
Redis实战篇:基于HyperLogLog实现UV统计功能
如果现在要开发一个功能:
统计APP或网页的一个页面,每天有多少用户点击进入的次数。同一个用户的反复点击进入记为 1 次,也就是统计 UV 数据。
让你来开发这个统计模块,你会如何实现?
如果统计 PV 数据,只要给网页一个独立的 Redis 计数器就可以了,这个计数器的 key 的格式为 puv:{pid}:{yyyyMMdd}。每来一个请求就 incrby 一次,就可以统计出所有的 PV 数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
你可能会马上想到,用 Hash 数据类型就能满足去重。这确实是一种解决方法,但是当这个页面的日活达到百万或千万以上级别的话,Hash 的内存开销就会非常大。
我们来估算一下采用 Hash 的内存空间是多大。假设 key 是 int 类型,对应的是用户ID,value 是 bool 类型,表示已访问,当有百万级不同用户访问时,内存空间为:100万 * (32+8)bit = 40MB。
那有更好的方法吗?有的,下面来介绍基于 HyperLogLog 的解决方案。首先我们先来了解一下 HyperLogLog。
HyperLogLog
HyperLogLog 的作用是提供不精确的去重计数方案。虽然不精确,但也不是非常不精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。
它的优点是使用极少的内存就能统计大量的数据,Redis 实现的 HyperLogLog,只需要 12K 内存就能统计 $2^64$ 个数据。远比 Hash 的内存开销要少。
HyperLogLog(HLL) 是一种用于基数计数的概率算法,是基于 LogLog(LLC) 算法的优化和改进,在同样空间复杂度下,能够比 LLC 的基数估计误差更小。
HyperLogLog 算法的通俗说明:假设我们为一个数据集合生成一个8位的哈希串,那么我们得到00000111的概率是很低的,也就是说,我们生成大量连续的0的概率是很低的。生成连续5个0的概率是1/32,那么我们得到这个串时,可以估算,这个数据集的基数是32。
再深入的那就是数学公式,可参考本文最后的参考链接前往研究。
Redis 中 HLL 的使用
| 命令 | 说明 | 可用版本 | 时间复杂度 |
| PFADD | 添加 | >= 2.8.9 | O(1) |
| PFCOUNT | 获得基数值 | >= 2.8.9 | O(1) |
| PFMERGE | 合并多个key | >= 2.8.9 | O(N) |
示例代码

using StackExchange.Redis;using System;public class PageUVDemo
{ private static IDatabase db; static void Main(string[] args)
{
ConnectionMultiplexer connection = ConnectionMultiplexer.Connect("192.168.0.104:7001,password=123456");
db = connection.GetDatabase();
Console.WriteLine("hll:");
HLLVisit(1000, 1000);
HLLVisit(10000, 10000);
HLLVisit(100000, 100000);
Console.WriteLine("hash:");
HashVisit(1000, 1000);
HashVisit(10000, 10000);
HashVisit(100000, 100000);
connection.Close();
} static void HLLVisit(int times, int pid)
{ string key = $"puv:hll:{pid}";
DateTime start = DateTime.Now; for (int i = 0; i < times; i++)
{
db.HyperLogLogAdd(key, i);
} long total = db.HyperLogLogLength(key);
DateTime end = DateTime.Now;
Console.WriteLine("插入{0}次:", times);
Console.WriteLine(" total:{0}", total);
Console.WriteLine(" duration:{0:F2}s", (end - start).TotalSeconds);
Console.WriteLine();
} static void HashVisit(int times, int pid)
{ string key = $"puv:hash:{pid}";
DateTime start = DateTime.Now; for (int i = 0; i < times; i++)
{
db.HashSet(key, i, true);
} long total = db.HashLength(key);
DateTime end = DateTime.Now;
Console.WriteLine("插入{0}次:", times);
Console.WriteLine(" total:{0}", total);
Console.WriteLine(" duration:{0:F2}s", (end - start).TotalSeconds);
Console.WriteLine();
}
}
运行结果
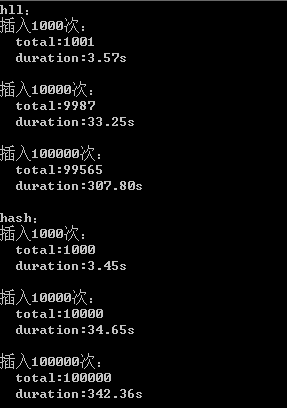
结果对比

数据通过 redis-rdb-tools 导出,更多请查看。
| 数据类型 | 插入次数 | 内存开销 | 时间开销 | 误差率 |
| hash | 1000 | 35KB | 3.45s | 0% |
| 10000 | 426KB | 34.65s | 0% | |
| 100000 | 3880KB | 342.36s | 0% | |
| hll | 1000 | 2KB | 3.57s | 0.1% |
| 10000 | 14KB | 33.25s | 0.13% | |
| 100000 | 14KB | 307.80s | 0.44% |
从上面的结果可以看出,10万次级别下,HyperLogLog 的误差率很低,0.44%,但内存开销是 Hash 的0.3%,随着数量级的提升,内存开销差距也越大。
应用场景
统计注册 IP 数
统计每日访问 IP 数
统计页面实时 UV 数
统计在线用户数
统计用户每天搜索不同词条的个数
总结
不追求百分百的准确度时,使用 HyperLogLog 数据结构能减少内存开销。
参考资料
©著作权归作者所有:来自51CTO博客作者李季谦千的原创作品,如需转载,请注明出处,否则将追究法律责任