
序列表示方法
目录
Spatial signals
Temporal signals
Sequence
Sequence embedding
[b,100,1]
[b,28,28]
Batch
[words,word vec]
Word embedding
Embedding Layer
Spatial signals
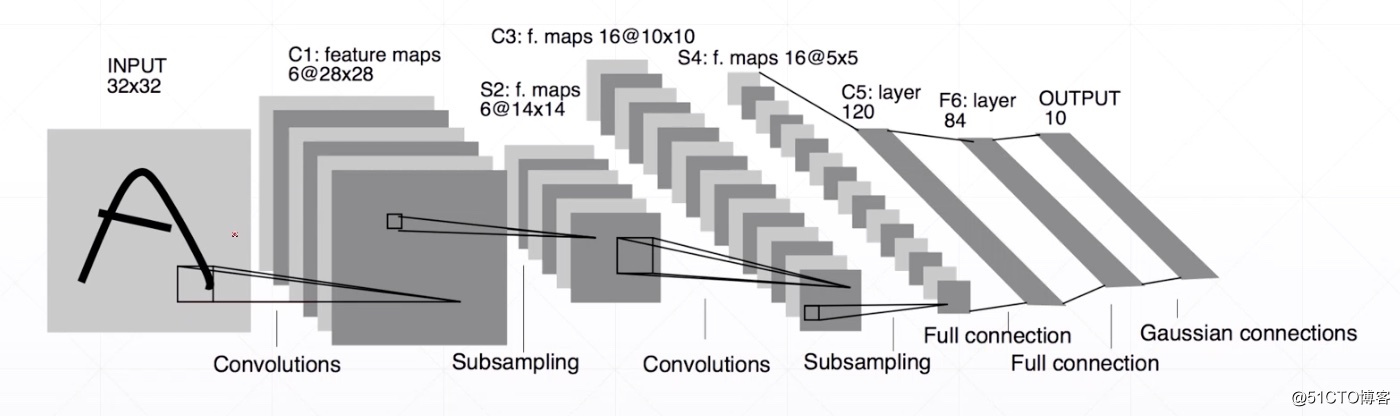
Temporal signals

Sequence
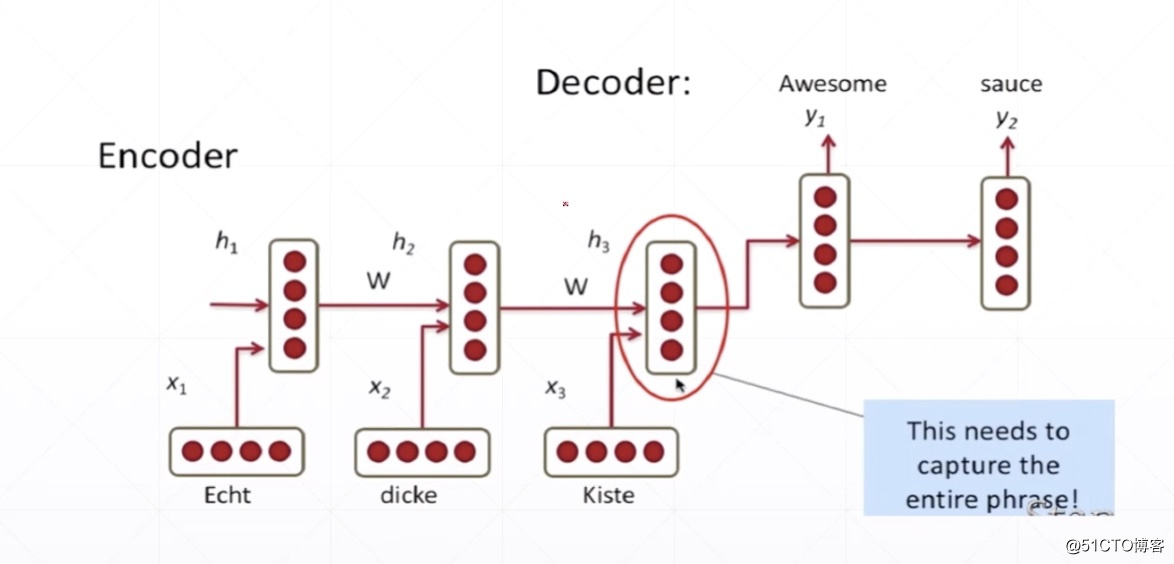
Sequence embedding
[b,seq_len,feature_len] # 1个句子10个单词每个单词4个意思,[1,10,4]
e.g. I like it.
