
Spark 3.0新特性在FreeWheel核心业务数据团队的应用与实战
Spark 3.0新特性在FreeWheel核心业务数据团队的应用与实战
引 言
相信作为 Spark 的粉丝或者平时工作与 Spark 相关的同学大多知道,Spark 3.0 在 2020 年 6 月官方重磅发布,并于 9 月发布稳定线上版本,这是 Spark 有史以来最大的一次 release,共包含了 3400 多个 patches,而且恰逢 Spark 发布的第十年,具有非常重大的意义。
团队在 Spark 发布后,快速动手搭好 Spark 3.0 的裸机集群并在其上进行了初步的调研,发现相较于 Spark 2.x 确实有性能上的提升。于是跟 AWS EMR 和 Support 团队进行了多次沟通表达我们的迫切需求后,EMR 团队给予了快速的响应,在 11 月底发布了内测版本。作为第一批内测用户,我们做了 Data Pipelines 上各个模块的升级,测试和数据验证。团队通过高效的敏捷开发赶在 2020 年圣诞广告季之前在生产环境顺利发布上线,整体 性能提升高达 40%(对于大 batch)的数据,AWS Cost 平均节省 25%~30% 之间,大约每年至少能为公司节省百万成本。目前线上稳定运行,预期借助此次升级能够更从容地为 FreeWheel 高速增长业务量和数据分析需求保驾护航。
在这次 Spark 3.0 的升级中,其实并不是一个简简单单的版本更换,因为团队的 Data Pipelines 所依赖的生态圈本质上其实也发生了一个很大的变化。比如 EMR 有一个大版本的升级,从 5.26 升级到最新版 6.2.0,底层的 Hadoop 也从 2.x 升级到 3.2.1,Scala 只能支持 2.12 等等。本篇文章主要是想和大家分享一下 Spark 3.0 在 FreeWheel 大数据团队升级背后的故 (xuè) 事 (lèi) 和相关的实战经验,希望能对大家以后的使用 Spark 3.0 特别是基于 AWS EMR 上开发有所帮助,可以在 Spark 升级的道路上走的更顺一些。
团队介绍
FreeWheel 核心业务数据团队的主要工作是通过收集,分析来自用户的视频广告数据,来帮助客户更好地制定广告计划,满足客户不断增长的业务需求,最终帮助客户实现业务的增长。其中最主要的两类数据分别是预测数据和历史数据:
预测数据 会根据用户历史广告投放情况进行算法分析和学习来得到未来预测情况,在此基础上向客户提供有价值的数据分析结果,比如广告投放是否健康,广告位是否足够,当前的广告售卖是否合理等等信息。通过这些数据分析的反馈可以帮助用户更好地在广告定价、售期等方面做出正确的决定,最终达到自己的销售目标。
历史数据 主要是提供用户业务场景数据分析所需要的功能,比如数据查询,Billing 账单,广告投放情况,市场策略等,并且通过大量的历史数据从多维度多指标的角度提供强有力的 BI 分析能力进而帮助用户洞察数据发生的变化,发现潜在的问题和市场机会。
作为核心业务数据团队里重要的成员,Transformer 团队的主要负责:
基于大数据平台技术建立 Data Pipelines
负责将交易级别的数据转化为分析级别的数据,服务下游所有的数据产品
构建统一的数据仓库
通过分层业务模型来构建所有数据产品不同场景下(历史或者预测)使用一致的业务视图和指标
提供不同粒度或者维度的聚合事实数据
提供基于特定场景的数据集市
提供统一的数据发布服务和接口
数据建模和 Data Pipelines 架构
当交易级别的广告(历史或者预测)数据进入系统后,会通过数据建模和 Data Pipelines 进行统一的建模或者分析,视业务需要更进一步构建数据集市,生成的聚合事实数据会被发布到数据仓库 Hive 和 Clickhouse 里供下游数据产品通过 Presto 或者 Clickhouse 查询引擎来消费。如下是整体建模和 Data Pipelines 的架构图:
其中主要模块包括:
Optimus
正如它的名字一样,Optimus 同样是 Transformer 团队的模块中的领袖人物,肩负业务数据团队最重要的数据建模部分。通过分层数据建模的方式来构建统一的基于上下文的数据模型,保障所有下游产品在不同的应用和业务场景下的计算指标,计算逻辑一致,且避免来回重复计算扫描数据。比如预测数据和历史数据同样的指标含义,就使得提供给客户的数据对比更有说服力和决策指导意义。目前它会产生将近四十张左右的小时粒度的历史事实表和预测事实表。目前每天处理的数据在 TB 级别,会根据每个小时的数据量自动进行扩或者缩集群,保证任务的高性能同时达到资源的高效利用目标。
