
21秒看尽ImageNet屠榜模型,60+模型架构同台献艺
60+模型架构,历年十几个 SOTA 模型,这 21 秒带你纵览图像识别的演进历史。
ImageNet 是计算机视觉领域常用的数据集之一。在图像分类、目标分割和目标检测中有着无法撼动的地位。ImageNet 最初是由李飞飞等人在 CVPR 2009 年发表的论文——「ImageNet: A Large-Scale Hierarchical Image Database」中发布的。多年来,ImageNet 的相关论文对业内有极大的影响。截至到当前,Google Scholar 上展示该论文有 12224 的引用量。这篇论文在 ImageNet 发布十周年之际,于 CVPR 2019 大会上获得了经典论文奖。ImageNet 本身则是一个海量的带标注图像数据集。通过众包等方式进行标注,从 2007 年开始直到 2009 年完成。ImageNet 有超过 1500 万张图片,仅汽车图像的数量达到了 70 万张,类别数量为 2567 个。如此巨量、 标注错误极低且免费的数据集,已经成为图像处理领域研究者首先接触的数据集之一。毫不夸张的说,ImageNet 是图像处理算法的试金石。从 2010 年起,每年 ImageNet 官方会举办挑战赛。2017 年后的比赛由 Kaggle 社区主持。自 2012 年 Hinton 等的团队提出 AlexNet 开始,每年都有层出不穷的模型希望在 ImageNet 排行榜上取得一席之地。近日,PaperWithCode 网站发布了一段 21 秒的视频,在 ImageNet 发布十年的时刻,总结了历年来排行榜上取得一定效果的模型。
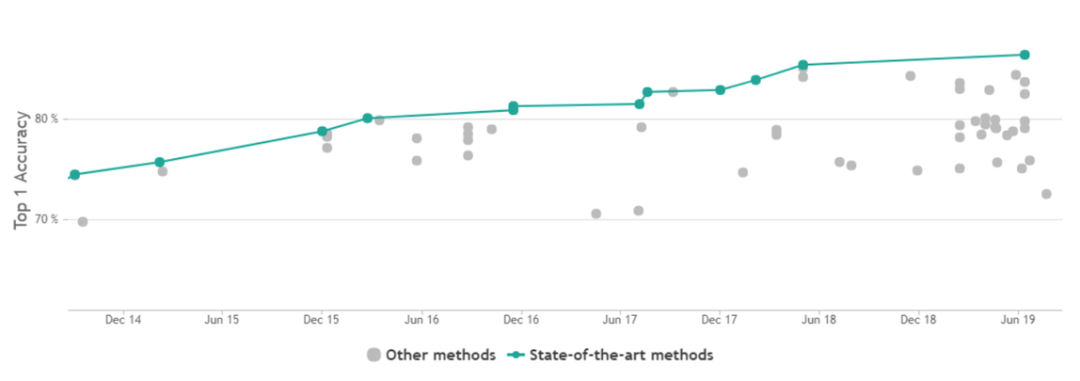 如上展示了 13 到 19 年的分类任务 SOTA 效果演进,真正有大幅度提升的方法很多都在 13 到 15 年提出,例如 Inception 结构、残差模块等等。Leaderboard 地址:https://www.paperswithcode.com/sota/image-classification-on-imagenet机器之心根据视频和网站内容进行了整理。以下为一些著名的模型、发布时间、Top-1 准确率、参数量,以及相关的论文链接。发布时取得 SOTA 的模型名以红色字体标出。这是一堆耳熟能详的模型
