
主流: KHB法测度中介效应, 无论线性还是非线性模型, KHB都能分解出直接和间接效应!
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
关于交互项、中介效应或机制分析,各位学者可以参看如下文章:1.计量回归中的交互项到底什么鬼? 捎一本书给你,2.计量经济学中"交互项"相关的5个问题和回应,3.实证机制分析那些事,机制分析什么鬼?,4.政策评估中"中介效应"因果分析, 增添了文献和Notes,5.内生变量的交互项如何寻工具变量, 交互项共线咋办,6.因果中介效应分析出现在顶刊, 是时候使用新方法了,7.中介和调节效应自助法检验,针对非正态截面数据,8.面板数据中介效应的计算程序, 打开面板这扇门,9.中介和调节效应操作指南, 经典书籍和PPT珍藏版,10.中介效应分析的四种方式, 原则方法和应用综述,11.中介效应分析的方法和模型, 一篇听说必须看的文献,12.多重中介效应的估计与检验, Stata MP15可下载,13.具有调节变量的中介效应分析, moderated mediation,14.具有调节变量的中介效应程序和数据, 独家解读相关结果,15.有限混合模型FMM,异质性分组分析的新筹码。
16.省份/行业固定效应与年份固定效应的交乘项固定效应,17.面板数据中去中心化的交互项回归什么情况,18.面板交互固定效应是什么, 白聚山教授推动了最前沿的研究,19.广义合成控制法gsynth, 基于交互固定效应的因果推断,20.一个完整的实证程序, 以logit或ologit为例,21.跨数据比较回归系数技巧,22.U型, 倒U型, 还是线性关系, 你平常的做法不靠谱,23.DID中行业/区域与时间趋势的交互项, 共同趋势检验, 动态政策效应检验,24.机制分析做到极致的JPE趣文, 身高与收入,25.机制分析, 中介渠道, 调节效应必读系列合集,26.自变量和中介变量是内生的情况咋办?放在因果中介的框架,27.调节变量, 中介变量和控制变量啥区别与联系?,28.多个中介变量如何检验中介效应?,29.中介变量需要放到回归中去吗?何时放何时不放?,30.机制分析, 中介渠道, 调节效应必读系列合集,31.三张图秒懂, 混淆, 中介, 调节, 对撞, 暴露, 结果和协变量的复杂关系,32.中介效应检验流程, 示意图公布, 不再畏惧中介分析。
正文
关于下方文字内容,作者:仇旸,英国华威大学经济学,通信邮箱:Yang.Qiu.1@warwick.ac.uk
In a series of recent articles, Karlson, Holm, and Breen (Breen, Karlson,and Holm, 2011, http://papers.***n.com/sol3/papers.cfm?abstractid=1730065;Karlson and Holm, 2011, Research in Stratification and Social Mobility 29: 221–237; Karlson, Holm, and Breen, 2010, http://www.yale.edu/ciqle/Breen Scaling effects.pdf) have developed a method for comparing the estimated coefficientsof two nested nonlinear probability models. In this article, we describe this methodand the user-written program khb, which implements the method. The KHBmethod is a general decomposition method that is unaffected by the rescalingor attenuation bias that arises in cross-model comparisons in nonlinear models.It recovers the degree to which a control variable, Z, mediates or explains therelationship between X and a latent outcome variable, Y*, underlying the nonlinearprobability model. It also decomposes effects of both discrete and continuousvariables, applies to average partial effects, and provides analytically derived statisticaltests. The method can be extended to other models in the generalizedlinear model family.