JetFire
JetFire 是一个基于 Spark 的通用 ETL 框架,支持用户通过 SQL 或者 Code 的方式灵活的定制 ETL 任务和分析数据任务。目前主要用于 Post-Optimus 的场景,生成基于特定业务场景更高聚合粒度的数据集市上。比如生成 todate(迄今为止) 的统计指标,像每个客户截止到目前或者过去 18 个月的广告投放总数。这样就可以避免每次查询对底层数据或者 Optimus 生成的聚合数据进行全扫。生成一次供多次查询,可以极大提高查询效率,降低成本。
Publisher
基于 Spark 的数据发布模块,负责将数据发布到数据仓库里。由于数据建模产生的数据按日期进行分区,当存在 Late Data 的时候,很容易生成碎小文件,Publisher 通过发布数据前合并碎小文件的功能来提升下游的查询效率。
Bumblebee
主要是为数据建模和 Data Pipelines 的各个模块提供模块测试和集成测试环境,供业务开发的同学使用。此外,基于此提供所有 Data Pipelines 的整体一致的 CD 和灾备方案,保障在极端场景下系统的快速启动和恢复。
Data Restatement
除了日常的 Data Pipelines,在客户数据投放出现问题或者数据仓库数据出现偏差遗漏时,需要自动修数据的 Pipelines 来支持大范围的数据修正和补偿。整体的作业调度需要保证日常工作正常完成的情况下,尽快完成数据修正工作。目前提供整个 batch 或者 delta 两种方式修数据,来满足不同的应用场景。
Data Publish API
负责为下游提供数据发布信息,来触发一些订阅的报表或者产品发布。
除了 Data Publish API 服务部署在 EKS 上,其他相关模块目前都运行在 AWS EMR 上,灵活使用 Spot Instance 和 On Demand 混合模式,高效利用资源。团队基于以上的模块为公司的业务发展提供有力的数据和技术保障。
实践成果
这次升级主要的实践成果如下:
性能提升明显
历史数据Pipeline 对于大 batch 的数据(200~400G/ 每小时)性能提升高达 40%, 对于小 batch(小于 100G/ 每小时)提升效果没有大 batch 提升的那么明显,每天所有 batches 平均提升水平 27.5% 左右。
预测数据 性能平均提升 30%。由于数据输入源不一样,目前是分别两个 pipelines 在跑历史和预测数据,产生的表的数目也不太一样,因此做了分别的评估。
以历史数据上线后的端到端到运行时间为例(如下图),肉眼可见上线后整体 pipeline 的运行时间有了明显的下降,能够更快的输出数据供下游使用。
集群内存使用降低
集群内存使用对于大 batch 达降低 30% 左右,每天平均平均节省 25% 左右。
以历史数据上线后的运行时集群的 memory 在 ganglia 上的截图为例(如下图),整体集群的内存使用从 41.2T 降到 30.1T,这意味着我们可以用更少的机器花更少的钱来跑同样的 Spark 任务。
AWS Cost 降低
Pipelines 做了自动的 Scale In/Scale Out 策略: 在需要资源的时候扩集群的 Task 结点,在任务结束后自动去缩集群的 Task 结点,且会根据每次 batch 数据的大小通过算法学习得到最佳的机器数。通过升级到 Spark 3.0 后,由于现在任务跑的更快并且需要的机器更少,上线后统计 AWS Cost 每天节省 30% 左右,大约一年能为公司节省百万成本。
如下是历史数据 Pipeline 上线后,通过 AWS Billing 得到的账单 Cost 数据,可以看到在使用 Spot Instance 情况下 (花费柱状图较短的情况下) 从上线前 (蓝色线) 到上线后 (红色线) 每天有显著的 30% 左右的成本下降, 如果使用 AWS On Demand 的 Instance 的话那么节省就更可观了。
其他
Data Pipelines 里的所有的相关模块都完成了 Spark 3.0 的升级,享受最新技术栈和优化带来的收益。