如上展示了 13 到 19 年的分类任务 SOTA 效果演进,真正有大幅度提升的方法很多都在 13 到 15 年提出,例如 Inception 结构、残差模块等等。Leaderboard 地址:https://www.paperswithcode.com/sota/image-classification-on-imagenet机器之心根据视频和网站内容进行了整理。以下为一些著名的模型、发布时间、Top-1 准确率、参数量,以及相关的论文链接。发布时取得 SOTA 的模型名以红色字体标出。这是一堆耳熟能详的模型
AlexNet
提出时间:2012/9
Top-1 准确率:62.5%
参数量:60M
论文地址:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
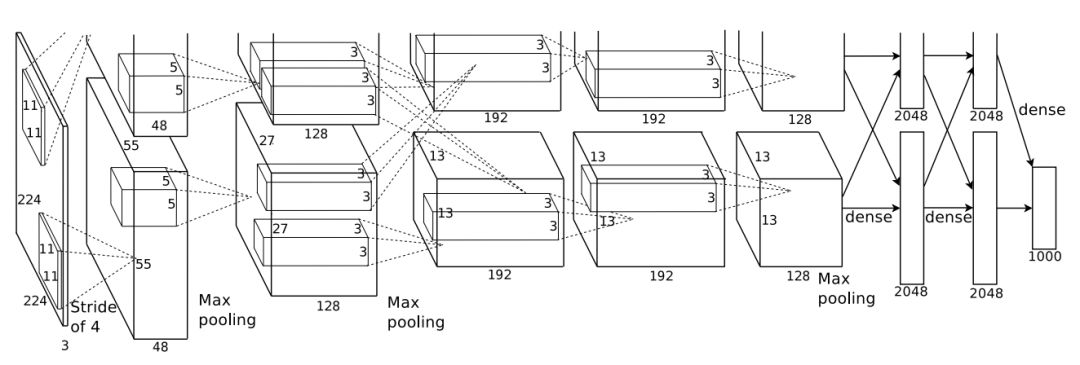
AlexNet 的架构示意图。
ZFNet
提出时间:2013/11
Top-1 准确率:64%
论文地址:https://arxiv.org/pdf/1311.2901v3.pdf
Inception V1
提出时间:2014/9
Top-1 准确率:69.8%
参数量:5M
论文地址:https://arxiv.org/pdf/1409.4842v1.pdf
VGG-19
提出时间:2014/9
Top-1 准确率:74%
参数量:144M
论文地址:https://arxiv.org/pdf/1409.1556v6.pdf
PReLU-Net
提出时间:2015/2
Top-1 准确率:75.73%
论文地址:https://arxiv.org/pdf/1502.01852v1.pdf
Inception V3
提出时间:2015/12