一. 概述
由于尺度问题,拟合中介模型的中介变量检测技术无法运用在非线性回归模型中。近年发展出的KHB技术可以解决上述尺度问题,从而有效估计非线性回归模型的中介变量。然而之前的研究只证实了KHB技术在二元logistic回归模型的应用,此文将检测KHB在拟合有序logistic回归模型中的表现,进而展示KHB更广泛的应用空间。文章测试了38,400个实验条件下(包括样本量、反应类别的数量、变量的分布和中介量),KHB的表现。结果显示在所有实验条件下,KHB对中介变量系数及相关标准误差的估测几乎没有偏好,且名义置信区间与实际置信区间十分接近。因此,使用KHB的研究人员可以合理假设该例程近似于总体参数。
二.前言
中介分析通常被运用到分类变量中。相比于线性回归模型,分类变量存在更多问题,比如尺度问题。针对尺度问题,研究人员已经提出了多种解决方法。KHB法作为一个较新的解决方法,自Kohler, Karlson和Holm (2011)的提出,逐渐广为熟知。尽管KHB法已经被广泛运用到不同学科(截止到2019年9月,KHB基础文章已经被引用了1400次),以往的KHB只运用在二元反应变量中,且实验条件(样本量,中介程度)相对适中。
除了二元变量模型,目前在Stata中KHB法还可以运用在13个程序里(有序logit,多项logit,排序logit, xtlogit等)。而本文只关注了有序logistic模型。通过自举模拟,作者模拟了一系列数据条件,并在这些实验条件下评估了KHB的表现。作者做出了以下贡献:
首次评估了KHB法在有序logit模型中的表现。实际上,尽管有序变量的回归模型在社会行为学和生物医学中广泛应用,除了Lipsitz等人在2013年关于有序logistic回归中参数估计偏倚校正的工作外,即使是在简单的没有中介估计的应用中,其他文献也基本上没有对此类模型进行表现分析。因此,由于有序变量模型表现的相关文献缺失,现有证据不足以证明二元变量KHB可以运用在有序变量模型中。
虽然还没有人从经验上或理论上检验过这个问题,但用KHB法对有序变量模型的估测比二元变量更难。作者首先怀疑“k个种类的有序变量总是需要比相应的二元变量模型多估计k−2个阈值参数”。其次,对于均匀分布响应变量的最小稀疏情况,一个给定N的有序模型将比其相对应的二元变量模型在每个种类都少2/k个数据(事件)。在实际研究中,稀疏性问题更加严重。这是因为有序变量数据通常表现出偏态或其他非均匀分布,且在一个或多个极端类别中的数据比其他类别的数据少得多。在简单二元logistic回归模型中,这种潜在的稀疏性是评估“每个变量的事件”影响的重点。近年的文献又加入了样本大小、协变量之间的相关结构以及参数数量等因素对评估的影响。通过类比将此文献扩展到KHB法中介分析和有序变量的稀疏或多参数的情况,表明有序变量回归可能比简单的二元变量模型更能挑战KHB的性能。
