
FASTQ格式详解
简介
FASTQ是基于文本的,保存生物序列(通常是核酸序列)和其测序质量信息的标准格式。其序列以及质量信息都是使用一个ASCII字符标示,最初由Sanger开发,目的是将FASTA序列与质量数据放到一起,目前已经成为高通量测序结果的事实标准。
1 格式说明
FASTQ文件中每个序列通常有四行:
序列标识以及相关的描述信息,以‘@’开头;
第二行是序列
第三行以‘+’开头,后面是序列标示符、描述信息,或者什么也不加
第四行,是质量信息,和第二行的序列相对应,每一个序列都有一个质量评分,根据评分体系的不同,每个字符的含义表示的数字也不相同。
例如:
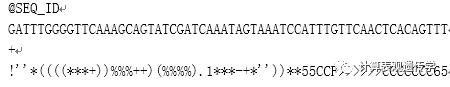

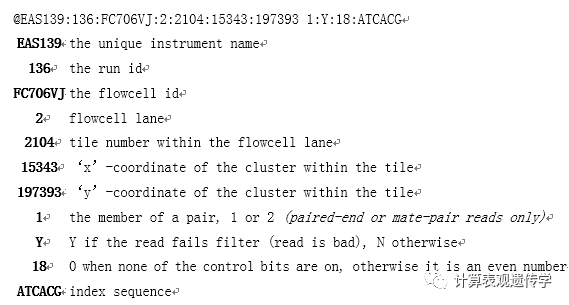

1 关于质量编码格式
质量评分指的是一个碱基的错误概率的对数值。其最初在Phred拼接软件中定义与使用,其后在许多软件中得到使用。其质量得分与错误概率的对应关系见下表:

除了Phred质量得分换算标准,还有就是Solexa标准:
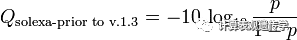
两种换算标准的比较:
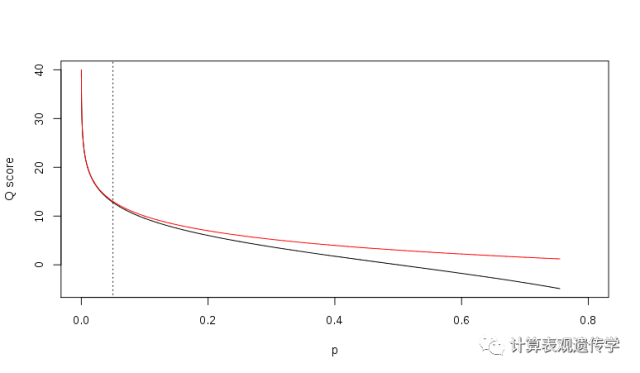
Relationship between Q and p using the Sanger (red)and Solexa (black) equations (described above). The vertical dotted lineindicates p = 0.05, or equivalently, Q ≈ 13.
对于每个碱基的质量编码标示,不同的软件采用不同的方案,目前有5种方案:
Sanger,Phred quality score,值的范围从0到92,对应的ASCII码从33到126,但是对于测序数据(raw read data)质量得分通常小于60,序列拼接或者mapping可能用到更大的分数。
Solexa/Illumina 1.0, Solexa/Illumina quality score,值的范围从-5到63,对应的ASCII码从59到126,对于测序数据,得分一般在-5到40之间;
Illumina 1.3+,Phred quality score,值的范围从0到62对应的ASCII码从64到126,低于测序数据,得分在0到40之间;
Illumina 1.5+,Phred quality score,但是0到2作为另外的标示,详见http://solexaqa.sourceforge.net/questions.htm#illumina
Illumina 1.8+
下面是更为直观的表示:

1 文件后缀
没有特别的规定,通常使用.fq, .fastq, .txt等。
A FASTQ file normally uses four lines per sequence.Line 1 begins with a '@' character and is followed by a sequence identifier andan optional description (like a FASTA title line). Line 2 is the raw sequence letters. Line3 begins with a '+' character and is optionally followed by the samesequence identifier (and any description) again. Line 4 encodes the qualityvalues for the sequence in Line 2, and must contain the same number of symbolsas letters in the sequence.
FASTQ格式的序列一般都包含有四行,第一行由'@'开始,后面跟着序列的描述信息,这点跟FASTA格式是一样的。第二行是序列。第三行由'+'开始,后面也可以跟着序列的描述信息。第四行是第二行序列的质量评价(qualityvalues,注:应该是测序的质量评价),字符数跟第二行的序列是相等的。
FASTQ格式例子:
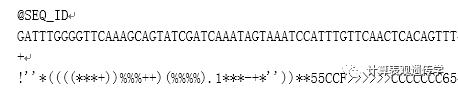
例如在NCBI看到的FASTQ格式如下:
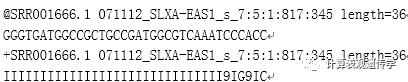
参考链接:
http://en.wikipedia.org/wiki/FASTQ_format
©著作权归作者所有:来自51CTO博客作者mob604756f4ef89的原创作品,如需转载,请注明出处,否则将追究法律责任