Top-1 准确率:78.8%
参数量:23.8M
论文地址:https://arxiv.org/pdf/1512.00567v3.pdf
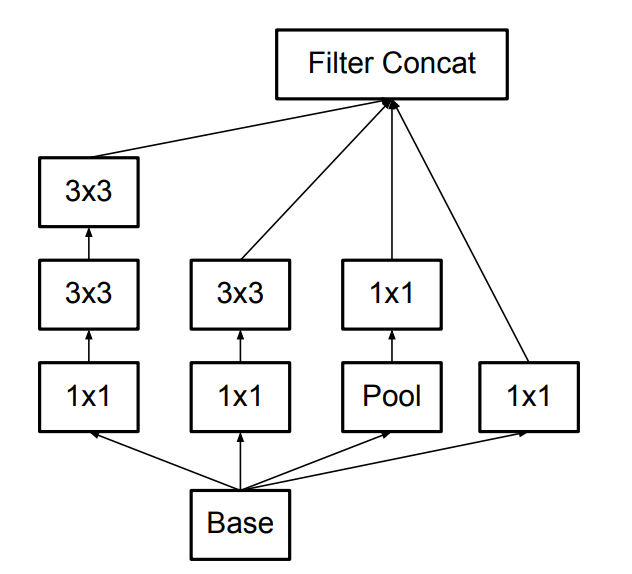
Inception V3。
ResNet 152
提出时间:2015/12
Top-1 准确率:78.6%
论文地址:https://arxiv.org/pdf/1512.03385v1.pdf
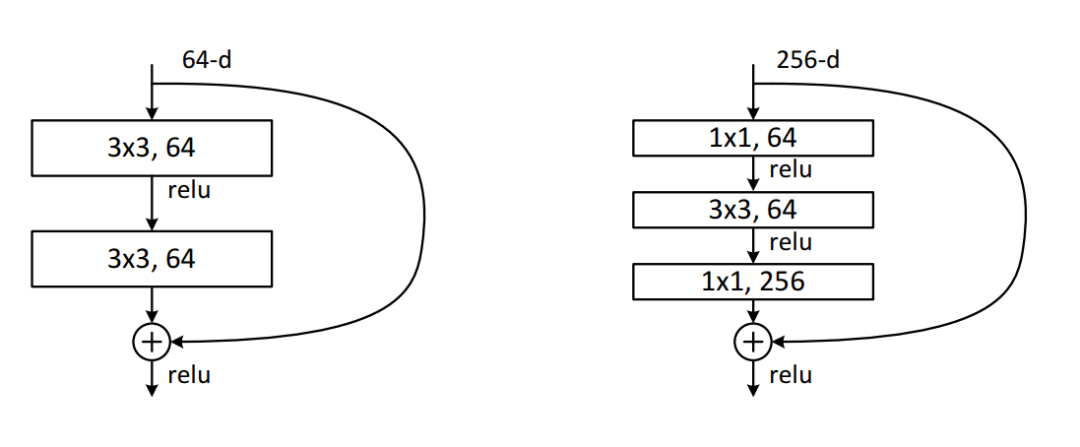
ResNet 的基本模块。
Inception ResNet V2
提出时间:2016/2
Top-1 准确率:80.1%
论文地址:https://arxiv.org/pdf/1602.07261v2.pdf
DenseNet-264
提出时间:2016/8
Top-1 准确率:79.2%
论文地址:https://arxiv.org/pdf/1608.06993v5.pdf
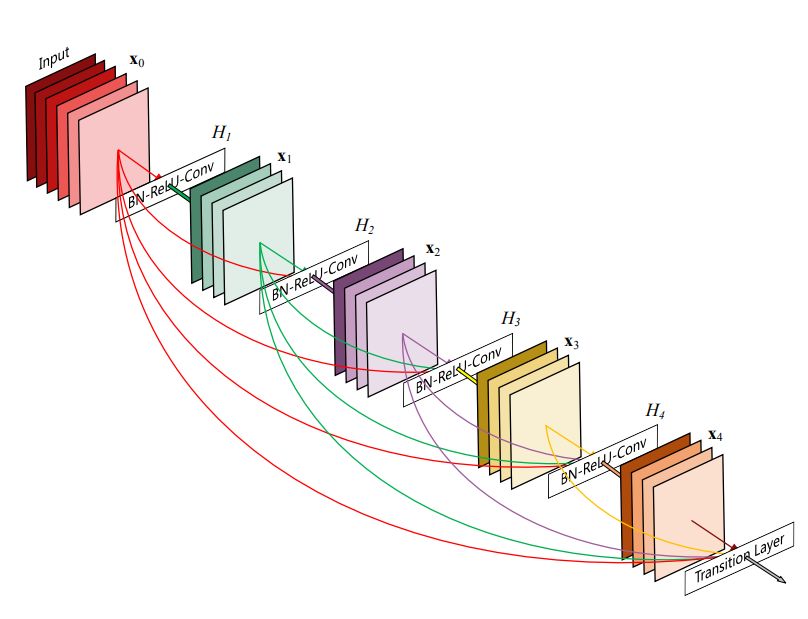
增长率为 4 的 DenseNet 架构。
ResNeXt-101 64×4
提出时间:2016/11
Top-1 准确率:80.9%
参数量:83.6M
论文地址:https://arxiv.org/pdf/1611.05431v2.pdf
PolyNet
提出时间:2016/11
Top-1 准确率:81.3%
参数量:92M
论文地址 https://arxiv.org/pdf/1611.05725v2.pdf
DPN-131
提出时间:2017/7
Top-1 准确率:81.5%
参数量:80M
论文地址:https://arxiv.org/pdf/1707.01629v2.pdf
NASNET-A(6)
提出时间:2017/7
Top-1 准确率:82.7%
参数量:89M
论文地址:https://arxiv.org/pdf/1707.07012v4.pdf
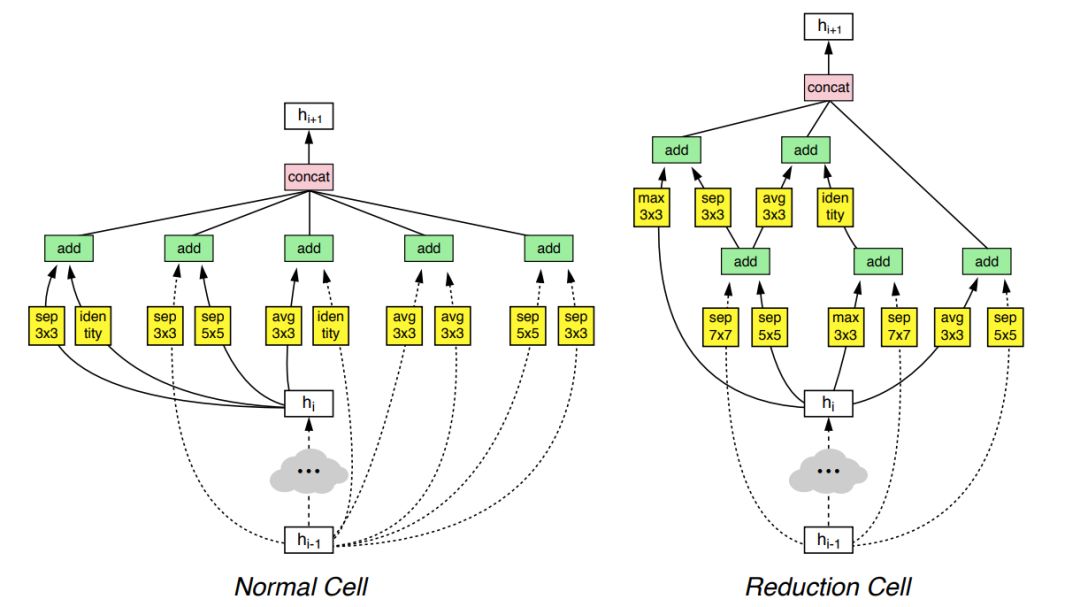