import tensorflow as tf tf.convert_to_tensor([[1,0,0],[0,1,0],[0,0,1]])
<tf.Tensor: id=4, shape=(3, 3), dtype=int32, numpy= array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=int32)>
[b,100,1]
[price,scalar,1] # 1-->1个点表示一个价格
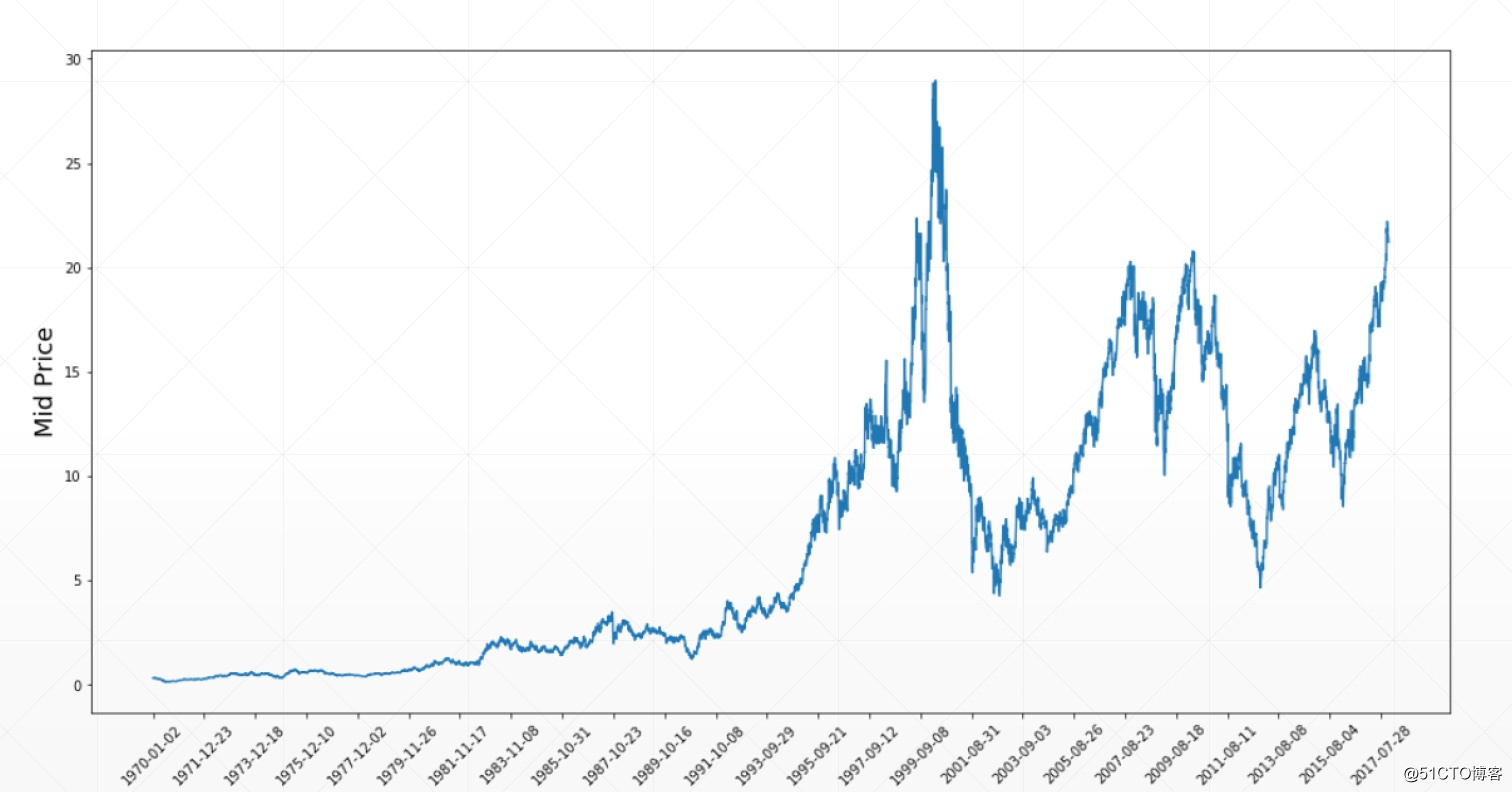
[b,28,28]
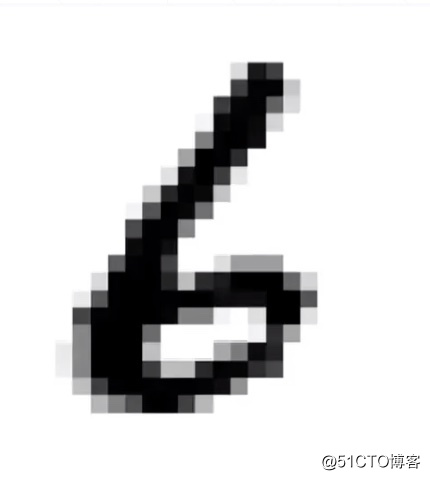
对图片扫描的次数变成了时间的概念

Batch
[b,word num,word vec]
[word num,b,word vec]
[words,word vec]
How to represent a word
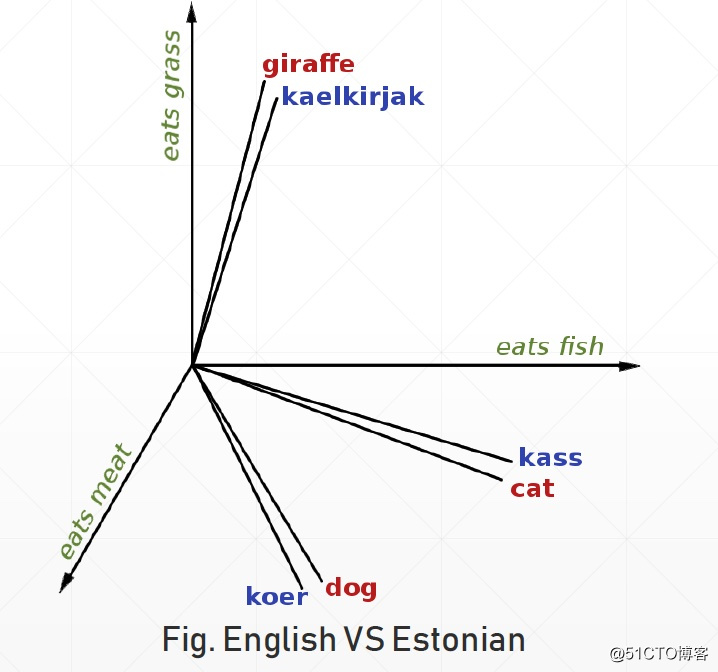
[Rome, Italy, ...]