作者关注了模拟中观察到的中介系数经验标准误差 (ESE)的相对大小。现有KHB的表现评估大多只关注中介系数,而不是它的方差。然而在简单的二元logistic回归模型中,估测斜率的抽样方差通常被认为远大于其偏倚,类比推理可得在估计KHB中介系数时可能会出现类似的情况。通过使用基于中介系数标准误差渐近估计的正态理论置信区间,作者对中介系数的置信区间覆盖率进行了一个独特且互补的检验。值得注意的是无论置信区间的执行情况如何,抽样可变性的数量都是值得关注的。
与之前的研究相比,本文在更广泛、详细的实验模拟条件下检测了KHB的表现。近年的研究表明,在简单的二元logistic回归模型中,一些必要的范围和细节都被忽略了。这一发现与本文不谋而合:作者认为这些细节与中介水平评估过程同样相关。例如:本文选择了几个更小但常见的样本大小(n = 150、400和800),而不是在KHB二元logistic原始评估应用中唯一选择的n = 5000 (Karlson和Holm, 2011)——n=5000使稀疏性问题不会出现,因为样本足够多。文章还包括不同数量的反应变量类别,中介量的数量,反应变量的分布形状,以及预测变量和中介变量的不同测量水平和分布形状——一共38,400种实验条件。且每个条件作者都重复了1000次实验。
综上,通过详细分析KHB在有序logistic回归模型中的表现,文章对KHB法的广泛应用做出了贡献。如果研究表明KHB法在不同条件下均表现良好,那么它不仅将KHB法的应用扩展到有序logistic回归模型中,更增强了其运用于不同现实条件下二元反应数据的可信度。
三.类别变量中介效应的背景
虽然调解的概念(如果不是术语的话)至少可以追溯到Lazarsfeld (1955)关于社会科学的工作。基于Wright(1921,1934)早期工作,中介这一概念在20世纪六七十年代路径分析的兴起中开始流行起来。通常,中介分析涉及结果变量(y)、预测变量(x)和中介变量(m):预测变量可以直接影响结果,通过中介间接影响结果,也可以两者结合影响结果。
然而,在具有连续结果的模型(例如,普通最小二乘)中测量中介的成熟统计技术不能轻易地推广到逻辑回归和其他(非线性)直言反应模型中。因为这些模型没有从误差方差单独估测系数,使不同回归模型系数间的比较存在一定问题。实际上,该系数仅在从误差标准偏差和真实回归系数得出的尺度参数范围内是不同的。中介的估测取决于不同模型间的估测系数与不同的误差标准偏差的比较,从而导致中介难以在分类反应模型中估测,即尺度问题。更多关于尺度问题的详细解释可以参考:Erikson 等人(2005)及Buis(2010)关于非线性概率模型的研究,或者Karlson, Holm, Breen(2012)及Breen, Karlson, Holm(2013,2018)关于KHB法的文章。
针对尺度问题,尤其是logistic回归模型中的尺度问题,研究人员们提出了很多解决方法。其中,近年提出的KHB法被广泛运用在非线性模型中介变量的估测中。与其他方法类似,KHB法包括至少三个变量:因变量(反应变量)y,初始自变量x以及之后的中介自变量m。