利用神经架构搜索(NAS)方法获得的模型(右图),相比左边的模型减少了参数量,效果得到了提升。
PNASNet-5
提出时间:2017/12
Top-1 准确率:82.9%
参数量:86.1M
论文地址:https://arxiv.org/pdf/1712.00559v3.pdf
MobileNetV2
提出时间:2018/1
Top-1 准确率:74.7%
参数量:6.9M
论文地址:https://arxiv.org/pdf/1801.04381v4.pdf
AmoebaNet-A
提出时间:2018/2
Top-1 准确率:83.9%
参数量:469M
论文地址:https://arxiv.org/pdf/1802.01548v7.pdf
ResNeXt-101 32×48d
提出时间:2018/5
Top-1 准确率:85.4%
参数量:829M
论文地址:https://arxiv.org/pdf/1805.00932v1.pdf
ShuffleNet V2 2×
提出时间:2018/7
Top-1 准确率:75.4%
参数量:7.4M
论文地址:https://arxiv.org/pdf/1807.11164v1.pdf
EfficientNet
提出时间:2019/5
Top-1 准确率:84.4%
参数量:66M
论文地址:https://arxiv.org/pdf/1905.11946v2.pdf
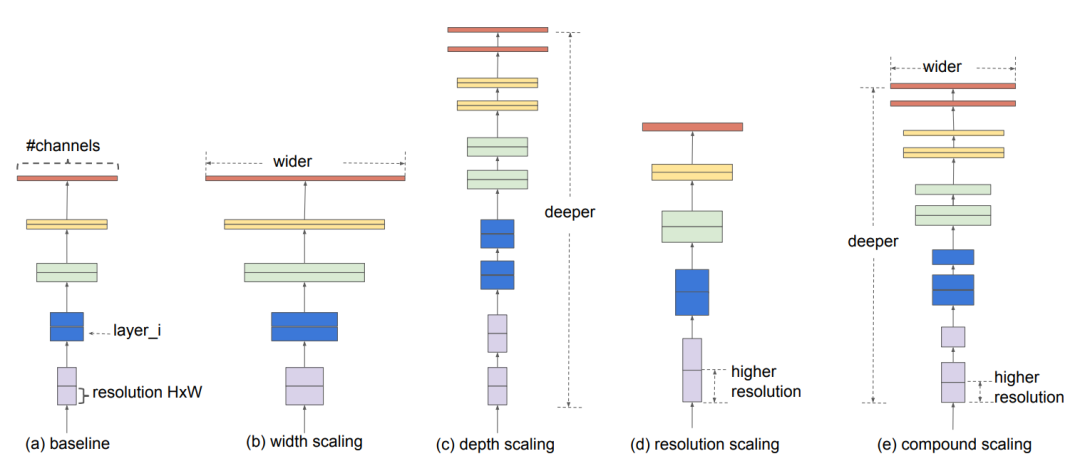
EfficientNet 论文中的架构对比。a)基线模型;b)- d)分别为对图像宽度、深度和分辨率的扫描架构;e)论文提出的可以将所有扫描架构融合在一起的网络结构。
FixResNeXt-101 32×48d
提出时间:2019/6
Top-1 准确率:86.4%
参数量:829M
论文地址:https://arxiv.org/pdf/1906.06423v2.pdf