由于任务运行时间和需要的机器数明显下降,整体的 Spot Instance 被中断的概率也大大降低,任务稳定性得到加强。
发布了自动化数据验证工具进行端到端的数据验证。
统一并升级了所有模块的 CD Pipelines。
接下来我们具体看看我们做了什么,又踩了什么样的坑,以及背后有什么魔法帮助达到既让任务跑得快又能为公司省钱的效果。对 Spark 3.0 新特性感兴趣的同学可以参考我的另外一篇文章——关于 Spark 3.0 的关键新特性回顾:https://xie.infoq.cn/article/fad821a83e19c6478458e0b03
我们做了什么?遇到什么坑?
Data Pipelines 和相关的回归测试框架都进行相关依赖生态圈的统一升级,接下来会跟大家详细分享细节部分。
Spark 升级到最新稳定版 3.0.1
Spark 3.0.1 是社区目前推荐使用的最新的稳定版本,于 2020 年九月正式发布,其中解决了 3.0 版本里的一些潜在 bug。
主要的改动
打开 Spark 3.0 AQE 的新特性
主要配置如下:
"spark.sql.adaptive.enabled": true,
"spark.sql.adaptive.coalescePartitions.enabled": true,
"spark.sql.adaptive.coalescePartitions.minPartitionNum": 1,
"spark.sql.adaptive.advisoryPartitionSizeInBytes": "128MB"
需要注意的是,AQE 特性只是在 reducer 阶段不用指定 reducer 的个数,但 并不代表你不再需要指定任务的并行度了。因为 map 阶段仍然需要将数据划分为合适的分区进行处理,如果没有指定并行度会使用默认的 200,当数据量过大时,很容易出现 OOM。建议还是按照任务之前的并行度设置来配置参数 spark.sql.shuffle.partitions 和 spark.default.parallelism。
升级 HyperLogLog 相关的 UDAF 到新接口
Spark 3.0 提供了通过用户定制实现的 Aggregator 来注册实现 UDAF,可以避免对每一行的数据反复进行序列化和反序列化来进行聚合,而只需在整个分区里序列化一次 ,缓解了对 cpu 的压力,提升性能。假如一个 DataFrame 有 100 万行数据共 10 个 paritions,那么旧的 UDAF 方式的序列化反序列化需要至少 100 万 +10 次 (合并分区里的结果)。而新的函数只需要 10 次即可,大大减少整体的序列化操作。
依赖 Hadoop 版本升级
依赖的 Hadoop 根据 Spark 和 EMR 支持的版本升级到 3.2.1
ext {
hadoopVersion = "3.2.1"
}
compile group: "org.apache.hadoop", name: "hadoop-client", version: "${hadoopVersion}"
打开 History Server Event Logs 滚动功能
Spark 3.0 提供了类似 Log4j 那样对于长时间运行的日志按照时间或者文件的大小进行切割,这样对于 Streaming 长期运行的任务和大任务来说比较友好。
"spark.eventLog.rolling.enabled": true,
"spark.eventLog.rolling.maxFileSize": "1024m",
"spark.eventLog.buffer.kb": "10m"
遇到的坑
读 Parquet 文件失败
升级到 Spark 3.0 后,读源数据 Parquet 文件会出现一些莫名的问题,有些文件可以正常解析,而有些文件则会抛出失败的异常错误,这个错误是整个升级的 Blocker,非常令人苦恼。
具体的错误信息
org.apache.spark.sql.execution.QueryExecutionException: Encounter error while reading parquet files. One possible cause: Parquet column cannot be converted in the corresponding files.