KHB法步骤:
“简化模型”中系数与标准误差的估计。简化模型,即y与x间简单的二元关系式图片
“完整模型”中系数与标准误差的估计。完整模型,即x通过m,对y的影响
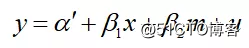
“差分模型”中差分系数即该系数的标准误差估计。差分模型,即计算加入m后x的回归系数相对于y的变化。差分模型用于估测由于m导致的中介(或混杂)数量,从而解释任何与非线性反应模型相关的尺度变换。
差分系数图片用来衡量中介变量m的效果:如果差分系数为正,x的系数在中介变量的作用下减小;如果差分系数为负,x的系数在中介变量的作用下增加,即中介变量的抑制作用。
混杂百分比图片用来衡量相对于原始简化模型中的系数,完整模型里中介的数量。
KHB法评价:
KHB法的发展者认为,其他方法无法有效的解决与估测系数不可分离性及非线性回归模型中误差方差相关的尺度问题。通过Monte Carlo模拟,在二元logistic回归模型中,KHB法的混杂百分比偏倚比其他方法更小。并且KHB法的灵活性、相对于其他选项的表现以及它的易操作性更是促进了它的迅速普及。
过去对KHB法性能的检测只局限在了二元回归模型,且条件相对狭窄。过去的研究只包括了一个大样本(N=5000),且认为估测系数及其方差的偏倚较低,样本分布接近正态。其次,只考虑了二元变量和混杂百分比的有限分布,以及没有考虑估测难度较大的有序变量。
本文通过一套全面的条件,检测了在有序logistic回归模型中KHB调解技术的表现。KHB法在有序logistic回归模型对中介的分析已经被运用在不同领域,比如社会学、政治学、人口统计学、心理学以及公共健康。因此了解KHB在中介有序logistic回归模型中的表现是至关重要的。
四.方法
作者构建了一个代表观察总体的合成数据,以进行典型的中介分析。这个数据中包括有序反应变量y、先行预测变量x和中介变量m,且每个总体实例化一组特定的实验条件。对于每一个合成总体,重复取特定大小的引导样本,用KHB法估测中介数量并保存。通过模拟结果,作者检测了差分系数的偏倚和方差是如何随着不同条件而变化。
4.1 实验条件的选择
实验条件的选择旨在代表实证研究中可能遇到的原型场景。作者构建了一个观察总体(N=10000),其中包含三个和五个类别的有序变量y,且每个变量都有四种分布形式(均匀型、土堆型、u型和左偏型)。先行预测变量x和中介变量m都有五种分布形式:正态分布、80/20分割的二元分布、50/50分割的二元分布、右偏连续分布和左偏连续分布。根据Karlson和Holm(2011)以及Karlson, Holm, Breen(2012),作者通过改变合成数据中y,x,m的相关性使数据包括了不同混合百分比水平。作者使用了Pearson的r值{0.1,0.2,0.3,0.4}来代表变量间的两两相关性,从而组合产生了64种交互相关性,进而使混合百分比在负数与接近200%间变化。
