
Spark SQL 中 Broadcast Join 一定比 Shuffle Join 快?那你就错
Spark SQL 中 Broadcast Join 一定比 Shuffle Join 快?那你就错了。
过往记忆大数据 过往记忆大数据
本资料来自 Workday 的软件开发工程师 Jianneng Li 在 Spark Summit North America 2020 的 《On Improving Broadcast Joins in Spark SQL》议题的分享。相关 PPT 可以到 你要的 Spark AI Summit 2020 PPT 我已经给你整理好了 里面获取。
背景
相信使用 Apache Spark 进行数据分析的同学对 Spark 中的 Broadcast Join 比较熟悉,其在 Join 之前会把一端比较小的表广播到参与 Join 的 worker 端,具体如下:
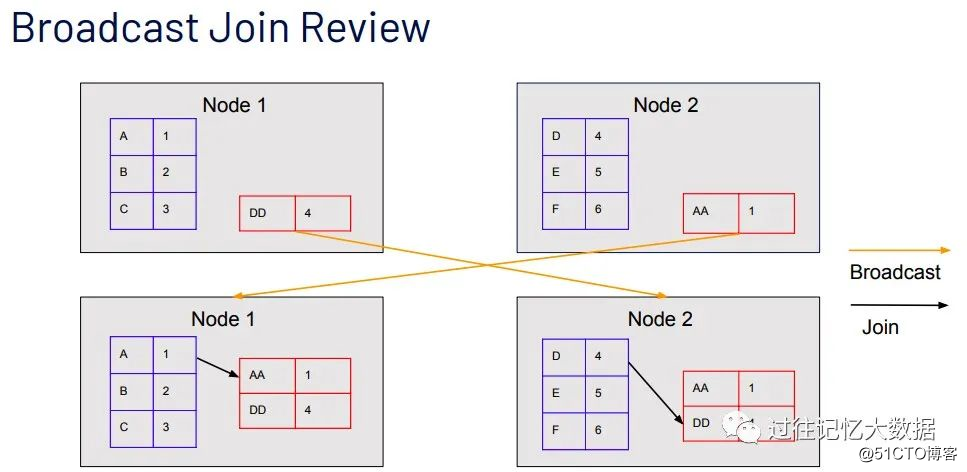
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
相比 Shuffle Join,Broadcast Join 的优势主要有:
•避免把大表的数据 shuffle 到其他节点;
•很自然地处理数据倾斜
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
很多人得出结论:在 Broadcast Join 适用的情况下,Broadcast Join 是要比 Shuffle Join 快!但事实是这样的吗?
TPC-H 测试
在得出结论之前我们先来进行 TPC-H 测试,来看下是不是 Broadcast Join 一定要比 Shuffle Join 快。测试条件如下:
•数据集 10GB;
•查询:6千万条数据的 lineitem 表 join 1.5千万的 orders 表
•Driver 的配置:1 core, 12 GB
•Executor 的配置:一个 instance,18 cores, 102 GB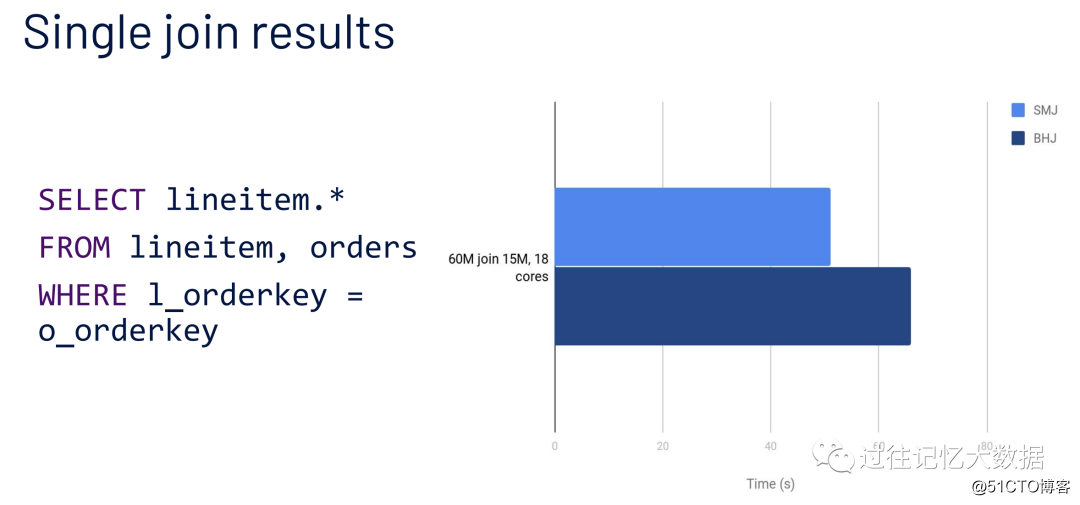
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
从上面可以结果可以看出,Broadcast Join 比 Shuffle Join 跑的慢!