原因
在仔细调试和阅读源码后发现,Spark 3.0 在 Parquet 的嵌套 schema 的逻辑上做了修改,主要是关于使用的优化特性 spark.sql.optimizer.nestedSchemaPruning.enabled 时的变化,具体可以进一步阅读相关的 ticket。
而产生的影响就是当在有嵌套 schema 的 Parquet 文件上去读取不存在的 field 时,会抛出错误。而在 2.4 以前的版本是,是允许访问不存在的 field 并返回 none,并不会中断整个程序。
解决办法
由于我们数据建模和上游开发模式就是面向接口编程,为了不和 schema 严格绑定,是会存在提前读取一些暂时还没有上线的 field 并暂时存放空值。因此,新的逻辑修改直接就 break 了原来的开发模式, 而且代码里也要加入各种兼容老的 schema 逻辑。
于是我们将优化 spark.sql.optimizer.nestedSchemaPruning.enabled 会关掉后,再进行性能的测试,发现性能的影响几乎可以忽略。
鉴于上面的影响太大和性能测试结果,最终选择设置 spark.sql.optimizer.nestedSchemaPruning.enabled = false。后续会进一步研究是否有更优雅的解决方式。
History Server 的 Connection Refused
Spark 3.0 里 History Server 在解析日志文件由于内存问题失败时, History Server 会重启,随后会出现 Connection Refused 的错误信息,而在 2.x 里,并不会导致整个 History Server 的重启。
解决方案
增加 History Server 的内存。在 Master 结点, Spark 配置文件里修改:
export SPARK_DAEMON_MEMORY=12g
然后重启 History Server 即可 sudo systemctl restart spark-history-server
History UI 显示任务无法结束
原因
打开 AQE 后由于会对整个查询进行再次切分,加上 3.0 也会增加很多相关 Observable 的指标,比如 Shuffle,所以整体的 History Logs 会变的相对较大,目前对于某些 batch 的任务产生的 logs 无法及时同步到 History Server 里,导致从 History UI 去看任务执行进度时会存在一直在 in progress 状态,但实际上任务已经执行完毕。
在阅读源码和相关 Log 后,比较怀疑是 Spark Driver 在 eventLoggingListerner 向升级后的 HDFS(Hadoop 3.2.1) 写 eventlogs 时出了什么问题,比如丢了对应事件结束的通知信息。由于源码里这部分 debugging 相关的 Log 信息相对有限,还不能完全确定根本原因,后续会再继续跟进这个问题。
其实类似的问题在 Spark 2.4 也偶有发生,但升级到 3.0 后似乎问题变得频率高了一些。遇到类似问题的同学可以注意一下,虽然 Logs 信息不全,但任务的执行和最终产生的数据都是正确的。
HDFS 升级后端口发生变化
端口号变化列表:
Namenode 端口: 50470 –> 9871, 50070 –> 9870, 8020 –> 9820