因此,作者构建了12,800个合成总体,包括有两种反应类别数量的y且每个y有4种分布形状、有5种分布形状的x、有5种分布形状的m和64种不同的交互相关性。使用Stata中内置的bootstrap命令,作者以3个样本大小(150、400和800)对这些总体进行了替换,从而得到38,400个不同的实验条件。在每个实验条件下,作者使用了Stata 12和KHB命令(Kohler, Karlson, Holm, 2011)为1,000个复制样本拟合KHB模型。其中,一个主要问题使在构建这些合成总体数据时,Stata的corr2data命令会生成Gaussian连续变量。
4.2 性能的评价标准
作者运用三个标准来评价KHB法的性能:
4.3 分析步骤
首先,根据不同实验条件,选取三个性能评价标准的中位数,以避免平均数的个例扭曲情况,即当各种相对指标的分母较小时,即使很小的绝对误差也会有很大的相对指标。
其次,由于实验设计的复杂性,作者采用了基于回归模型的结果总结,以简明地描述每种实验条件如何独立地影响估计性能。这种基于回归的总结对结果的描述比表格总结更简明易懂。同样由于一些异常值的存在,作者使用了最小绝对偏差(LAD)回归。它总结了每个性能的条件中值,而不是常规(普通的最小二乘法)总结产生的条件均值,随实验条件的变化。
五.结果
5.1 表格分析(表1)
表1展示了每个实验条件下,性能评价标准的中值。表中可得,差分系数图片略微向上偏倚:中位相对偏倚约为总体系数的1.1%。图片的中值偏倚在所有样本规模里都比较小,但与1/N成比例下降(从N = 150时的2.8%下降到N = 800时的0.5%)。在反应变量y的所有分布中,在x和m的分布中以及各种混杂百分比中,相对偏倚的中值都很小,且中值偏倚的范围为0.9%到1.4%。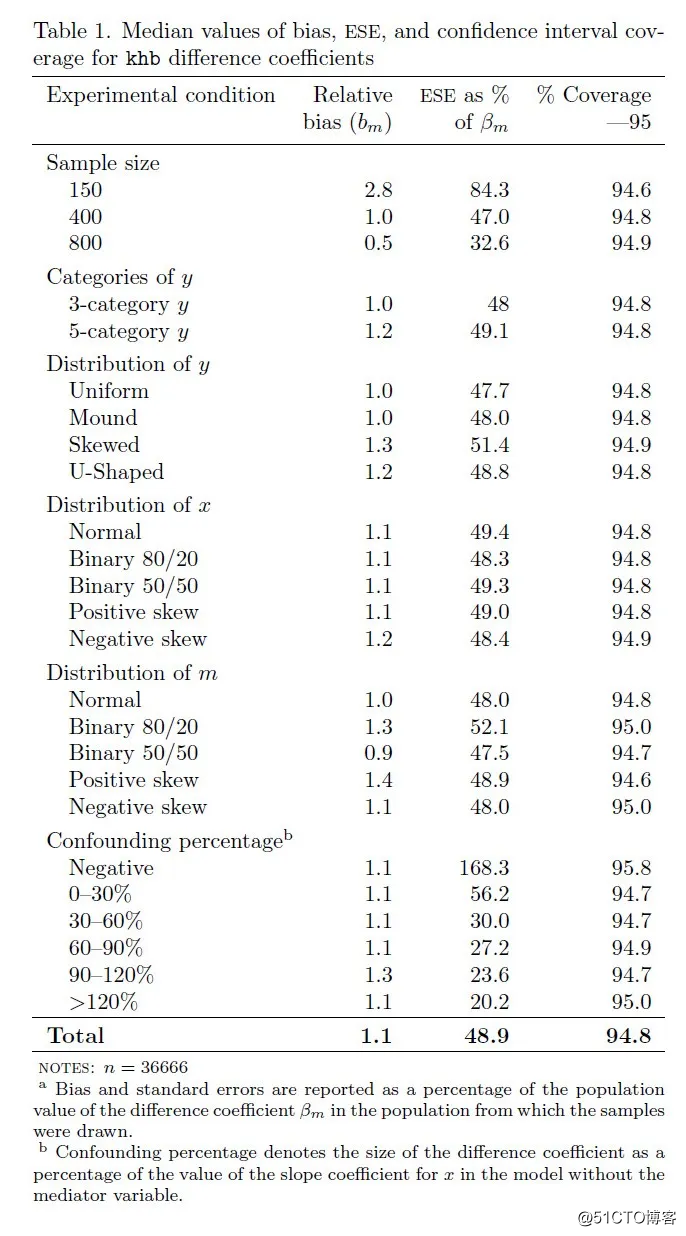
虽然相对偏倚都比较小,但是图片的ESE百分比(估计值的样本可变性)却很大。ESE的中值为48.9%, 几乎是被估计系数总体值的一半。ESE随着样本大小和混杂百分比而变化:当n=150时ESE中值为总体系数的84%,当n=800时下降到33%(减少约1/√N);随着混杂百分比接近0,ESE逐渐增加,说明在几乎没有中介变量时,估计值的相对大小不可靠。
差分系数估计值的置信区间覆盖率一致保持良好,且几乎不随实验条件而变化(在所有实验条件下,中值都不小于94.6%)。
总结:在所有实验条件下,KHB法性能上的系统性差异较小,且都保持良好。
5.2 中值回归模型(表2)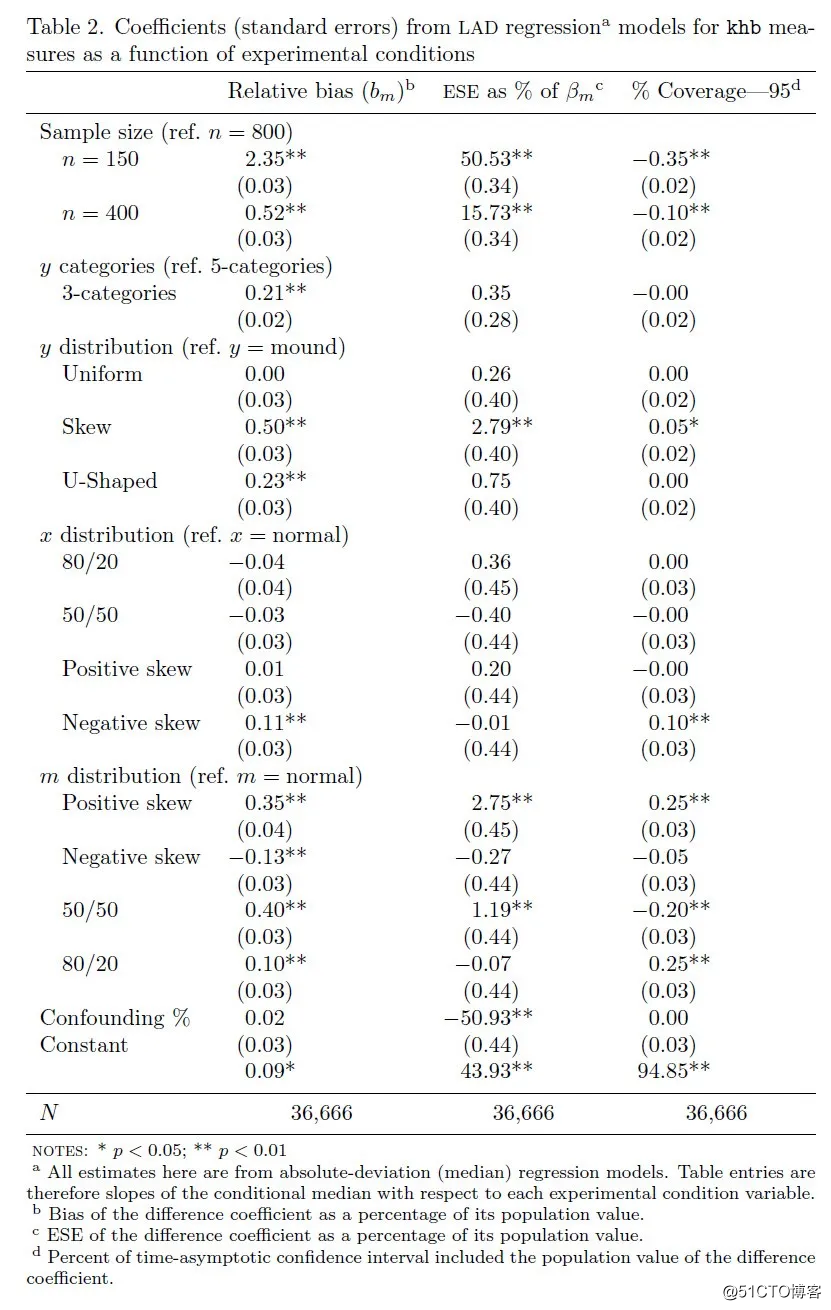
表2展示了LAD回归模型总结了每个实验条件对性能评价标准中值的影响。表中可得,除了n = 150时的样本量,相对偏倚在很大程度上不受任何实验条件的影响(其他条件对相对偏倚的影响都不超过0.5个百分点):与n = 800相比,n = 150时的相对偏差增加了约2.4个百分点,n = 400时增加了0.5个百分点。另外,y的类别数与分布,以及m的分布之间也存在比较小但显著的差异(但x的分布并没有影响)。综上所述,差分系数估计值的偏倚不大。