Broadcast Join 机制
在理解上面结果之前,我们先来看下 Broadcast Join 的运行机制。
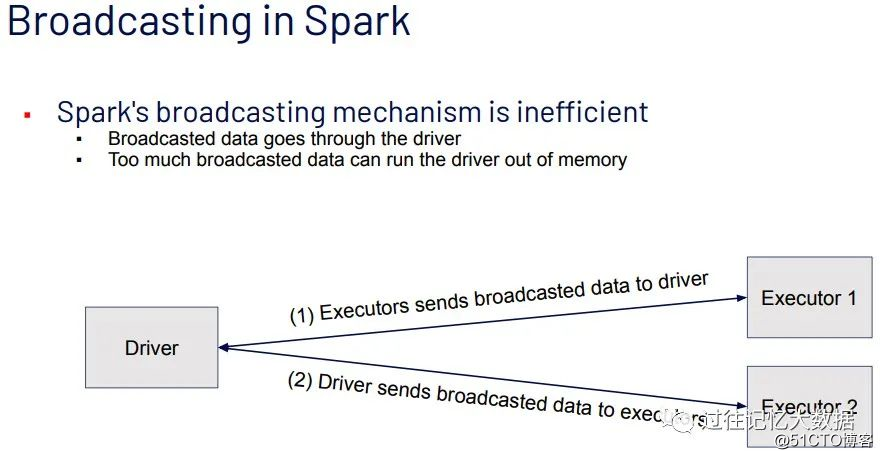
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在进行 Broadcast Join 之前,Spark 需要把处于 Executor 端的数据先发送到 Driver 端,然后 Driver 端再把数据广播到 Executor 端。如果我们需要广播的数据比较多,比如我们把 spark.sql.autoBroadcastJoinThreshold 这个参数设置到 1G,但是我们的 Driver 端的内存值设置为 500M,那这种情况下会导致 Driver 端出现 OOM。根据前面的分析,上面 TPC-H 结果慢是因为:
•Driver 端需要 collects 1.5千万条的数据;
•Driver 端构建 hashtable;
•Driver 把构建好的 hashtable 发送到 Executor 端;
•Executor deserializes hashtable。
所以说由于当前 Broadcast Join 的运行机制,这就导致即使在 Broadcast Join 适用的情况下,Broadcast Join 不一定比 Shuffle Join 快。
过往记忆大数据提示,大家如果对这部分代码感兴趣可以参看 BroadcastExchangeExec.scala 类的相关代码,其先调用 org.apache.spark.sql.execution.SparkPlan 类里面的 executeCollectIterator 方法,其主要是将数据从 Executor 发送到 Driver,大家可以看到里面调用了 getByteArrayRdd().collect():
private[spark] def executeCollectIterator(): (Long, Iterator[InternalRow]) = {
val countsAndBytes = getByteArrayRdd().collect()
val total = countsAndBytes.map(_._1).sum
val rows = countsAndBytes.iterator.flatMap(countAndBytes => decodeUnsafeRows(countAndBytes._2))
(total, rows)
}然后到 relationFuture 变量初始化:
private1 lazy val relationFuture: Future[broadcast.Broadcast[Any]] = {
SQLExecution.withThreadLocalCaptured[broadcast.Broadcast[Any]](
sqlContext.sparkSession, BroadcastExchangeExec.executionContext) { try { // 这个地方就是前面说的将数据 Collect 到 Driver 端:
val (numRows, input) = child.executeCollectIterator() // 这里省去了一部分代码
// Construct the relation.