Secondary NN 端口: 50091 –> 9869, 50090 –> 9868
Datanode 端口: 50020 –> 9867, 50010 –> 9866, 50475 –> 9865, 50075 –> 9864
EMR 升级到最新版 6.2.0 系统升级
EMR 6.2.0 使用的操作系统是更好 Amazon Linux2,整体系统的服务安装和控制从直接调用各个服务自己的起停命令 (原有的操作系统版本过低) 更换为统一的 Systemd。
启用 Yarn 的结点标签
在 EMR 的 6.x 的发布里,禁用了 Yarn 的结点标签功能,相较于原来 Driver 强制只能跑在 Core 结点上,新的 EMR 里 Driver 可以跑在做任意结点,细节可以参考文档。而由于我们的 Data Pipelines 需要 EMR 的 Task 节点按需进行扩或者缩,而且用的还是 Spot Instance。因此这种场景下 Driver 更适合跑在常驻的 (On Demand) 的 Core 结点上,而不是随时面临收回的 Task 节点上。对应的 EMR 集群改动:
yarn.node-labels.enabled: true
yarn.node-labels.am.default-node-label-expression: 'CORE'
Spark Submit 命令的修改
在 EMR 新的版本里用 extraJavaOptions 会报错,这个和 EMR 内部的设置有关系,具体详情可以参考 EMR 配置 ,修改如下:
spark.executor.extraJavaOptions=-XX-> spark.executor.defaultJavaOptions=-XX:+UseG1GC
遇到的坑
Hive Metastore 冲突
原因
EMR 6.2.0 里内置的 Hive Metastore 版本是 2.3.7,而公司内部系统使用的目前版本是 1.2.1,因此在使用新版 EMR 的时候会报莫名的各种包问题,根本原因就是使用的 Metastore 版本冲突问题。
错误信息示例:
User class threw exception: java.lang.RuntimeException: [download failed: net.minidev#accessors-smart;1.2!accessors-smart.jar(bundle), download failed: org.ow2.asm#asm;5.0.4!asm.jar, download failed: org.apache.kerby#kerb-core;1.0.1!kerb-core.jar, download failed: org.apache.kerby#kerb-server;1.0.1!kerb-server.jar, download failed: org.apache.htrace#htrace-core4;4.1.0-incubating!htrace-core4.jar, download failed: com.fasterxml.jackson.core#jackson-databind;2.7.8!jackson-databind.jar(bundle), download failed: com.fasterxml.jackson.core#jackson-core;2.7.8!jackson-core.jar(bundle), download failed: javax.xml.bind#jaxb-api;2.2.11!jaxb-api.jar, download failed: org.eclipse.jetty#jetty-util;9.3.19.v20170502!jetty-util.jar, download failed: com.google.inject#guice;4.0!guice.jar, download failed: com.sun.jersey#jersey-server;1.19!jersey-server.jar]
解决方案
初始方案:
"spark.sql.hive.metastore.version": "1.2.1",
"spark.sql.hive.metastore.jars": "maven"
但初始方案每次任务运行时都需要去 maven 库里下载,比较影响性能而且浪费资源,当多任务并发去下载的时候会出问题,并且官方文档不建议在生产环境下使用。因此将 lib 包的下载直接打入镜像里,然后启动 EMR 集群的时候加载一次到 /dependency_libs/hive/* 即可,完善后方案为:
"spark.sql.hive.metastore.version": "1.2.1",
"spark.sql.hive.metastore.jars": "/dependency_libs/hive/*"
Hive Server 连接失败
错误信息
Caused by: org.apache.thrift.TApplicationException: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=default})
原因
和 Hive metastore 包冲突类似的问题,由于 Spark 3.0 里用的 hive-jdbc.jar 包版本过高。
解决方案
下载可用的对应的 lib 包,将 Spark 3.0 里自带的 hive-jdbc.jar 包进行替换。
wget -P ./ https://github.com/timveil/hive-jdbc-uber-jar/releases/download/v1.8-2.6.3/hive-jdbc-uber-2.6.3.0-235.jar
写 HDFS 数据偶尔会失败
在最新版的 EMR 集群上跑时,经常会出现写 HDFS 数据阶段失败的情况。查看 Log 上的 error 信息:
Spark Log
Spark Log:
Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hadoop/output/20201023040000/tablename/normal/_temporary/0/_temporary/attempt_20201103002533_0146_m_001328_760289/event_date=2020-10-22 03%3A00%3A00/part-01328-7c2e85a0-dfc8-4d4d-8d49-ed9b6aca06f6.c000.zlib.orc could only be written to 0 of the 1 minReplication nodes. There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