LAD模型的结果显示,在控制了所有其他条件的情况下,图片的ESE百分比对样本量敏感:在n = 150时,中位ESE比n = 800时高约50个百分点,比n = 400时高15个百分点。此外,在混杂百分比较小的情况下ESE显著增大,且作者通过混杂百分比预测ESE的值对二者的关系进行科补充分析(图1):当混杂百分比接近零时,ESE约为70%,但随着混杂百分比的增加而急剧减少。这一结果反映了个例扭曲的部分影响(即差分系数相对指标的分母较小)。最后,预测的ESE在很大程度上不受反应变量y的类别数或x和m的分布的影响。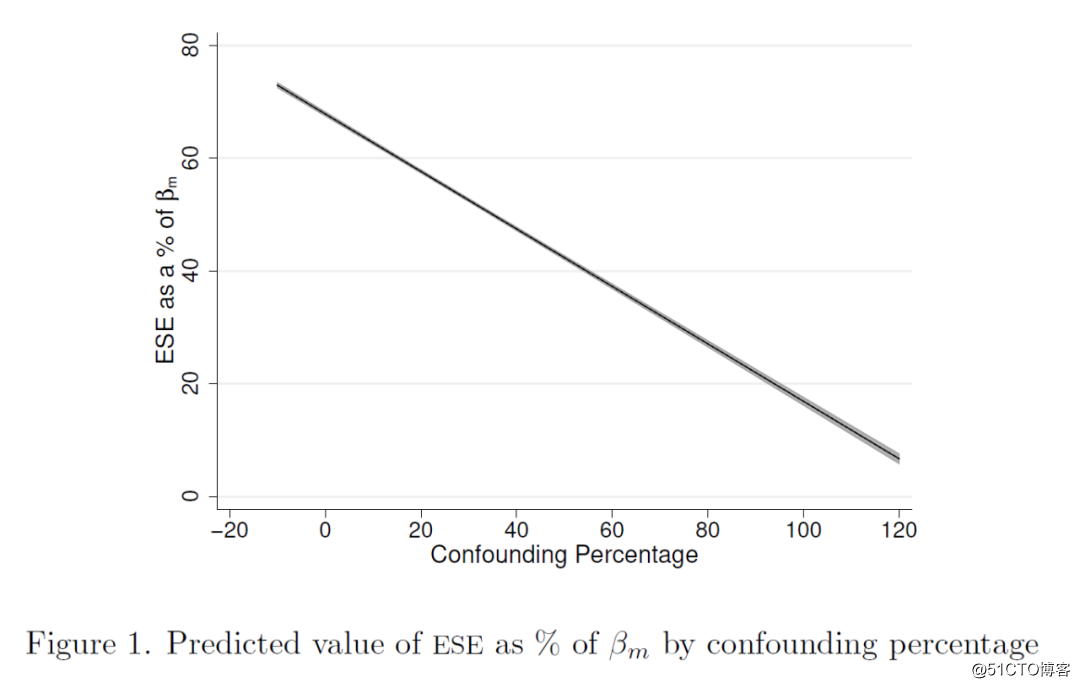
在所有实验条件下,置信区间覆盖率与中位数的差距都不超过0.5个百分点。样本规模是差异的最大来源:与n=800相比,n=150的置信区间覆盖率减少了0.4个百分点,n=400的置信区间覆盖率减少了0.1个百分点。置信区间覆盖率大部分不受y的类别数以及x和y的分布影响,但m的分布对其有部分影响:与正态分布m相比,正偏态分布和80/20分割的二元分布的置信区间覆盖率要高0.3个百分点,而50/50分割的二元分布的覆盖率要低0.2个百分点。混杂百分比对置信区间覆盖率也没有影响。因此在所有条件下,差分系数95%置信区间的KHB估计值通常包含总体参数。
六.结论
KHB法通过差分系数来估计中介量(混杂量),从而解决了在非线性模型长期期存在的中介分析问题。作者以有序logistic回归模型为例,详尽地评估了在非线性反应模型中KHB法估测中介变量的性能。作者发现,至少在有序反应模型中,通过对差分系数估测值的偏倚和置信区间覆盖率的分析,即使样本规模不大,KHB法的估测性能依然很出色。
作者从以下四个方面拓展了前人的研究:
检测了有序反应模型中KHB法的性能,而前人的文章只针对二元反应模型。
KHB法在有序模型中的应用更加困难。
不仅关注了中介系数,更关注了中介系数的方差。
模拟条件范围更广泛、更困难。
研究结果表明在有序回归模型中,KHB法在很多条件下都表现良好。总体来说KHB法对差分系数的估测偏倚适中,尽管在一些条件下KHB法的性能下降。如果观测到的相对偏倚较大,标准差的估测会变得比较困难。这一结果验证了前人在二元回归模型中得出的结论:斜率估计值的样本方差偏倚通常比斜率估计值本身大。
另外,置信区间覆盖率相对准确:在所有模拟条件下,平均覆盖率为94.7%(名义置信区间为95%)。在估计差分系数和ESE时,样本规模一直都是一个较强的偏倚预测因子,但即使是在n=150的最坏情况下,KHB法仍表现良好。
综上所示,使用KHB的研究人员可以合理假设它近似原本参数。
另:Stata命令(Kohler, U., Karlson, K. B. and Holm, A., 2011, ‘Comparing Coefficients of Nested Nonlinear Probability Models’)