你发现了某些规律?从屠榜模型来看,取得 SOTA 的模型参数量在逐年增加。从有 60M 参数量的 AlexNet 到有着 829M 的 FixResNeXt-101 32×48d,模型一年比一年更大了。但是也有很意外的情况,比如 DenseNet 获得了 CVPR 2017 的最佳论文,但是 DenseNet 并没有达到 SOTA 的效果。此外,名声在外的 ResNet 也仅仅是接近 2015 年的 SOTA 模型 Inception V3。但是,没有取得 SOTA 并不代表这些模型不好。它们给了后续工作很大的启发。值得注意的是,从 2018 年开始,缩小模型参数量的研究逐渐增多。可以看到有 MobileNet、ShuffleNet 等,可惜在性能上牺牲了很多。今年最著名的小型化模型是谷歌提出的 EfficientNet,仅有 66M 的参数量,但已经接近目前的 SOTA 分数了。了解模型架构可以看这里机器之心也曾经介绍过很多博客与论文,它们是理解这些模型架构的好资源。以下都是一些综述性文章,它们非常适合全面了解架构的演变:
图像领域研究的未来从近年来图像研究领域的论文主题来看,现在有几大研究方向值得关注。首先,在算法领域,生成对抗网络(GAN)的研究呈现井喷的趋势。越来越多的研究者尝试使用 GAN 进行图像方面的研究,如图像识别、对抗样本攻击和防御,以及生成高清晰度图像、图像风格转换、直接生成新图像等方面的研究。也有部分学者尝试用 GAN 进行目标检测。其次,在任务领域,有更多由静态图像转变为动态的视频图像、由 2D 图像研究转向 3D 图像和三维数据方面的研究。近年来,有更多的尝试研究视频领域中的图像分类、目标分割和检测方面的算法出现,实现了诸如行人检测、人体姿态追踪等方面的应用。同时研究人员尝试使用深度学习模型探究 3D 建模方面的表现。最后,在模型方面,出现了模型参数缩减和模型压缩方面的多种研究。很多学者研究在不影响模型性能的前提下进行模型剪枝和压缩方面的技术,希望能够将性能优异模型部署在移动端或物联网设备上,实现本地化的模型推断。
在机器之心承办的世界人工智能大会黑客马拉松上,软银机器人、微众银行、第四范式发布三大赛题,点击阅读原文了解详情并参与报名。
