数N。

如何加速查询呢?可以通过每隔一个节点有个附加指针指向前两个位置上的节点,这等于在简单链表的基础上创建一层子链表,
这样先遍历上层子链表就可以通过跳跃的方式查找到目标节点的范围,此时最多比较(N/2)+1个节点。

继续扩展,增加跳跃的间距。在上图基础上,每个序号是4的整数倍的节点附加一个指向下一个序号是4的整数倍的节点,
这样只有(N/4)+1节点被比较。

如果扩展到每序号为2i的节点都有附加指针指向下一个序号为2i的节点,如下图,这就得到了一个跳跃表,
这里将有k层子链结构的跳跃表定义为k阶跳跃表。
时间和空间复杂度
由上述跳跃表可以推断出阶数为log(N),从上往下每层遍历都可以看做是二分查找,从而可以得到结论其查找的平均时间复杂度为log(N)。
这个效果是不是跟有序数组根据下标进行二分查找的一样,所以跳跃表的构建思路也可以看做是链表通过附加指针信息构建二分法查找的索引信息。
附加指针增加了内存空间的占用,接下来计算一下跳跃表的空间复杂度。
假设一个N个元素的k阶跳跃表,计算一下指针数量:
已知从上往下,第一阶指针(即最底层)有N个,第二阶指针有N/2个,…第k阶指针(即最顶层)有N/2k节点,即N,N/2,N/22,…,N/2k-1 。
所以这是一个等比数列求和:Sk=N(1-1/2k)/(1-1/2)=2N-1。
相比普通链表,指针占用的空间也就翻了一倍。
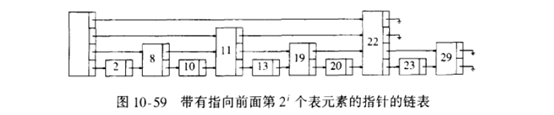
跳跃表的性质:第i阶指针指向前面第2i个节点,同时该节点的阶数k>=i;
从跳跃表的性质可以看出,节点位置和阶数是对应死的。这种数据结构插入元素时,比较死板需要进行大量操作调整保持性质。
可以适当放宽限制,通过随机算法来确定节点的阶数。上述图10-59跳跃表结构,可以看出一阶节点(即只有一个指针指向前面节点)
的个数是N/2,二阶节点的个数是N/4。所以一个节点为一阶的概率是1/2,为二阶的概率是1/4,…,为k阶的概率是1/2k。
查找操作
一次Find操作,从上往下一阶阶遍历,当遇到下一个节点大于目标元素或者为NULL的节点时,则推进到当前节点的下一阶;重复上述遍历逻辑,
直至找到目标元素。例如下图10-60查找目标元素11,第一阶查询遇到遍历到下一个节点13>11,所以当前节点向下推进一阶,遍历到节点8的下一
个节点13>11,节点8向下推进一阶,遍历到节点10的下一个节点13>11,节点10继续向下推进一阶直至找到目标节点11。

插入操作
根据随机算法创建一个k阶节点,根据Find操作类似,找每层的目标插入位置,即附加指针指向的下一个节点大于目标元素或者为NULL的节点,
进行类似普通链表的节点插入。如下图,元素22的插入过程。

删除操作
删除操作跟插入过程正好是相反的过程,找到每阶层目标的前一个位置,将对应指针指向目标节点附加指针指向的节点。
例如将目标元素为8的节点删除,过程如下图。

代码实现(c++)
 View Code
View Code
应用场景
跳跃表的发明者William Pugh对跳跃表的评价,“跳跃列表是在很多应用中有可能替代平衡树而作为实现方法的一种数据结构。
跳跃列表的算法有同平衡树一样的渐进的预期时间边界,并且更简单、更快速和使用更少的空间。” 目前在很多场景中都有应用,如Redis,LevelDB等。
引用:
《数据结构与算法分析》
https://en.wikipedia.org/wiki/Skip_list
https://zhuanlan.zhihu.com/p/91753863
来源https://www.cnblogs.com/whao2world/p/14704317.html