HDFS Data Node Log
Data Node Log:
365050 java.io.IOException: Xceiver count 4097 exceeds the limit of concurrent xcievers: 4096
365051 at org.apache.hadoop.hdfs.server.datanode.DataXceiverServer.run(DataXceiverServer.java:150)
365052 at java.lang.Thread.run(Thread.java:748)
解决方案:调大对应的 HDFS 连接数。
dfs.datanode.max.transfer.threads = 16384
不确定 EMR 集群在升级的过程中是否修改过 HDFS 连接数的默认参数。
Scala 升级到 2.12
由于 Spark 3.0 不再支持 Scala 2.11 版本,需要将所有的代码升级到 2.12 的版本。更多 Scala 2.12 的新的发布内容可以参考文档。
语法升级
JavaConversions 被 deprecated 了,需要用 JavaConverters 并且显示调用.asJava 或者.asScala 的转化
并发开发相关接口发生变化 Scala.concurrent.Future
周边相关依赖包升级
包括但不限于 scalstest, scalacheck, scalaxml 升级到 2.12 对应的版本
其他相关调整
集群资源分配算法调整
整体使用的集群内存在升级 3.0 后有明显的降低,Data Pipelines 根据新的资源需用量重新调整了根据文件大小计算集群资源大小的算法。
Python 升级到 3.x
为什么既能提升性能又能省钱?
我们来仔细看一下为什么升级到 3.0 以后可以减少运行时间,又能节省集群的成本。以 Optimus 数据建模里的一张表的运行情况为例:
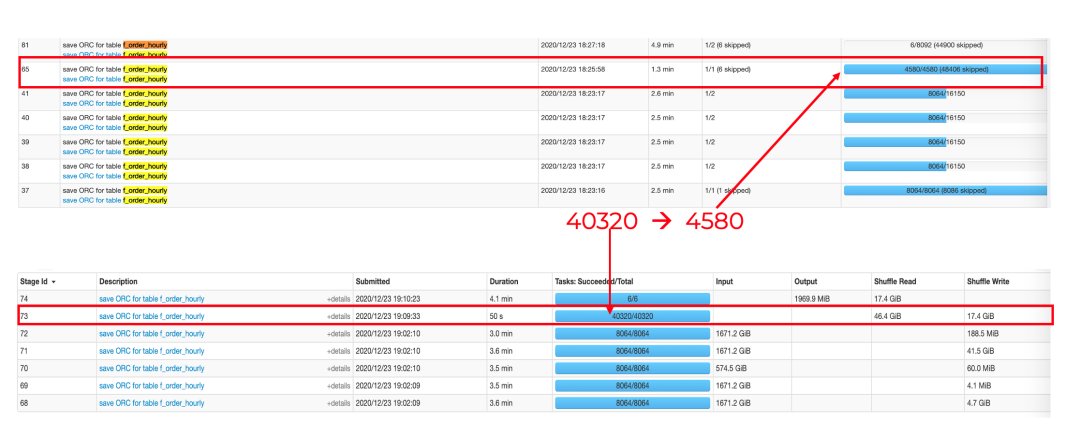
在 reduce 阶段从没有 AQE 的 40320 个 tasks 锐减到 4580 个 tasks,减少了一个数量级。
下图里下半部分是没有 AQE 的 Spark 2.x 的 task 情况,上半部分是打开 AQE 特性后的 Spark 3.x 的情况。
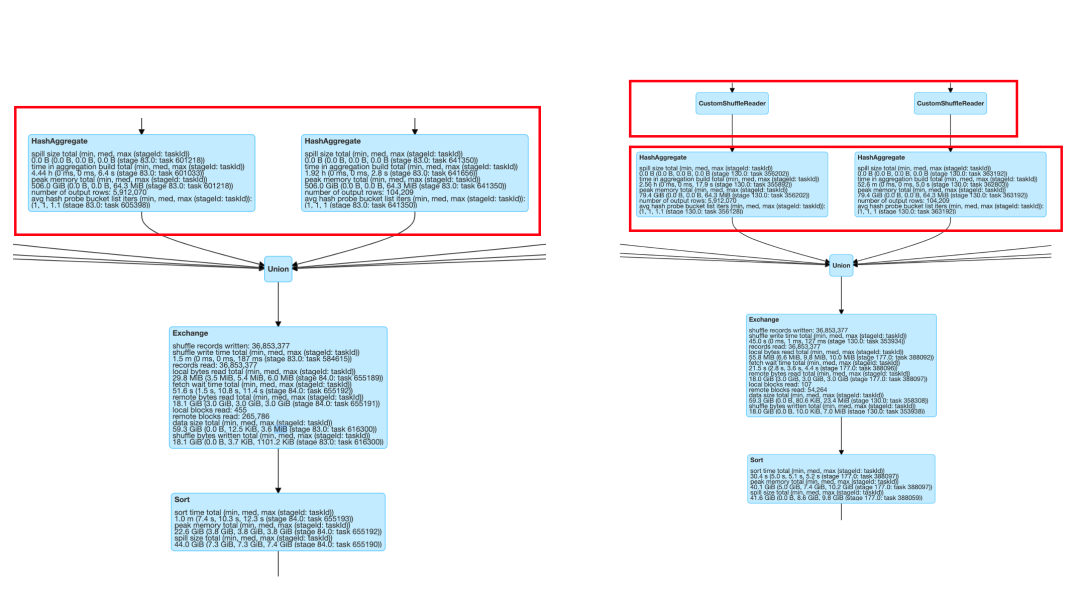
从更详细的运行时间图来看,shuffler reader 后同样的 aggregate 的操作等时间也从 4.44h 到 2.56h,节省将近一半。
左边是 spark 2.x 的运行指标明细,右边是打开 AQE 后通过 custom shuffler reader 后的运行指标情况。
原因分析:
AQE 特性:
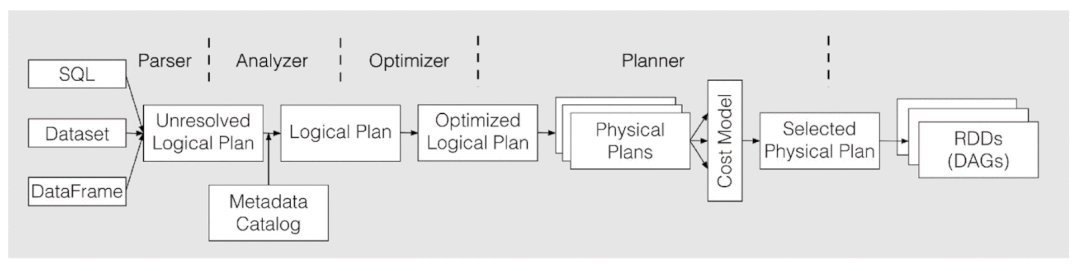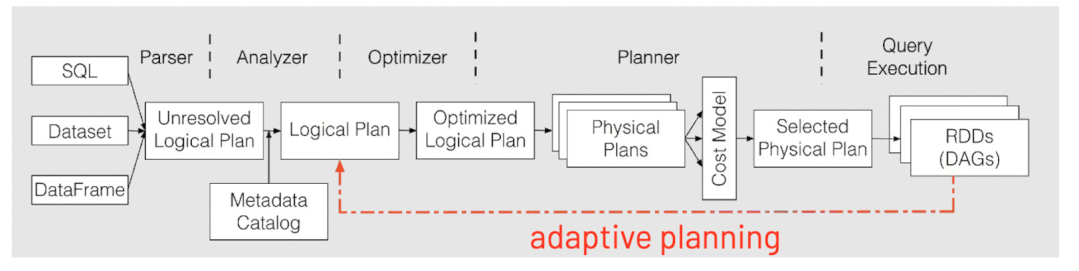
AQE 对于整体的 Spark SQL 的执行过程做了相应的调整和优化 (如下图),它最大的亮点是可以根据已经完成的计划结点真实且精确的执行统计结果来不停的反馈并重新优化剩下的执行计划。