one hot

sparse
high-dim
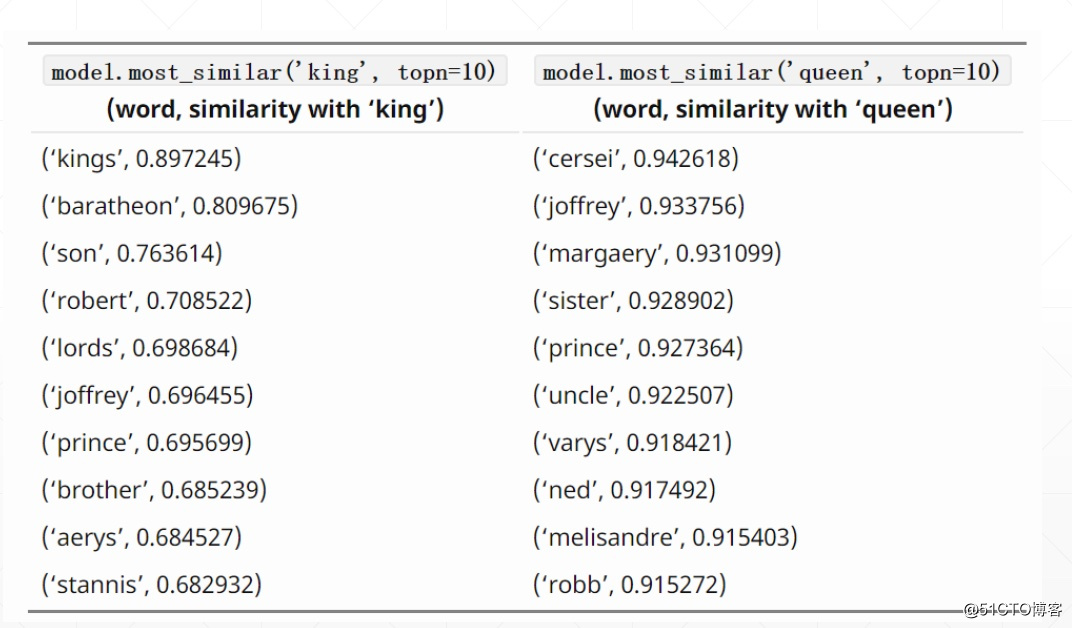
semantic similarity
trainable
Word embedding
Word2Vec vs GloVe
Embedding Layer
Random initialized embedding
from tensorflow.keras import layers x = tf.range(5) x = tf.random.shuffle(x) x
<tf.Tensor: id=10, shape=(5,), dtype=int32, numpy=array([0, 4, 3, 2, 1], dtype=int32)>
net = layers.Embedding(10,4) net(x)
<tf.Tensor: id=26, shape=(5, 4), dtype=float32, numpy= array([[-0.04665176, -0.00618398, -0.02745042, -0.0418861 ], [-0.00495533, -0.02990632, -0.04187028, -0.03159492], [ 0.00022942, -0.01628833, -0.00680885, -0.03196504], [-0.0023623 , 0.04522124, 0.02052191, -0.02518519], [ 0.0211277 , -0.03581526, 0.00149528, 0.04243053]], dtype=float32)>
net.trainable
True
net.trainable_variables
[<tf.Variable 'embedding/embeddings:0' shape=(10, 4) dtype=float32, numpy= array([[-0.04665176, -0.00618398, -0.02745042, -0.0418861 ], [ 0.0211277 , -0.03581526, 0.00149528, 0.04243053], [-0.0023623 , 0.04522124, 0.02052191, -0.02518519], [ 0.00022942, -0.01628833, -0.00680885, -0.03196504], [-0.00495533, -0.02990632, -0.04187028, -0.03159492], [ 0.04476041, 0.00983595, 0.01300793, -0.00486787], [ 0.00272337, 0.00402355, -0.04166143, 0.01867583], [-0.01088942, 0.02177001, 0.01363814, -0.04016535], [-0.04173249, -0.03866537, -0.0426992 , 0.00479555], [ 0.02334514, 0.01809745, -0.03649411, -0.00876436]], dtype=float32)>]