句法:model-type depvar key-vars || z-vars [if] [in] [weight] [,option]
· model-type: regress, logit, ologit, probit, oprobit, cloglog, slogit, scobit, rologit, clogit, mlogit, xtlogit, xtprobit中任意。
· depvar:因变量
· key-vars: 包含要分解的变量名的变量列表,可能包括因子变量
· z-vars:包含感兴趣的控制变量名称的变量列表,可能包括因子变量
· weight:aweight, fweight, pweight都可以,只要该model-type允许
选项: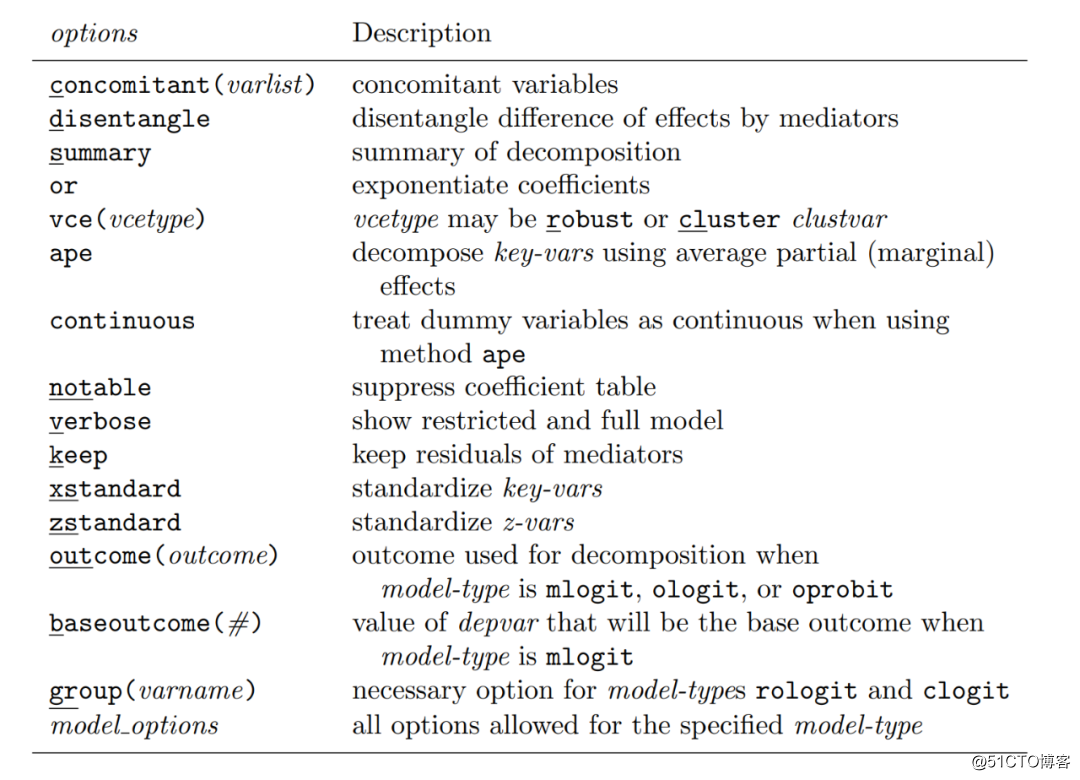
· concomitant(varlist):非中介变量的控制变量,可以是因子变量
· disentangle:请求一个表格以显示每个z-var在完整模型和简化模型之间的差异
· summary:请求一个所有key-vars的分解总结。默认情况下,KHB会报告完整模型和简化模型的影响、它们的差异及标准方差。使用summary选项,KHB还会显示一个表,其中包括混杂百分比、由于混杂而减少的百分比以及重缩放因子。混杂比例计算了confounding net of rescaling的影响,百分比减少量计算了每一个key-var系数有confounding net of rescaling引起的百分比变化,重缩放因子计算了rescaling net of confounding。
· or: 对估计系数取幂,从而表示logit模型的让步比。
· vce(vcetype):标准差的形式。标准差的默认值为制定model-type的Stata默认值。间接影响的标准差则是通过Sobel(1982)提出的模型进行估测的。这一选项设置了简化模型和完整模型的标准差,且控制了进入Sobel法的标准差种类。robust和cluster可以使用。
· ape:使用平均部分效应分解key-vars。对于连续X,这是预测概率对X的导数的平均值;对于离散X,这是离散差的平均值。对于ologit和oprobit模型,除非给定outcome(),KHB只会对第一个结果的概率使用平均部分分解效应。使用ape选项,计算得出的差异不随结果保持一致。
· continuous:认为虚变量也是连续变量。默认情况下,平均部分效应基于虚变量的单位影响。
· notable:阻止系数表格的出现。通常包括了summarize或者disentangle选项。
· verbose:显示用于估计分解的完整和受限模型的完整结果。这对于检测在估算过程中出现的问题特别有用。
· keep:保留中介变量的残差,即中介变量的混杂。在简化模型中,这些残差被涵盖在自变量里。