AQE 自动调整 reducer 的数量,减小 partition 数量。Spark 任务的并行度一直是让用户比较困扰的地方。如果并行度太大的话,会导致 task 过多,overhead 比较大,整体拉慢任务的运行。而如果并行度太小的,数据分区会比较大,容易出现 OOM 的问题,并且资源也得不到合理的利用,并行运行任务优势得不到最大的发挥。
而且由于 Spark Context 整个任务的并行度,需要一开始设定好且没法动态修改,这就很容易出现任务刚开始的时候数据量大需要大的并行度,而运行的过程中通过转化过滤可能最终的数据集已经变得很小,最初设定的分区数就显得过大了。AQE 能够很好的解决这个问题,在 reducer 去读取数据时,会根据用户设定的分区数据的大小 (spark.sql.adaptive.advisoryPartitionSizeInBytes) 来自动调整和合并 (Coalesce) 小的 partition,自适应地减小 partition 的数量,以减少资源浪费和 overhead,提升任务的性能。
由上面单张表可以看到,打开 AQE 的时候极大的降低了 task 的数量,除了减轻了 Driver 的负担,也减少启动 task 带来的 schedule,memory,启动管理等 overhead,减少 cpu 的占用,提升的 I/O 性能。
拿历史 Data Pipelines 为例,同时会并行有三十多张表在 Spark 里运行,每张表都有极大的性能提升,那么也使得其他的表能够获得资源更早更多,互相受益,那么最终整个的数据建模过程会自然而然有一个加速的结果。
大 batch(>200G)相对小 batch(<100G)有比较大的提升,有高达 40% 提升,主要是因为大 batch 本身数据量大,需要机器数多,设置并发度也更大,那么 AQE 展现特性的时刻会更多更明显。而小 batch 并发度相对较低,那么提升也就相对会少一些,不过也是有 27.5% 左右的加速。
内存优化
除了因为 AQE 的打开,减少过碎的 task 对于 memory 的占用外,Spark 3.0 也在其他地方做了很多内存方面的优化,比如 Aggregate 部分指标瘦身(Ticket)、Netty 的共享内存 Pool 功能 (Ticket)、Task Manager 死锁问题 (Ticket)、避免某些场景下从网络读取 shuffle block(Ticket) 等等,来减少内存的压力。一系列内存的优化加上 AQE 特性叠加从前文内存实践图中可以看到集群的内存使用同时有 30% 左右的下降。
Data Pipelines 里端到端的每个模块都升级到 Spark 3.0,充分获得新技术栈带来的好处。
综上所述,Spark 任务得到端到端的加速 + 集群资源使用降低 = 提升性能且省钱。
未来展望
接下来,团队会继续紧跟技术栈的更新,并持续对 Data Pipelines 上做代码层次和技术栈方面的调优和贡献,另外会引入更多的监控指标来更好的解决业务建模中可能出现的数据倾斜问题,以更强力的技术支持和保障 FreeWheel 正在蓬勃发展的业务。
最后特别感谢 AWS EMR 和 Support 团队在升级的过程中给予的快速响应和支持。
©著作权归作者所有:来自51CTO博客作者mb5fdb0a1b25659的原创作品,如需转载,请注明出处,否则将追究法律责任