val relation = mode.transform(input, Some(numRows)) // 这里省去了一部分代码
val beforeBroadcast = System.nanoTime()
longMetric("buildTime") += NANOSECONDS.toMillis(beforeBroadcast - beforeBuild) // Broadcast the relation
// 这个地方就是前面说的需要先 broadcast 数据到 Executor 端
val broadcasted = sparkContext.broadcast(relation)
longMetric("broadcastTime") += NANOSECONDS.toMillis(
System.nanoTime() - beforeBroadcast)
val executionId = sparkContext.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
SQLMetrics.postDriverMetricUpdates(sparkContext, executionId, metrics.values.toSeq)
promise.trySuccess(broadcasted)
broadcasted
} catch { // 这里省去了一部分代码
}
}
}提升 Broadcast Join 的性能
针对上面的分析,我们能不能不把数据 collect 到 Driver 端,而直接在 Executor 端之间进行数据交换呢?这就是 Workday 的工程师团队给我们带来的 Executor 端的 broadcast,这项工作可以参见 SPARK-17556。我们来看看 Executor 端的 broadcast 工作原理:
•Executors 把 Join 需要的数据 broadcasted 给其他 Executors;
•Driver 端只负责记录 Executors 端的 block 信息,这样其他 Executor 就可以知道 block 可以从哪些 Executor 获取。
具体流程如下:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
测试结果
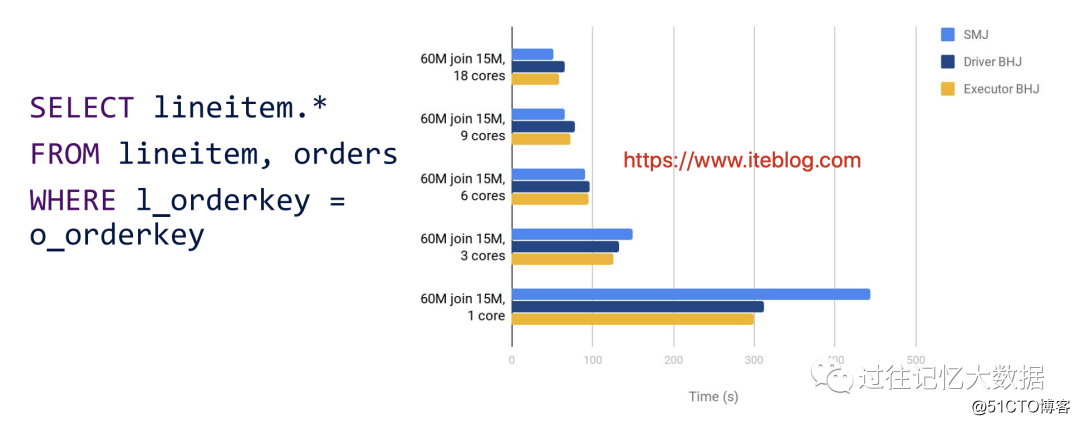
Workday 的工程师分别测试了以下三种测试场景:
•数据量不变,分别测试不同 core 的性能;
•lineitem 表大小不同测性能;
•加大 orders 表的大小
结果如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
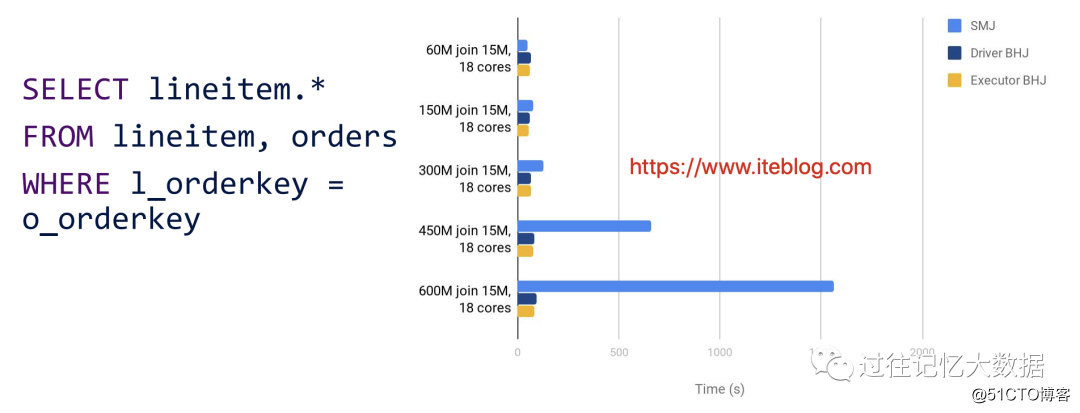
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
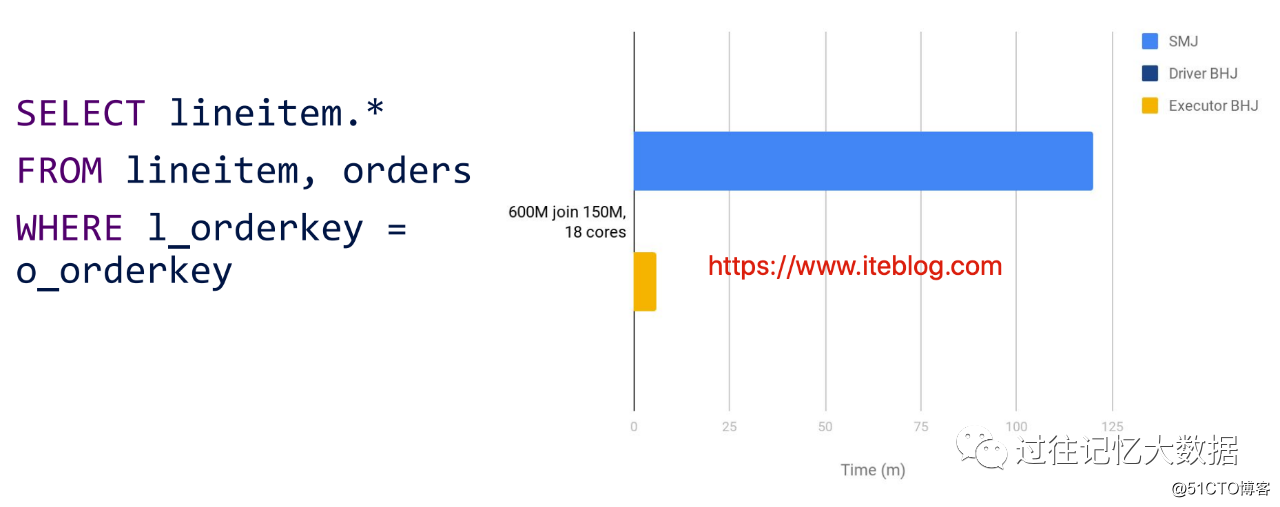
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 总结起来就是:
•在数据量一样的情况下,如果 core 的个数比较多,Shuffle Join 是有优势的;
•如果非广播的表数据量数据量越来越大,Broadcast Join 是有优势的;
•如果加大广播表的数据量,Driver 端的 Broadcast 是跑不出结果,Executor 的 Broadcast Join 是比较快的。
根据上面的结论,所以大家要知道 Broadcast 不一定比 Shuffle 快。另外,Executor 端的 Broadcast 特性是2016年9月就提的,截止到最新的 Apache Spark 3.0.0 这个功能还没有合并到主分支,如果大家有需要这个,可以自行合并。
©著作权归作者所有:来自51CTO博客作者mob604756f47778的原创作品,如需转载,请注明出处,否则将追究法律责任