· xstandard:用来标准化key-vars。
· zstandard:用来标准化z-vars。
· outcome( ):指定计算分解的结果。对多响应模型(mlogit)和使用ape选项的有序反应模型(ologit, oprobit)有影响。具体用法:
· baseoutcome(#):和mlogit的model-type一起使用。这一选项指定了depvar的值为基础结果。默认值为出现频率最多的结果。baseoutcome( )与outcome( )一起使用,可以完全控制分解所做的对比。
· group(varname):对于rologit和clogit的model-type而言时比哟啊的选项
· model_options:该model-type允许所有选项。
Reference: Kohler, U., Karlson, K. B., & Holm, A. (2011). Comparing Coefficients of Nested Nonlinear Probability Models. The Stata Journal, 11(3), 420–438. https://doi.org/10.1177/1536867X1101100306
关于一些计量方法的合辑,各位学者可以参看如下文章:①“实证研究中用到的200篇文章, 社科学者常备toolkit”、②实证文章写作常用到的50篇名家经验帖, 学者必读系列、③过去10年AER上关于中国主题的Articles专辑、④AEA公布2017-19年度最受关注的十大研究话题, 给你的选题方向,⑤2020年中文Top期刊重点选题方向, 写论文就写这些,⑥过去三十年, RCT, DID, RDD, LE, ML, DSGE等方法的“高光时刻”路线图。后面,咱们又引荐了①使用CFPS, CHFS, CHNS数据实证研究的精选文章专辑!,②这40个微观数据库够你博士毕业了, 反正凭着这些库成了教授,③Python, Stata, R软件史上最全快捷键合辑!,④关于(模糊)断点回归设计的100篇精选Articles专辑!,⑤关于双重差分法DID的32篇精选Articles专辑!,⑥关于合成控制法SCM的33篇精选Articles专辑!⑦最近80篇关于中国国际贸易领域papers合辑!,⑧最近70篇关于中国环境生态的经济学papers合辑!⑨使用CEPS, CHARLS, CGSS, CLHLS数据库实证研究的精选文章专辑!⑩最近50篇使用系统GMM开展实证研究的papers合辑!
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
2.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
©著作权归作者所有:来自51CTO博客作者mb5fd86dae5fbf6的原创作品,如需转载,请注明出处,否则将追究法律责任